En prosess kan være av to typer:
- Uavhengig prosess.
- Samarbeidsprosess.
En uavhengig prosess påvirkes ikke av utførelsen av andre prosesser, mens en samarbeidende prosess kan påvirkes av andre utførende prosesser. Selv om man kan tro at disse prosessene, som kjører uavhengig, vil utføres veldig effektivt, er det i virkeligheten mange situasjoner der samarbeidende natur kan brukes for å øke beregningshastigheten, bekvemmeligheten og modulariteten. Inter-prosess kommunikasjon (IPC) er en mekanisme som lar prosesser kommunisere med hverandre og synkronisere handlingene deres. Kommunikasjonen mellom disse prosessene kan sees på som en metode for samarbeid mellom dem. Prosesser kan kommunisere med hverandre gjennom begge:
- Delt minne
- Meldingen går igjennom
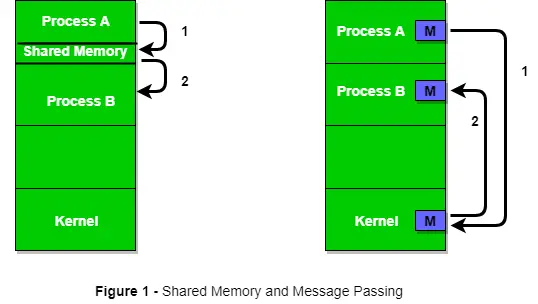
Figur 1 nedenfor viser en grunnleggende struktur for kommunikasjon mellom prosesser via metoden med delt minne og via metoden for meldingsoverføring.
Et operativsystem kan implementere begge kommunikasjonsmetodene. Først vil vi diskutere metodene for delt minne for kommunikasjon og deretter sende meldinger. Kommunikasjon mellom prosesser som bruker delt minne krever at prosesser deler en eller annen variabel, og det avhenger helt av hvordan programmereren vil implementere den. En måte å kommunisere på ved hjelp av delt minne kan tenkes slik: Anta at prosess1 og prosess2 utføres samtidig, og de deler noen ressurser eller bruker informasjon fra en annen prosess. Prosess1 genererer informasjon om visse beregninger eller ressurser som brukes og oppbevarer den som en registrering i delt minne. Når prosess2 trenger å bruke den delte informasjonen, vil den sjekke inn posten som er lagret i delt minne og notere informasjonen generert av prosess1 og handle deretter. Prosesser kan bruke delt minne for å trekke ut informasjon som en post fra en annen prosess, samt for å levere spesifikk informasjon til andre prosesser.
La oss diskutere et eksempel på kommunikasjon mellom prosesser som bruker metoden for delt minne.
i) Delt minnemetode
Eks: Produsent-forbrukerproblem
Det er to prosesser: Produsent og Forbruker. Produsenten produserer noen varer og forbrukeren bruker denne varen. De to prosessene deler en felles plass eller minneplassering kjent som en buffer hvor varen produsert av produsenten lagres og hvor forbrukeren forbruker varen hvis nødvendig. Det er to versjoner av dette problemet: den første er kjent som det ubegrensede bufferproblemet der produsenten kan fortsette å produsere varer og det er ingen begrensning på størrelsen på bufferen, den andre er kjent som det begrensede bufferproblemet i som produsenten kan produsere opp til et visst antall varer før den begynner å vente på at forbrukeren skal konsumere den. Vi vil diskutere problemet med begrenset buffer. Først vil produsenten og forbrukeren dele noe felles minne, deretter vil produsenten begynne å produsere varer. Hvis den totale produserte varen er lik størrelsen på bufferen, vil produsenten vente med å få den konsumert av forbrukeren. På samme måte vil forbrukeren først sjekke om varen er tilgjengelig. Hvis ingen vare er tilgjengelig, vil forbrukeren vente på at produsenten skal produsere den. Hvis det er varer tilgjengelig, vil forbrukeren konsumere dem. Pseudokoden som skal demonstreres er gitt nedenfor:
Delte data mellom de to prosessene
C
#define buff_max 25> #define mod %> >struct> item{> >// different member of the produced data> >// or consumed data> >---------> >}> > >// An array is needed for holding the items.> >// This is the shared place which will be> >// access by both process> >// item shared_buff [ buff_max ];> > >// Two variables which will keep track of> >// the indexes of the items produced by producer> >// and consumer The free index points to> >// the next free index. The full index points to> >// the first full index.> >int> free_index = 0;> >int> full_index = 0;> > |
