Før vi ser på forskjellene mellom BFS og DFS, bør vi først vite om BFS og DFS separat.
Hva er BFS?
BFS står for Bredde først søk . Det er også kjent som nivåordregjennomgang . Kødatastrukturen brukes for Breadth First Search-gjennomgangen. Når vi bruker BFS-algoritmen for kryssingen i en graf, kan vi vurdere hvilken som helst node som en rotnode.
La oss vurdere grafen nedenfor for den første søkovergangen i bredden.
java-streng til array
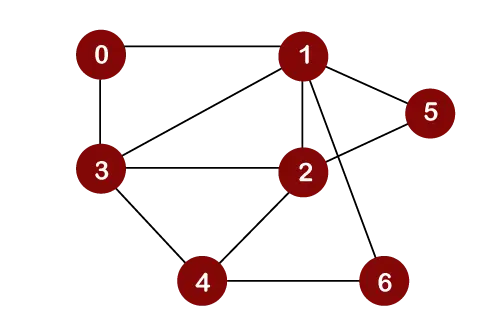
Anta at vi anser node 0 som en rotnode. Derfor vil kryssingen startes fra node 0.

Når node 0 er fjernet fra køen, blir den skrevet ut og merket som en besøkt node.
Når node 0 blir fjernet fra køen, vil de tilstøtende nodene til node 0 bli satt inn i en kø som vist nedenfor:

Nå vil node 1 bli fjernet fra køen; den blir skrevet ut og merket som en besøkt node
Når node 1 er fjernet fra køen, vil alle tilstøtende noder til en node 1 bli lagt til i en kø. De tilstøtende nodene til node 1 er 0, 3, 2, 6 og 5. Men vi må bare sette inn ubesøkte noder i en kø. Siden nodene 3, 2, 6 og 5 ikke er besøkt; derfor vil disse nodene bli lagt til i en kø som vist nedenfor:

Den neste noden er 3 i en kø. Så node 3 vil bli fjernet fra køen, den blir skrevet ut og merket som besøkt som vist nedenfor:

Når node 3 blir fjernet fra køen, vil alle de tilstøtende nodene til node 3 unntatt de besøkte nodene bli lagt til i en kø. De tilstøtende nodene til node 3 er 0, 1, 2 og 4. Siden nodene 0, 1 allerede er besøkt, og node 2 er tilstede i en kø; derfor må vi bare sette inn node 4 i en kø.
python sortering tuppel

Nå er neste node i køen 2. Så 2 vil bli slettet fra køen. Den blir skrevet ut og merket som besøkt som vist nedenfor:

Når node 2 blir fjernet fra køen, vil alle tilstøtende noder til node 2, bortsett fra de besøkte nodene, bli lagt til i en kø. De tilstøtende nodene til node 2 er 1, 3, 5, 6 og 4. Siden nodene 1 og 3 allerede er besøkt, og 4, 5, 6 allerede er lagt til i køen; derfor trenger vi ikke å sette inn noen node i køen.
Det neste elementet er 5. Så 5 vil bli slettet fra køen. Den blir skrevet ut og merket som besøkt som vist nedenfor:

Når node 5 er fjernet fra køen, vil alle tilstøtende noder til node 5, bortsett fra de besøkte nodene, bli lagt til i køen. De tilstøtende nodene til node 5 er 1 og 2. Siden begge nodene allerede er besøkt; derfor er det ingen toppunkt som skal settes inn i en kø.
Den neste noden er 6. Så 6 vil bli slettet fra køen. Den blir skrevet ut og merket som besøkt som vist nedenfor:

