En markør i SQL Server er en d atabase-objekt som lar oss hente hver rad om gangen og manipulere dataene . En markør er ikke mer enn en peker til en rad. Den brukes alltid sammen med en SELECT-setning. Det er vanligvis en samling av SQL logikk som går gjennom et forhåndsbestemt antall rader én etter én. En enkel illustrasjon av markøren er når vi har en omfattende database med arbeiders poster og ønsker å beregne hver arbeiders lønn etter fradrag for skatter og permisjoner.
SQL-serveren markørens formål er å oppdatere dataene rad for rad, endre dem eller utføre beregninger som ikke er mulig når vi henter alle poster samtidig . Det er også nyttig for å utføre administrative oppgaver som SQL Server-databasesikkerhetskopier i sekvensiell rekkefølge. Markører brukes hovedsakelig i utviklings-, DBA- og ETL-prosesser.
Denne artikkelen forklarer alt om SQL Server-markøren, for eksempel markørens livssyklus, hvorfor og når markøren brukes, hvordan du implementerer markørene, dens begrensninger og hvordan vi kan erstatte en markør.
Markørens livssyklus
Vi kan beskrive livssyklusen til en markør inn i fem forskjellige seksjoner følgende:
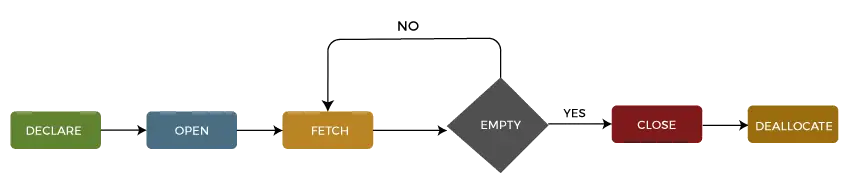
1: Angi markør
Det første trinnet er å erklære markøren ved å bruke SQL-setningen nedenfor:
listenode i java
DECLARE cursor_name CURSOR FOR select_statement;
Vi kan deklarere en markør ved å spesifisere navnet med datatypen CURSOR etter nøkkelordet DECLARE. Deretter vil vi skrive SELECT-setningen som definerer utdata for markøren.
2: Åpne markør
Det er et andre trinn der vi åpner markøren for å lagre data hentet fra resultatsettet. Vi kan gjøre dette ved å bruke SQL-setningen nedenfor:
OPEN cursor_name;
3: Hent markør
Det er et tredje trinn der rader kan hentes én etter én eller i en blokk for å gjøre datamanipulering som å sette inn, oppdatere og slette operasjoner på den aktive raden i markøren. Vi kan gjøre dette ved å bruke SQL-setningen nedenfor:
FETCH NEXT FROM cursor INTO variable_list;
Vi kan også bruke @@FETCHSTATUS-funksjon i SQL Server for å få statusen til den nyeste FETCH-setningsmarkøren som ble utført mot markøren. De HENT setningen var vellykket når @@FETCHSTATUS gir null utdata. De SAMTIDIG SOM setningen kan brukes til å hente alle poster fra markøren. Følgende kode forklarer det tydeligere:
WHILE @@FETCH_STATUS = 0 BEGIN FETCH NEXT FROM cursor_name; END;
4: Lukk markør
Det er et fjerde trinn der markøren skal lukkes etter at vi er ferdige med arbeidet med en markør. Vi kan gjøre dette ved å bruke SQL-setningen nedenfor:
CLOSE cursor_name;
5: Tildel markør
Det er det femte og siste trinnet der vi vil slette markørdefinisjonen og frigjøre alle systemressursene knyttet til markøren. Vi kan gjøre dette ved å bruke SQL-setningen nedenfor:
DEALLOCATE cursor_name;
Bruk av SQL Server Cursor
Vi vet at administrasjonssystemer for relasjonelle databaser, inkludert SQL Server, er utmerket til å håndtere data på et sett med rader som kalles resultatsett. For eksempel , vi har et bord produkttabell som inneholder produktbeskrivelsene. Hvis vi ønsker å oppdatere pris av produktet, deretter ' OPPDATER' spørringen vil oppdatere alle poster som samsvarer med betingelsen i ' HVOR' klausul:
UPDATE product_table SET unit_price = 100 WHERE product_id = 105;
Noen ganger må applikasjonen behandle radene på en enkelt måte, dvs. rad for rad i stedet for hele resultatsettet på en gang. Vi kan gjøre denne prosessen ved å bruke markører i SQL Server. Før du bruker markøren, må vi vite at markørene er veldig dårlige i ytelse, så den bør alltid bare brukes når det ikke er noe annet alternativ enn markøren.