>
>
Produsentprosesskode
C
item nextProduced;> > >while>(1){> > >// check if there is no space> >// for production.> >// if so keep waiting.> >while>((free_index+1) mod buff_max == full_index);> > >shared_buff[free_index] = nextProduced;> >free_index = (free_index + 1) mod buff_max;> >}> |
>
>
Forbrukerprosesskode
C
item nextConsumed;> > >while>(1){> > >// check if there is an available> >// item for consumption.> >// if not keep on waiting for> >// get them produced.> >while>((free_index == full_index);> > >nextConsumed = shared_buff[full_index];> >full_index = (full_index + 1) mod buff_max;> >}> |
>
>
I koden ovenfor vil produsenten begynne å produsere igjen når (free_index+1) mod buff max vil være gratis, fordi hvis den ikke er gratis, betyr dette at det fortsatt er varer som kan konsumeres av forbrukeren, så det er ikke nødvendig å produsere mer. På samme måte, hvis gratis indeks og full indeks peker til samme indeks, betyr dette at det ikke er noen varer å konsumere.
Generell C++-implementering:
C++
#include> #include> #include> #include> #define buff_max 25> #define mod %> struct> item {> >// different member of the produced data> >// or consumed data> >// ---------> };> // An array is needed for holding the items.> // This is the shared place which will be> // access by both process> // item shared_buff[buff_max];> // Two variables which will keep track of> // the indexes of the items produced by producer> // and consumer The free index points to> // the next free index. The full index points to> // the first full index.> std::atomic<>int>>free_index(0);> std::atomic<>int>>full_index(0);> std::mutex mtx;> void> producer() {> >item new_item;> >while> (>true>) {> >// Produce the item> >// ...> >std::this_thread::sleep_for(std::chrono::milliseconds(100));> >// Add the item to the buffer> >while> (((free_index + 1) mod buff_max) == full_index) {> >// Buffer is full, wait for consumer> >std::this_thread::sleep_for(std::chrono::milliseconds(100));> >}> >mtx.lock();> >// Add the item to the buffer> >// shared_buff[free_index] = new_item;> >free_index = (free_index + 1) mod buff_max;> >mtx.unlock();> >}> }> void> consumer() {> >item consumed_item;> >while> (>true>) {> >while> (free_index == full_index) {> >// Buffer is empty, wait for producer> >std::this_thread::sleep_for(std::chrono::milliseconds(100));> >}> >mtx.lock();> >// Consume the item from the buffer> >// consumed_item = shared_buff[full_index];> >full_index = (full_index + 1) mod buff_max;> >mtx.unlock();> >// Consume the item> >// ...> >std::this_thread::sleep_for(std::chrono::milliseconds(100));> >}> }> int> main() {> >// Create producer and consumer threads> >std::vectorthread>tråder; threads.emplace_back(produsent); threads.emplace_back(forbruker); // Vent til trådene er ferdige for (auto& thread : threads) { thread.join(); } returner 0; }> |
>
>
round robin planleggingsalgoritme
Merk at atomklassen brukes til å sørge for at de delte variablene free_index og full_index oppdateres atomisk. Mutex brukes til å beskytte den kritiske delen der den delte bufferen er tilgjengelig. Sleep_for-funksjonen brukes til å simulere produksjon og forbruk av varer.
ii) Metode for å sende meldinger
Nå vil vi starte vår diskusjon om kommunikasjonen mellom prosesser via meldingsoverføring. I denne metoden kommuniserer prosesser med hverandre uten å bruke noen form for delt minne. Hvis to prosesser p1 og p2 ønsker å kommunisere med hverandre, fortsetter de som følger:
- Etabler en kommunikasjonskobling (hvis en kobling allerede eksisterer, trenger du ikke å etablere den på nytt.)
