Siden oppfinnelsen av datamaskiner har folk brukt begrepet ' Data ' for å referere til datamaskininformasjon, enten overført eller lagret. Det er imidlertid data som også finnes i ordretyper. Data kan være tall eller tekster skrevet på et stykke papir, i form av biter og bytes lagret i minnet til elektroniske enheter, eller fakta lagret i en persons sinn. Etter hvert som verden begynte å modernisere seg, ble disse dataene et viktig aspekt av alles daglige liv, og ulike implementeringer tillot dem å lagre dem annerledes.
Data er en samling av fakta og tall eller et sett med verdier eller verdier av et spesifikt format som refererer til et enkelt sett med elementverdier. Dataelementene blir deretter klassifisert i underelementer, som er gruppen av elementer som ikke er kjent som den enkle primære formen for elementet.
La oss se på et eksempel der et ansattnavn kan deles inn i tre underelementer: First, Middle og Last. Imidlertid vil en ID som er tildelt en ansatt generelt betraktes som en enkelt vare.
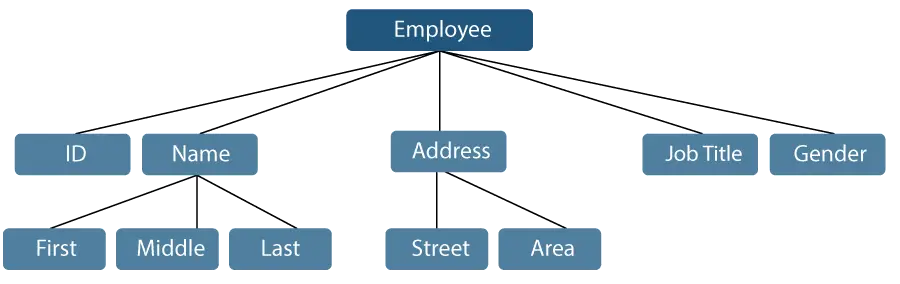
Figur 1: Representasjon av dataelementer
I eksemplet nevnt ovenfor er elementene som ID, Alder, Kjønn, First, Middle, Last, Street, Locality osv. elementære dataelementer. Derimot er navnet og adressen gruppedataelementer.
Hva er datastruktur?
Data struktur er en gren av informatikk. Studiet av datastruktur lar oss forstå organiseringen av data og styringen av dataflyten for å øke effektiviteten til enhver prosess eller program. Datastruktur er en spesiell måte å lagre og organisere data på i datamaskinens minne slik at disse dataene enkelt kan hentes og effektivt brukes i fremtiden når det er nødvendig. Dataene kan administreres på forskjellige måter, som den logiske eller matematiske modellen for en spesifikk organisering av data er kjent som en datastruktur.
Omfanget av en bestemt datamodell avhenger av to faktorer:
- For det første må det lastes nok inn i strukturen til å gjenspeile den definitive korrelasjonen mellom dataene og et objekt i den virkelige verden.
- For det andre bør formasjonen være så enkel at man kan tilpasse seg for å behandle dataene effektivt når det er nødvendig.
Noen eksempler på datastrukturer er Arrays, Linked Lists, Stack, Queue, Trees, etc. Datastrukturer er mye brukt i nesten alle aspekter av informatikk, dvs. kompilatordesign, operativsystemer, grafikk, kunstig intelligens og mange flere.
Datastrukturer er hoveddelen av mange informatikkalgoritmer, da de lar programmererne administrere dataene på en effektiv måte. Den spiller en avgjørende rolle for å forbedre ytelsen til et program eller programvare, siden hovedmålet med programvaren er å lagre og hente brukerens data så raskt som mulig.
Javafx opplæring
Grunnleggende terminologier relatert til datastrukturer
Datastrukturer er byggesteinene i enhver programvare eller ethvert program. Å velge passende datastruktur for et program er en ekstremt utfordrende oppgave for en programmerer.
Følgende er noen grunnleggende terminologier som brukes når datastrukturene er involvert:
| Attributter | ID | Navn | Kjønn | Jobbtittel |
|---|---|---|---|---|
| Verdier | 1234 | Stacey M. Hill | Hunn | Programvareutvikler |
Enheter med lignende attributter danner en Entitetssett . Hvert attributt til et enhetssett har en rekke verdier, settet med alle mulige verdier som kan tilordnes det spesifikke attributtet.
Begrepet 'informasjon' brukes noen ganger for data med gitte attributter for meningsfulle eller behandlede data.
Forstå behovet for datastrukturer
Ettersom applikasjoner blir mer komplekse og datamengden øker hver dag, kan det føre til problemer med datasøk, prosesseringshastighet, håndtering av flere forespørsler og mange flere. Datastrukturer støtter ulike metoder for å organisere, administrere og lagre data effektivt. Ved hjelp av Data Structures kan vi enkelt krysse dataelementene. Datastrukturer gir effektivitet, gjenbrukbarhet og abstraksjon.
Hvorfor bør vi lære datastrukturer?
- Datastrukturer og algoritmer er to av nøkkelaspektene ved informatikk.
- Datastrukturer lar oss organisere og lagre data, mens algoritmer lar oss behandle disse dataene meningsfullt.
- Å lære datastrukturer og algoritmer vil hjelpe oss å bli bedre programmerere.
- Vi vil være i stand til å skrive kode som er mer effektiv og pålitelig.
- Vi vil også kunne løse problemer raskere og mer effektivt.
Forstå målene for datastrukturer
Datastrukturer tilfredsstiller to komplementære mål:
Forstå noen hovedtrekk ved datastrukturer
Noen av de vesentlige egenskapene til datastrukturer er:
Klassifisering av datastrukturer
En datastruktur leverer et strukturert sett med variabler relatert til hverandre på ulike måter. Det danner grunnlaget for et programmeringsverktøy som angir forholdet mellom dataelementene og lar programmerere behandle dataene effektivt.
Vi kan klassifisere datastrukturer i to kategorier:
- Primitiv datastruktur
- Ikke-primitiv datastruktur
Følgende figur viser de forskjellige klassifiseringene av datastrukturer.