Markøren bruker samme teknikk som vi bruker løkker som FOREACH, FOR, WHILE, DO WHILE for å iterere ett objekt om gangen i alle programmeringsspråk. Derfor kan det velges fordi det bruker samme logikk som programmeringsspråkets looping-prosess.
Typer markører i SQL Server
Følgende er de forskjellige typene markører i SQL Server oppført nedenfor:
- Statiske markører
- Dynamiske markører
- Forover-bare markører
- Keyset Cursorer

Statiske markører
Resultatsettet som vises av den statiske markøren er alltid det samme som da markøren ble åpnet første gang. Siden den statiske markøren vil lagre resultatet i tempdb , det er de alltid skrivebeskyttet . Vi kan bruke den statiske markøren til å flytte både fremover og bakover. I motsetning til andre markører er den tregere og bruker mer minne. Som et resultat kan vi bare bruke det når rulling er nødvendig, og andre markører ikke er egnet.
Denne markøren viser rader som ble fjernet fra databasen etter at den ble åpnet. En statisk markør representerer ingen INSERT-, UPDATE- eller DELETE-operasjoner (med mindre markøren lukkes og åpnes på nytt).
Dynamiske markører
De dynamiske markørene er motsatte av de statiske markørene som lar oss utføre dataoppdatering, sletting og innsetting mens markøren er åpen. Det er rullbar som standard . Den kan oppdage alle endringer som er gjort i radene, rekkefølgen og verdiene i resultatsettet, enten endringene skjer innenfor markøren eller utenfor markøren. Utenfor markøren kan vi ikke se oppdateringene før de er begått.
Forover-bare markører
Det er standard og raskeste markørtype blant alle markører. Det kalles en bare fremover-markør fordi det går bare fremover gjennom resultatsettet . Denne markøren støtter ikke rulling. Den kan bare hente rader fra begynnelsen til slutten av resultatsettet. Den lar oss utføre innsetting, oppdatering og sletting. Her er effekten av innsetting, oppdatering og sletting utført av brukeren som påvirker rader i resultatsettet synlige når radene hentes fra markøren. Når raden ble hentet, kan vi ikke se endringene som er gjort på rader gjennom markøren.
Forward-Only-markørene er tre kategorisert i tre typer:
- Forward_Only Keyset
- Forward_Only Static
- Fast_Forward

Tastesettdrevne markører
Denne markørfunksjonaliteten ligger mellom en statisk og en dynamisk markør om dens evne til å oppdage endringer. Den kan ikke alltid oppdage endringer i resultatsettets medlemskap og rekkefølge som en statisk markør. Den kan oppdage endringer i resultatsettets radverdier som en dynamisk markør. Det kan bare flytte fra første til siste og siste til første rad . Rekkefølgen og medlemskapet er fast når denne markøren åpnes.
Den betjenes av et sett med unike identifikatorer som er de samme som nøklene i nøkkelsettet. Tastesettet bestemmes av alle rader som kvalifiserte SELECT-setningen da markøren ble åpnet første gang. Den kan også oppdage eventuelle endringer i datakilden, som støtter oppdaterings- og sletteoperasjoner. Den er rullbar som standard.