- Begynn å utveksle meldinger ved å bruke grunnleggende primitiver.
Vi trenger minst to primitiver:
– sende (melding, destinasjon) eller sende (beskjed)
– motta (melding, vert) eller motta (beskjed)

Meldingsstørrelsen kan være av fast størrelse eller variabel størrelse. Hvis det er av fast størrelse, er det enkelt for en OS-designer, men komplisert for en programmerer, og hvis det er av variabel størrelse, er det enkelt for en programmerer, men komplisert for OS-designeren. En standardmelding kan ha to deler: topptekst og brødtekst.
De header del brukes til å lagre meldingstype, destinasjons-ID, kilde-ID, meldingslengde og kontrollinformasjon. Kontrollinformasjonen inneholder informasjon som hva du skal gjøre hvis det går tom for bufferplass, sekvensnummer, prioritet. Vanligvis sendes melding med FIFO-stil.
Melding går gjennom kommunikasjonskobling.
Direkte og indirekte kommunikasjonskobling
Nå vil vi starte vår diskusjon om metodene for å implementere kommunikasjonskoblinger. Når du implementerer koblingen, er det noen spørsmål som må huskes som:
- Hvordan etableres koblinger?
- Kan en kobling knyttes til mer enn to prosesser?
- Hvor mange koblinger kan det være mellom hvert par kommunikasjonsprosesser?
- Hva er kapasiteten til en kobling? Er størrelsen på en melding som koblingen kan romme fast eller variabel?
- Er en kobling ensrettet eller toveis?
En lenke har en viss kapasitet som bestemmer antallet meldinger som kan ligge i den midlertidig, for hvilke hver lenke har en kø knyttet til seg som kan ha null kapasitet, begrenset kapasitet eller ubegrenset kapasitet. I null kapasitet venter avsender til mottaker informerer avsender om at den har mottatt meldingen. I tilfeller som ikke er null, vet ikke en prosess om en melding er mottatt eller ikke etter sendeoperasjonen. For dette må avsenderen kommunisere eksplisitt med mottakeren. Implementering av koblingen avhenger av situasjonen, det kan enten være en direkte kommunikasjonskobling eller en in-rettet kommunikasjonskobling.
Direkte kommunikasjonskoblinger implementeres når prosessene bruker en spesifikk prosessidentifikator for kommunikasjonen, men det er vanskelig å identifisere avsenderen på forhånd.
For eksempel utskriftsserveren.
Indirekte kommunikasjon gjøres via en delt postkasse (port), som består av en kø med meldinger. Avsenderen oppbevarer meldingen i postkassen og mottakeren henter dem.
Melding går gjennom utveksling av meldinger.