Når noden 6 blir fjernet fra køen, vil alle tilstøtende noder til node 6, bortsett fra de besøkte nodene, bli lagt til i køen. De tilstøtende nodene til node 6 er 1 og 4. Siden node 1 allerede er besøkt og node 4 allerede er lagt til i køen; derfor er det ikke toppunkt som skal settes inn i køen.
Det neste elementet i køen er 4. Så 4 vil bli slettet fra køen. Den blir skrevet ut og merket som besøkt.
Når noden 4 er fjernet fra køen, vil alle tilstøtende noder til node 4, bortsett fra de besøkte nodene, bli lagt til i køen. De tilstøtende nodene til node 4 er 3, 2 og 6. Siden alle tilstøtende noder allerede er besøkt; så det er ingen toppunkt som skal settes inn i køen.
Hva er DFS?
DFS står for Depth First Search. Ved DFS-traversering brukes stackdatastrukturen, som fungerer etter LIFO (Last In First Out)-prinsippet. I DFS kan traversing startes fra hvilken som helst node, eller vi kan si at hvilken som helst node kan betraktes som en rotnode inntil rotnoden ikke er nevnt i oppgaven.
Når det gjelder BFS, elementet som slettes fra køen, blir de tilstøtende nodene til den slettede noden lagt til køen. I motsetning til dette, i DFS, elementet som fjernes fra stabelen, blir bare én tilstøtende node av en slettet node lagt til i stabelen.
skjell sortering
La oss se på grafen nedenfor for gjennomgangen av Depth First Search.

Betrakt node 0 som en rotnode.
Først setter vi inn elementet 0 i stabelen som vist nedenfor:

Noden 0 har to tilstøtende noder, dvs. 1 og 3. Nå kan vi bare ta en tilstøtende node, enten 1 eller 3, for å krysse. Anta at vi vurderer node 1; derfor legges 1 inn i en stabel og skrives ut som vist nedenfor:

Nå skal vi se på de tilstøtende toppunktene til node 1. De ubesøkte tilstøtende toppunktene til node 1 er 3, 2, 5 og 6. Vi kan vurdere hvilken som helst av disse fire toppunktene. Anta at vi tar node 3 og setter den inn i stabelen som vist nedenfor:

Tenk på de ubesøkte tilstøtende toppunktene til node 3. De ubesøkte tilstøtende toppunktene til node 3 er 2 og 4. Vi kan ta en av toppunktene, dvs. 2 eller 4. Anta at vi tar toppunkt 2 og setter den inn i stabelen som vist nedenfor:

De ubesøkte tilstøtende toppunktene til node 2 er 5 og 4. Vi kan velge en av toppunktene, dvs. 5 eller 4. Anta at vi tar toppunkt 4 og setter inn i stabelen som vist nedenfor:
Spørsmål til intervju med java språk

Nå skal vi vurdere de ubesøkte tilstøtende toppunktene til node 4. Det ubesøkte tilstøtende toppunktet til node 4 er node 6. Derfor settes element 6 inn i stabelen som vist nedenfor:

Etter å ha satt inn element 6 i stabelen, vil vi se på de ubesøkte tilstøtende toppunktene til node 6. Siden det ikke er noen ubesøkte tilstøtende toppunkter til node 6, så kan vi ikke bevege oss forbi node 6. I dette tilfellet vil vi utføre tilbakesporing . Det øverste elementet, dvs. 6, vil bli trukket ut fra stabelen som vist nedenfor:


Det øverste elementet i stabelen er 4. Siden det ikke er noen ubesøkte tilstøtende hjørner igjen av node 4; derfor er node 4 spratt ut av stabelen som vist nedenfor:


Det nest øverste elementet i stabelen er 2. Nå skal vi se på de ubesøkte tilstøtende toppunktene til node 2. Siden bare én ubesøkt node, dvs. 5 er igjen, vil node 5 bli skjøvet inn i stabelen over 2 og skrives ut som vist under:

Nå skal vi sjekke de tilstøtende toppunktene til node 5, som fortsatt er ubesøkt. Siden det ikke er noe toppunkt igjen å besøke, så vipper vi element 5 fra stabelen som vist nedenfor:
utbyggerdesignmønster