Figur 2: Klassifikasjoner av datastrukturer
Primitive datastrukturer
- Disse datastrukturene kan manipuleres eller betjenes direkte av instruksjoner på maskinnivå.
- Grunnleggende datatyper som Heltall, flytende, tegn , og boolsk kommer inn under de primitive datastrukturene.
- Disse datatypene kalles også Enkle datatyper , da de inneholder tegn som ikke kan deles videre
Ikke-primitive datastrukturer
- Disse datastrukturene kan ikke manipuleres eller betjenes direkte av instruksjoner på maskinnivå.
- Fokuset til disse datastrukturene er å danne et sett med dataelementer som er enten homogen (samme datatype) eller heterogen (ulike datatyper).
- Basert på strukturen og arrangementet av data, kan vi dele disse datastrukturene inn i to underkategorier -
- Lineære datastrukturer
- Ikke-lineære datastrukturer
Lineære datastrukturer
En datastruktur som bevarer en lineær forbindelse mellom dataelementene er kjent som en lineær datastruktur. Ordningen av dataene gjøres lineært, der hvert element består av etterfølgerne og forgjengerne bortsett fra det første og det siste dataelementet. Det er imidlertid ikke nødvendigvis sant når det gjelder minne, siden arrangementet kanskje ikke er sekvensielt.
Basert på minneallokering er de lineære datastrukturene videre klassifisert i to typer:
De Array er det beste eksemplet på den statiske datastrukturen siden de har en fast størrelse, og dataene kan endres senere.
Koblede lister, stabler , og Haler er vanlige eksempler på dynamiske datastrukturer
Typer lineære datastrukturer
Følgende er listen over lineære datastrukturer som vi vanligvis bruker:
gimp erstatte farge
1. Matriser
An Array er en datastruktur som brukes til å samle flere dataelementer av samme datatype til én variabel. I stedet for å lagre flere verdier av samme datatyper i separate variabelnavn, kan vi lagre dem alle sammen til én variabel. Denne setningen innebærer ikke at vi må forene alle verdiene av samme datatype i et hvilket som helst program til en matrise av den datatypen. Men det vil ofte være tider når noen spesifikke variabler av samme datatyper alle er relatert til hverandre på en måte som passer for en matrise.
En Array er en liste over elementer der hvert element har en unik plass i listen. Dataelementene i matrisen deler samme variabelnavn; hver har imidlertid et forskjellig indeksnummer kalt et subscript. Vi kan få tilgang til et hvilket som helst dataelement fra listen ved hjelp av plasseringen i listen. Derfor er nøkkelfunksjonen til arrayene å forstå at dataene er lagret i sammenhengende minneplasseringer, noe som gjør det mulig for brukerne å gå gjennom dataelementene i arrayen ved å bruke deres respektive indekser.

