I den virkelige verden maskinlæring applikasjoner er det vanlig å ha mange relevante funksjoner, men bare en delmengde av dem kan observeres. Når man arbeider med variabler som noen ganger er observerbare og noen ganger ikke, er det faktisk mulig å bruke forekomstene når den variabelen er synlig eller observert for å lære og lage spådommer for de tilfellene der den ikke er observerbar. Denne tilnærmingen blir ofte referert til som håndtering av manglende data. Ved å bruke de tilgjengelige tilfellene der variabelen er observerbar, kan maskinlæringsalgoritmer lære mønstre og relasjoner fra de observerte dataene. Disse lærte mønstrene kan deretter brukes til å forutsi verdiene til variabelen i tilfeller der den mangler eller ikke kan observeres.
Forventningsmaksimeringsalgoritmen kan brukes til å håndtere situasjoner der variabler er delvis observerbare. Når visse variabler er observerbare, kan vi bruke disse forekomstene til å lære og estimere verdiene deres. Deretter kan vi forutsi verdiene til disse variablene i tilfeller når det ikke er observerbart.
EM-algoritmen ble foreslått og navngitt i en banebrytende artikkel publisert i 1977 av Arthur Dempster, Nan Laird og Donald Rubin. Arbeidet deres formaliserte algoritmen og demonstrerte dens nytte i statistisk modellering og estimering.
EM-algoritmen kan brukes på latente variabler, som er variabler som ikke er direkte observerbare, men som er utledet fra verdiene til andre observerte variabler. Ved å utnytte den kjente generelle formen for sannsynlighetsfordelingen som styrer disse latente variablene, kan EM-algoritmen forutsi verdiene deres.
EM-algoritmen fungerer som grunnlaget for mange uovervåkede klyngealgoritmer innen maskinlæring. Det gir et rammeverk for å finne de lokale maksimal sannsynlighetsparametrene for en statistisk modell og utlede latente variabler i tilfeller der data mangler eller er ufullstendige.
Forventningsmaksimering (EM) Algoritme
Forventningsmaksimeringsalgoritmen (EM) er en iterativ optimaliseringsmetode som kombinerer forskjellige uovervåkede maskinlæring algoritmer for å finne maksimal sannsynlighet eller maksimale posteriore estimater av parametere i statistiske modeller som involverer uobserverte latente variabler. EM-algoritmen brukes ofte for latente variable modeller og kan håndtere manglende data. Den består av et estimeringstrinn (E-trinn) og et maksimeringstrinn (M-trinn), som danner en iterativ prosess for å forbedre modelltilpasningen.
- I E-trinnet beregner algoritmen de latente variablene, dvs. forventningen til log-sannsynligheten ved å bruke gjeldende parameterestimater.
- I M-trinnet bestemmer algoritmen parametrene som maksimerer den forventede log-sannsynligheten oppnådd i E-trinnet, og tilsvarende modellparametere oppdateres basert på de estimerte latente variablene.

Forventningsmaksimering i EM-algoritme
Ved iterativt å gjenta disse trinnene, søker EM-algoritmen å maksimere sannsynligheten for de observerte dataene. Det brukes ofte til uovervåkede læringsoppgaver, for eksempel clustering, der latente variabler utledes og har applikasjoner på forskjellige felt, inkludert maskinlæring, datasyn og naturlig språkbehandling.
Nøkkelord i algoritmen for forventningsmaksimering (EM).