Vi kan ikke flytte ytterligere 5, så vi må utføre tilbakesporing. Ved tilbakesporing vil det øverste elementet bli spratt ut fra stabelen. Det øverste elementet er 5 som ville bli spratt ut fra stabelen, og vi går tilbake til node 2 som vist nedenfor:

Nå skal vi sjekke de ubesøkte tilstøtende toppunktene til node 2. Siden det ikke er noen tilstøtende toppunkt igjen å besøke, så utfører vi tilbakesporing. Ved tilbakesporing vil det øverste elementet, dvs. 2, bli spratt ut fra stabelen, og vi går tilbake til node 3 som vist nedenfor:


Nå skal vi sjekke de ubesøkte tilstøtende toppunktene til node 3. Siden det ikke er noe tilstøtende toppunkt igjen å besøke, så utfører vi tilbakesporing. Ved tilbakesporing vil det øverste elementet, dvs. 3, bli spratt ut fra stabelen og vi flytter tilbake til node 1 som vist nedenfor:


Etter å ha spratt ut element 3, vil vi sjekke de ubesøkte tilstøtende toppunktene til node 1. Siden det ikke er noe toppunkt igjen å besøke; derfor vil tilbakesporingen bli utført. Ved tilbakesporing vil det øverste elementet, dvs. 1, bli spratt ut fra stabelen, og vi går tilbake til node 0 som vist nedenfor:


Vi vil sjekke de tilstøtende toppunktene til node 0, som fortsatt er ubesøkt. Siden det ikke er noen tilstøtende toppunkt igjen å besøke, så utfører vi backtracking. I dette vil bare ett element, dvs. 0 igjen i stabelen, bli spratt ut fra stabelen som vist nedenfor:

Som vi kan observere i figuren ovenfor at stabelen er tom. Så vi må stoppe DFS-gjennomgangen her, og elementene som skrives ut er resultatet av DFS-gjennomgangen.
Forskjeller mellom BFS og DFS
Følgende er forskjellene mellom BFS og DFS:
| BFS | DFS | |
|---|---|---|
| Fullstendig format | BFS står for Breadth First Search. | DFS står for Depth First Search. |
| Teknikk | Det er en toppunktbasert teknikk for å finne den korteste veien i en graf. | Det er en kantbasert teknikk fordi toppunktene langs kanten utforskes først fra start- til sluttnoden. |
| Definisjon | BFS er en traverseringsteknikk der alle nodene på samme nivå utforskes først, og deretter går vi til neste nivå. | DFS er også en traverseringsteknikk der traversering startes fra rotnoden og utforske nodene så langt som mulig til vi kommer til noden som ikke har ubesøkte tilstøtende noder. |
| Data struktur | Kødatastruktur brukes for BFS-traverseringen. | Stabeldatastruktur brukes for BFS-gjennomgangen. |
| Tilbakesporing | BFS bruker ikke tilbakesporingskonseptet. | DFS bruker tilbakesporing for å krysse alle ubesøkte noder. |
| Antall kanter | BFS finner den korteste banen med et minimum antall kanter å krysse fra kilden til destinasjonstoppunktet. | I DFS kreves det et større antall kanter for å krysse fra kildetoppunktet til destinasjonsvertekset. |
| Optimalitet | BFS-traversering er optimal for de toppunktene som skal søkes nærmere kildetoppunktet. | DFS-traversering er optimal for de grafene der løsninger er borte fra kildepunktet. |
| Hastighet | BFS er tregere enn DFS. | DFS er raskere enn BFS. |
| Egnethet for beslutningstre | Det er ikke egnet for beslutningstreet fordi det krever å utforske alle nabonodene først. | Den passer for beslutningstreet. Basert på avgjørelsen utforsker den alle veier. Når målet er funnet, stopper det gjennomkjøringen. |
| Minneeffektiv | Det er ikke minneeffektivt da det krever mer minne enn DFS. | Det er minneeffektivt da det krever mindre minne enn BFS. |