Figur 3. En matrise
Matriser kan klassifiseres i forskjellige typer:
Noen applikasjoner av Array:
- Vi kan lagre en liste over dataelementer som tilhører samme datatype.
- Array fungerer som et hjelpelager for andre datastrukturer.
- Arrayen hjelper også med å lagre dataelementer i et binært tre med det faste antallet.
- Array fungerer også som en lagring av matriser.
2. Koblede lister
EN Koblet liste er et annet eksempel på en lineær datastruktur som brukes til å lagre en samling av dataelementer dynamisk. Dataelementer i denne datastrukturen er representert av nodene, koblet sammen ved hjelp av lenker eller pekere. Hver node inneholder to felt, informasjonsfeltet består av de faktiske dataene, og pekerfeltet består av adressen til de påfølgende nodene i listen. Pekeren til den siste noden i den koblede listen består av en null-peker, siden den peker til ingenting. I motsetning til Arrays, kan brukeren dynamisk justere størrelsen på en koblet liste i henhold til kravene.

Figur 4. En koblet liste
Koblede lister kan klassifiseres i forskjellige typer:
Noen applikasjoner for koblede lister:
- De koblede listene hjelper oss med å implementere stabler, køer, binære trær og grafer av forhåndsdefinert størrelse.
- Vi kan også implementere Operativsystems funksjon for dynamisk minnehåndtering.
- Koblede lister tillater også polynomimplementering for matematiske operasjoner.
- Vi kan bruke Circular Linked List for å implementere operativsystemer eller applikasjonsfunksjoner som Round Robin utfører oppgaver.
- Circular Linked List er også nyttig i en lysbildefremvisning der en bruker må gå tilbake til det første lysbildet etter at det siste lysbildet er presentert.
- Doubly Linked List brukes til å implementere frem- og bakover-knapper i en nettleser for å flytte fremover og bakover på de åpne sidene på et nettsted.
3. Stabler
EN Stable er en lineær datastruktur som følger LIFO (Sist inn, først ut) prinsipp som tillater operasjoner som innsetting og sletting fra den ene enden av stabelen, dvs. Topp. Stabler kan implementeres ved hjelp av sammenhengende minne, en Array, og ikke-sammenhengende minne, en Linked List. Eksempler fra virkeligheten på stabler er hauger med bøker, en kortstokk, hauger med penger og mange flere.
latex tekststørrelse

Figur 5. Et virkelighetseksempel på stabel
Figuren ovenfor representerer det virkelige eksempelet på en stabel der operasjonene bare utføres fra den ene enden, som innsetting og fjerning av nye bøker fra toppen av stabelen. Det innebærer at innsetting og sletting i stabelen kun kan gjøres fra toppen av stabelen. Vi har kun tilgang til toppene til stakken til enhver tid.
De primære operasjonene i stakken er som følger:

Figur 6. En stabel
Noen bruksområder for stabler:
- Stakken brukes som en midlertidig lagringsstruktur for rekursive operasjoner.
- Stack brukes også som Auxiliary Storage Structure for funksjonskall, nestede operasjoner og utsatte/utsatte funksjoner.
- Vi kan administrere funksjonsanrop ved å bruke Stacks.
- Stabler brukes også til å evaluere de aritmetiske uttrykkene i forskjellige programmeringsspråk.
- Stabler er også nyttige for å konvertere infix-uttrykk til postfix-uttrykk.
- Stabler lar oss sjekke uttrykkets syntaks i programmeringsmiljøet.
- Vi kan matche parenteser ved å bruke stabler.
- Stabler kan brukes til å snu en streng.
- Stabler er nyttige for å løse problemer basert på tilbakesporing.
- Vi kan bruke stabler i dybde-først-søk i graf- og tregjennomgang.
- Stabler brukes også i operativsystemfunksjoner.
- Stabler brukes også i UNDO- og REDO-funksjonene i en redigering.
4. Haler
EN Kø er en lineær datastruktur som ligner på en stabel med noen begrensninger på innsetting og sletting av elementene. Innsettingen av et element i en kø gjøres i den ene enden, og fjerningen gjøres i en annen eller motsatt ende. Dermed kan vi konkludere med at Queue-datastrukturen følger FIFO-prinsippet (First In, First Out) for å manipulere dataelementene. Implementering av køer kan gjøres ved hjelp av matriser, lenkede lister eller stabler. Noen virkelige eksempler på køer er en kø ved billettskranken, en rulletrapp, en bilvask og mange flere.