Synkron og asynkron meldingsoverføring:
En prosess som er blokkert er en prosess som venter på en hendelse, for eksempel at en ressurs blir tilgjengelig eller fullføring av en I/O-operasjon. IPC er mulig mellom prosessene på samme datamaskin så vel som på prosessene som kjører på forskjellige datamaskiner, dvs. i nettverk/distribuert system. I begge tilfeller kan det hende at prosessen blokkeres mens du sender en melding eller forsøker å motta en melding, slik at sending av meldinger kan være blokkerende eller ikke-blokkerende. Blokkering vurderes synkron og blokkerer sending betyr at avsenderen vil bli blokkert inntil meldingen er mottatt av mottakeren. På samme måte, blokkere mottak har mottakeren blokkert til en melding er tilgjengelig. Ikke-blokkering vurderes asynkron og Ikke-blokkerende send har avsenderen sender meldingen og fortsetter. På samme måte har ikke-blokkerende mottak at mottakeren mottar en gyldig melding eller null. Etter en nøye analyse kan vi komme til en konklusjon at for en avsender er det mer naturlig å være ikke-blokkerende etter meldingspassering da det kan være behov for å sende meldingen til ulike prosesser. Avsenderen forventer imidlertid en bekreftelse fra mottakeren i tilfelle sendingen mislykkes. Tilsvarende er det mer naturlig for en mottaker å blokkere etter å ha utstedt mottaket, da informasjonen fra den mottatte meldingen kan brukes til videre utførelse. Samtidig, hvis meldingen fortsetter å mislykkes, må mottakeren vente på ubestemt tid. Derfor vurderer vi også den andre muligheten for meldingsoverføring. Det er i hovedsak tre foretrukne kombinasjoner:
- Blokkering av sending og blokkering av mottak
- Ikke-blokkerende send og ikke-blokkerende mottak
- Ikke-blokkerende sending og blokkerende mottak (mest brukt)
I Direkte melding passerer , Prosessen som ønsker å kommunisere må eksplisitt navngi mottakeren eller avsenderen av kommunikasjonen.
f.eks. send(p1, melding) betyr å sende meldingen til p1.
På samme måte, motta(p2, melding) betyr å motta meldingen fra p2.
I denne kommunikasjonsmetoden etableres kommunikasjonskoblingen automatisk, som kan være enten ensrettet eller toveis, men én kobling kan brukes mellom ett par av sender og mottaker og ett par av sender og mottaker bør ikke ha mer enn ett par av lenker. Symmetri og asymmetri mellom sending og mottak kan også implementeres, dvs. enten vil begge prosessene navngi hverandre for å sende og motta meldingene eller bare avsenderen vil navngi mottakeren for å sende meldingen og det er ikke behov for mottakeren for å navngi avsenderen for mottar meldingen. Problemet med denne kommunikasjonsmetoden er at hvis navnet på en prosess endres, vil ikke denne metoden fungere.
I Indirekte melding passerer , bruker prosesser postbokser (også referert til som porter) for å sende og motta meldinger. Hver postboks har en unik id og prosesser kan bare kommunisere hvis de deler en postboks. Kobling opprettes bare hvis prosesser deler en felles postboks og en enkelt link kan knyttes til mange prosesser. Hvert prosesspar kan dele flere kommunikasjonslenker, og disse koblingene kan være ensrettet eller toveis. Anta at to prosesser ønsker å kommunisere gjennom indirekte meldingsoverføring, de nødvendige operasjonene er: opprette en postkasse, bruk denne postkassen til å sende og motta meldinger, og ødelegg deretter postkassen. Standard primitivene som brukes er: Send en melding) som betyr send meldingen til postkasse A. Det primitive for å motta meldingen fungerer også på samme måte f.eks. mottatt (A, melding) . Det er et problem med denne postboksimplementeringen. Anta at det er mer enn to prosesser som deler samme postkasse og anta at prosessen p1 sender en melding til postkassen, hvilken prosess vil være mottakeren? Dette kan løses ved enten å håndheve at bare to prosesser kan dele en enkelt postboks eller håndheve at bare én prosess har lov til å utføre mottaket på et gitt tidspunkt eller velge en tilfeldig prosess og varsle avsenderen om mottakeren. En postkasse kan gjøres privat for et enkelt sender/mottaker-par og kan også deles mellom flere avsender/mottaker-par. Port er en implementering av en slik postboks som kan ha flere avsendere og en enkelt mottaker. Den brukes i klient/serverapplikasjoner (i dette tilfellet er serveren mottakeren). Porten eies av mottaksprosessen og opprettes av OS på forespørsel fra mottakerprosessen og kan ødelegges enten på forespørsel fra samme mottakerprosessor når mottakeren avslutter seg selv. Å håndheve at bare én prosess er tillatt for å utføre mottaket kan gjøres ved å bruke konseptet gjensidig ekskludering. Mutex postkasse opprettes som deles av n prosess. Avsenderen er ikke-blokkerende og sender meldingen. Den første prosessen som utfører mottaket vil gå inn i den kritiske delen og alle andre prosesser vil blokkere og vente.