Implementering av eksempel
La oss implementere markøreksemplet i SQL-serveren. Vi kan gjøre dette ved først å lage en tabell kalt ' kunde ' ved å bruke utsagnet nedenfor:
hva er størrelsen på datamaskinens skjerm
CREATE TABLE customer ( id int PRIMARY KEY, c_name nvarchar(45) NOT NULL, email nvarchar(45) NOT NULL, city nvarchar(25) NOT NULL );
Deretter setter vi inn verdier i tabellen. Vi kan utføre setningen nedenfor for å legge til data i en tabell:
INSERT INTO customer (id, c_name, email, city) VALUES (1,'Steffen', '[email protected]', 'Texas'), (2, 'Joseph', '[email protected]', 'Alaska'), (3, 'Peter', '[email protected]', 'California'), (4,'Donald', '[email protected]', 'New York'), (5, 'Kevin', '[email protected]', 'Florida'), (6, 'Marielia', '[email protected]', 'Arizona'), (7,'Antonio', '[email protected]', 'New York'), (8, 'Diego', '[email protected]', 'California');
Vi kan verifisere dataene ved å utføre PLUKKE UT uttalelse:
SELECT * FROM customer;
Etter å ha utført spørringen, kan vi se utgangen nedenfor der vi har åtte rader inn i tabellen:

Nå vil vi lage en markør for å vise kundepostene. Kodebitene nedenfor forklarer alle trinnene i markørerklæringen eller opprettelsen ved å sette alt sammen:
inkluderer c-programmering
--Declare the variables for holding data. DECLARE @id INT, @c_name NVARCHAR(50), @city NVARCHAR(50) --Declare and set counter. DECLARE @Counter INT SET @Counter = 1 --Declare a cursor DECLARE PrintCustomers CURSOR FOR SELECT id, c_name, city FROM customer --Open cursor OPEN PrintCustomers --Fetch the record into the variables. FETCH NEXT FROM PrintCustomers INTO @id, @c_name, @city --LOOP UNTIL RECORDS ARE AVAILABLE. WHILE @@FETCH_STATUS = 0 BEGIN IF @Counter = 1 BEGIN PRINT 'id' + CHAR(9) + 'c_name' + CHAR(9) + CHAR(9) + 'city' PRINT '--------------------------' END --Print the current record PRINT CAST(@id AS NVARCHAR(10)) + CHAR(9) + @c_name + CHAR(9) + CHAR(9) + @city --Increment the counter variable SET @Counter = @Counter + 1 --Fetch the next record into the variables. FETCH NEXT FROM PrintCustomers INTO @id, @c_name, @city END --Close the cursor CLOSE PrintCustomers --Deallocate the cursor DEALLOCATE PrintCustomers
Etter å ha utført en markør, vil vi få følgende utgang:

Begrensninger for SQL Server Cursor
En markør har noen begrensninger, slik at den alltid skal brukes bare når det ikke er noe alternativ bortsett fra markøren. Disse begrensningene er:
- Markøren bruker nettverksressurser ved å kreve en nettverksreise hver gang den henter en post.
- En markør er et minneresident sett med pekere, noe som betyr at det krever noe minne som andre prosesser kan bruke på maskinen vår.
- Den pålegger låser på en del av tabellen eller hele tabellen når data behandles.
- Markørens ytelse og hastighet er tregere fordi de oppdaterer tabellposter én rad om gangen.
- Markørene er raskere enn while-løkker, men de har mer overhead.
- Antall rader og kolonner som bringes inn i markøren er et annet aspekt som påvirker markørhastigheten. Det refererer til hvor mye tid det tar å åpne markøren og utføre en hente-setning.
Hvordan kan vi unngå markører?
Hovedoppgaven til markørene er å krysse tabellen rad for rad. Den enkleste måten å unngå markører på er gitt nedenfor:
Bruker SQL while loop
Den enkleste måten å unngå bruk av markør på er å bruke en while-løkke som gjør det mulig å sette inn et resultatsett i den midlertidige tabellen.
Brukerdefinerte funksjoner
Noen ganger brukes markører for å beregne det resulterende radsettet. Dette kan vi oppnå ved å bruke en brukerdefinert funksjon som oppfyller kravene.
Bruke Joins
Join behandler kun de kolonnene som oppfyller den angitte betingelsen og reduserer dermed kodelinjene som gir raskere ytelse enn markørene i tilfelle store poster må behandles.