Figur 7. Et virkelighetseksempel på kø
annet hvis java
Bildet ovenfor er en virkelig illustrasjon av en kinobillettskranke som kan hjelpe oss å forstå køen der kunden som kommer først alltid blir servert først. Kunden som kommer sist vil utvilsomt bli servert sist. Begge ender av køen er åpne og kan utføre forskjellige operasjoner. Et annet eksempel er en food court-linje hvor kunden settes inn fra bakenden mens kunden fjernes i frontenden etter å ha levert tjenesten de ba om.
Følgende er de primære operasjonene i køen:

Figur 8. Kø
Noen applikasjoner av køer:
- Køer brukes vanligvis i breddesøkeoperasjonen i Graphs.
- Køer brukes også i jobbplanleggingsoperasjoner av operativsystemer, som en tastaturbufferkø for å lagre tastene som trykkes av brukere og en utskriftsbufferkø for å lagre dokumentene som skrives ut av skriveren.
- Køer er ansvarlige for CPU-planlegging, jobbplanlegging og diskplanlegging.
- Prioritetskøer brukes i filnedlastingsoperasjoner i en nettleser.
- Køer brukes også til å overføre data mellom eksterne enheter og CPU.
- Køer er også ansvarlige for å håndtere avbrudd generert av brukerapplikasjonene for CPU.
Ikke-lineære datastrukturer
Ikke-lineære datastrukturer er datastrukturer der dataelementene ikke er ordnet i sekvensiell rekkefølge. Her er innsetting og fjerning av data ikke mulig på en lineær måte. Det eksisterer et hierarkisk forhold mellom de enkelte dataelementene.
Typer ikke-lineære datastrukturer
Følgende er listen over ikke-lineære datastrukturer som vi vanligvis bruker:
1. Trær
Et tre er en ikke-lineær datastruktur og et hierarki som inneholder en samling av noder slik at hver node i treet lagrer en verdi og en liste over referanser til andre noder ('barnene').
Tredatastrukturen er en spesialisert metode for å ordne og samle inn data i datamaskinen for å bli utnyttet mer effektivt. Den inneholder en sentral node, strukturelle noder og undernoder koblet via kanter. Vi kan også si at tredatastrukturen består av røtter, grener og blader koblet sammen.

Figur 9. Et tre
Trær kan deles inn i forskjellige typer:
Noen bruksområder for trær:
- Trær implementerer hierarkiske strukturer i datasystemer som kataloger og filsystemer.
- Trær brukes også til å implementere navigasjonsstrukturen til et nettsted.
- Vi kan generere kode som Huffmans kode ved å bruke Trees.
- Trær er også nyttige i beslutningstaking i spillapplikasjoner.
- Trær er ansvarlige for å implementere prioritetskøer for prioritetsbaserte OS-planleggingsfunksjoner.
- Trær er også ansvarlige for å analysere uttrykk og utsagn i kompilatorene til forskjellige programmeringsspråk.
- Vi kan bruke trær til å lagre datanøkler for indeksering for Database Management System (DBMS).
- Spanning Trees lar oss rute beslutninger i data- og kommunikasjonsnettverk.
- Trær brukes også i stifinningsalgoritmen implementert i applikasjoner for kunstig intelligens (AI), robotikk og videospill.
2. Grafer
En graf er et annet eksempel på en ikke-lineær datastruktur som omfatter et begrenset antall noder eller hjørner og kantene som forbinder dem. Grafene brukes til å adressere problemer i den virkelige verden der den betegner problemområdet som et nettverk som sosiale nettverk, kretsnettverk og telefonnettverk. For eksempel kan nodene eller toppunktene til en graf representere en enkelt bruker i et telefonnettverk, mens kantene representerer koblingen mellom dem via telefon.
Grafdatastrukturen, G regnes som en matematisk struktur som består av et sett med hjørner, V og et sett med kanter, E som vist nedenfor:
G = (V,E)
liste java