La oss nå diskutere produsent-forbruker-problemet ved å bruke konseptet for meldingsoverføring. Produsenten legger varer (inne i meldinger) i postkassen og forbrukeren kan konsumere en vare når minst én melding er i postkassen. Koden er gitt nedenfor:
Produsentkode
C
void> Producer(>void>){> > >int> item;> >Message m;> > >while>(1){> > >receive(Consumer, &m);> >item = produce();> >build_message(&m , item ) ;> >send(Consumer, &m);> >}> >}> |
>
>
Forbrukerkode
C
void> Consumer(>void>){> > >int> item;> >Message m;> > >while>(1){> > >receive(Producer, &m);> >item = extracted_item();> >send(Producer, &m);> >consume_item(item);> >}> >}> |
>
>
Eksempler på IPC-systemer
- Posix : bruker metode for delt minne.
- Mach : bruker meldingsoverføring
- Windows XP : bruker meldingsoverføring ved hjelp av lokale prosedyreanrop
Kommunikasjon i klient/serverarkitektur:
Det er forskjellige mekanismer:
- Rør
- Stikkontakt
- Remote Procedural Calls (RPCs)
De tre ovennevnte metodene vil bli diskutert i senere artikler, da alle er ganske konseptuelle og fortjener sine egne separate artikler.
Referanser:
- Operativsystemkonsepter av Galvin et al.
- Forelesningsnotater/ppt av Ariel J. Frank, Bar-Ilan University
Interprosesskommunikasjon (IPC) er mekanismen der prosesser eller tråder kan kommunisere og utveksle data med hverandre på en datamaskin eller over et nettverk. IPC er et viktig aspekt ved moderne operativsystemer, siden det gjør det mulig for ulike prosesser å fungere sammen og dele ressurser, noe som fører til økt effektivitet og fleksibilitet.
Fordeler med IPC:
- Gjør det mulig for prosesser å kommunisere med hverandre og dele ressurser, noe som fører til økt effektivitet og fleksibilitet.
- Forenkler koordinering mellom flere prosesser, noe som fører til bedre total systemytelse.
- Gjør det mulig å lage distribuerte systemer som kan spenne over flere datamaskiner eller nettverk.
- Kan brukes til å implementere ulike synkroniserings- og kommunikasjonsprotokoller, for eksempel semaforer, rør og stikkontakter.
Ulemper med IPC:
- Øker systemets kompleksitet, noe som gjør det vanskeligere å designe, implementere og feilsøke.
- Kan introdusere sikkerhetssårbarheter, da prosesser kan være i stand til å få tilgang til eller endre data som tilhører andre prosesser.
- Krever nøye styring av systemressurser, som minne og CPU-tid, for å sikre at IPC-operasjoner ikke forringer den generelle systemytelsen.
Kan føre til datainkonsekvenser hvis flere prosesser prøver å få tilgang til eller endre de samme dataene samtidig. - Totalt sett oppveier fordelene med IPC ulempene, da det er en nødvendig mekanisme for moderne operativsystemer og gjør at prosesser kan fungere sammen og dele ressurser på en fleksibel og effektiv måte. Imidlertid må man passe på å designe og implementere IPC-systemer nøye, for å unngå potensielle sikkerhetssårbarheter og ytelsesproblemer.
Mer referanse:
http://nptel.ac.in/courses/106108101/pdf/Lecture_Notes/Mod%207_LN.pdf
https://www.youtube.com/watch?v=lcRqHwIn5Dk