Figur 10. En graf
Figuren ovenfor representerer en graf med syv hjørner A, B, C, D, E, F, G og ti kanter [A, B], [A, C], [B, C], [B, D], [B, E], [C, D], [D, E], [D, F], [E, F] og [E, G].
Avhengig av plasseringen av toppunktene og kantene, kan grafene klassifiseres i forskjellige typer:
Noen bruksområder for grafer:
- Grafer hjelper oss med å representere ruter og nettverk i transport-, reise- og kommunikasjonsapplikasjoner.
- Grafer brukes til å vise ruter i GPS.
- Grafer hjelper oss også med å representere sammenkoblingene i sosiale nettverk og andre nettverksbaserte applikasjoner.
- Grafer brukes i kartleggingsapplikasjoner.
- Grafer er ansvarlige for representasjonen av brukerpreferanser i e-handelsapplikasjoner.
- Grafer brukes også i Utility-nettverk for å identifisere problemene for lokale eller kommunale selskaper.
- Grafer hjelper også med å administrere utnyttelsen og tilgjengeligheten av ressurser i en organisasjon.
- Grafer brukes også til å lage dokumentlenkekart over nettsidene for å vise tilkoblingen mellom sidene gjennom hyperkoblinger.
- Grafer brukes også i robotbevegelser og nevrale nettverk.
Grunnleggende operasjoner av datastrukturer
I den følgende delen vil vi diskutere de forskjellige typene operasjoner som vi kan utføre for å manipulere data i hver datastruktur:
- Kompileringstid
- Kjøretid
For eksempel malloc() funksjonen brukes i C Language for å lage datastruktur.
Forstå den abstrakte datatypen
I henhold til National Institute of Standards and Technology (NIST) , er en datastruktur et arrangement av informasjon, vanligvis i minnet, for bedre algoritmeeffektivitet. Datastrukturer inkluderer koblede lister, stabler, køer, trær og ordbøker. De kan også være en teoretisk enhet, som navnet og adressen til en person.
Fra definisjonen nevnt ovenfor kan vi konkludere med at operasjonene i datastruktur inkluderer:
- Et høyt nivå av abstraksjoner som tillegg eller sletting av et element fra en liste.
- Søke og sortere et element i en liste.
- Få tilgang til det høyeste prioriterte elementet i en liste.
Når datastrukturen utfører slike operasjoner, er den kjent som en Abstrakt datatype (ADT) .
Vi kan definere det som et sett med dataelementer sammen med operasjonene på dataene. Begrepet 'abstrakt' refererer til det faktum at dataene og de grunnleggende operasjonene som er definert på dem, studeres uavhengig av implementeringen. Det inkluderer hva vi kan gjøre med dataene, ikke hvordan vi kan gjøre det.
En ADI-implementering inneholder en lagringsstruktur for å lagre dataelementene og algoritmene for grunnleggende drift. Alle datastrukturene, som en matrise, koblet liste, kø, stabel, etc., er eksempler på ADT.
Forstå fordelene ved å bruke ADT
I den virkelige verden utvikler programmer seg som en konsekvens av nye begrensninger eller krav, så endring av et program krever vanligvis en endring i en eller flere datastrukturer. Anta for eksempel at vi ønsker å sette inn et nytt felt i en ansatts post for å holde styr på flere detaljer om hver ansatt. I så fall kan vi forbedre effektiviteten til programmet ved å erstatte en Array med en Linked-struktur. I en slik situasjon er det uegnet å omskrive hver prosedyre som bruker den modifiserte strukturen. Derfor er et bedre alternativ å skille en datastruktur fra implementeringsinformasjonen. Dette er prinsippet bak bruken av abstrakte datatyper (ADT).
Noen applikasjoner av datastrukturer
Følgende er noen applikasjoner av datastrukturer:
- Datastrukturer hjelper til med organiseringen av data i datamaskinens minne.
- Datastrukturer hjelper også med å representere informasjonen i databaser.
- Data Structures tillater implementering av algoritmer for å søke gjennom data (for eksempel søkemotor).
- Vi kan bruke datastrukturene til å implementere algoritmene for å manipulere data (for eksempel tekstbehandlere).
- Vi kan også implementere algoritmene for å analysere data ved hjelp av datastrukturer (for eksempel data miners).
- Datastrukturer støtter algoritmer for å generere data (for eksempel en tilfeldig tallgenerator).
- Datastrukturer støtter også algoritmer for å komprimere og dekomprimere dataene (for eksempel et zip-verktøy).
- Vi kan også bruke datastrukturer til å implementere algoritmer for å kryptere og dekryptere dataene (for eksempel et sikkerhetssystem).
- Ved hjelp av Data Structures kan vi bygge programvare som kan administrere filer og kataloger (For eksempel en filbehandler).
- Vi kan også utvikle programvare som kan gjengi grafikk ved hjelp av Data Structures. (For eksempel en nettleser eller 3D-gjengivelsesprogramvare).
Bortsett fra de, som nevnt tidligere, er det mange andre applikasjoner av Data Structures som kan hjelpe oss å bygge hvilken som helst ønsket programvare.