Noen av de mest brukte nøkkelbegrepene i Expectation-Maximization (EM) Algorithm er som følger:
- Latente variabler: Latente variabler er uobserverte variabler i statistiske modeller som bare kan utledes indirekte gjennom deres effekter på observerbare variabler. De kan ikke måles direkte, men kan oppdages ved deres innvirkning på de observerbare variablene. Sannsynlighet: Det er sannsynligheten for å observere de gitte dataene gitt parameterne til modellen. I EM-algoritmen er målet å finne parametrene som maksimerer sannsynligheten. Log-Likelihood: Det er logaritmen til likelihood-funksjonen, som måler god tilpasning mellom de observerte dataene og modellen. EM-algoritmen søker å maksimere loggsannsynligheten. Maximum Likelihood Estimation (MLE): MLE er en metode for å estimere parametrene til en statistisk modell ved å finne parameterverdiene som maksimerer likelihood-funksjonen, som måler hvor godt modellen forklarer de observerte dataene. Posterior sannsynlighet : I sammenheng med Bayesiansk inferens kan EM-algoritmen utvides til å estimere maksimale a posteriori (MAP) estimater, der den bakre sannsynligheten for parametrene beregnes basert på den tidligere fordelingen og sannsynlighetsfunksjonen. Forventningstrinn (E) : E-steget til EM-algoritmen beregner forventet verdi eller posterior sannsynlighet for de latente variablene gitt de observerte dataene og gjeldende parameterestimater. Det innebærer å beregne sannsynlighetene for hver latente variabel for hvert datapunkt. Maksimering (M) trinn: M-trinnet til EM-algoritmen oppdaterer parameterestimatene ved å maksimere den forventede log-sannsynligheten oppnådd fra E-trinnet. Det innebærer å finne parameterverdiene som optimerer sannsynlighetsfunksjonen, typisk gjennom numeriske optimaliseringsmetoder. Konvergens: Konvergens refererer til tilstanden når EM-algoritmen har nådd en stabil løsning. Det bestemmes vanligvis ved å sjekke om endringen i log-sannsynligheten eller parameterestimatene faller under en forhåndsdefinert terskel.
Slik fungerer algoritmen for forventningsmaksimering (EM):
Essensen av Expectation-Maximization-algoritmen er å bruke de tilgjengelige observerte dataene i datasettet for å estimere de manglende dataene og deretter bruke disse dataene til å oppdatere verdiene til parameterne. La oss forstå EM-algoritmen i detalj.
EM Algoritme flytskjema
- Initialisering:
- Til å begynne med vurderes et sett med startverdier for parameterne. Et sett med ufullstendige observerte data blir gitt til systemet med antagelsen om at de observerte dataene kommer fra en spesifikk modell.
- Beregn den bakre sannsynligheten eller ansvaret for hver latente variabel gitt de observerte dataene og gjeldende parameterestimater.
- Estimer de manglende eller ufullstendige dataverdiene ved å bruke gjeldende parameteranslag.
- Beregn loggsannsynligheten for de observerte dataene basert på gjeldende parameterestimater og estimerte manglende data.
- Oppdater parametrene til modellen ved å maksimere forventet fullstendig dataloggsannsynlighet hentet fra E-steget.
- Dette innebærer vanligvis å løse optimaliseringsproblemer for å finne parameterverdiene som maksimerer loggsannsynligheten.
- Den spesifikke optimaliseringsteknikken som brukes, avhenger av problemets art og modellen som brukes.
- Sjekk for konvergens ved å sammenligne endringen i log-sannsynligheten eller parameterverdiene mellom iterasjoner.
- Hvis endringen er under en forhåndsdefinert terskel, stopp og betrakt algoritmen som konvergert.
- Ellers går du tilbake til E-trinn og gjentar prosessen til konvergens er oppnådd.
Forventningsmaksimeringsalgoritme trinnvis implementering
Importer de nødvendige bibliotekene
Python3
import> numpy as np> import> matplotlib.pyplot as plt> from> scipy.stats>import> norm> |
>
>
Generer et datasett med to gaussiske komponenter
Python3
# Generate a dataset with two Gaussian components> mu1, sigma1>=> 2>,>1> mu2, sigma2>=> ->1>,>0.8> X1>=> np.random.normal(mu1, sigma1, size>=>200>)> X2>=> np.random.normal(mu2, sigma2, size>=>600>)> X>=> np.concatenate([X1, X2])> # Plot the density estimation using seaborn> sns.kdeplot(X)> plt.xlabel(>'X'>)> plt.ylabel(>'Density'>)> plt.title(>'Density Estimation of X'>)> plt.show()> |
>
>
Produksjon :
Tetthet Plot
Initialiser parametere
Python3
# Initialize parameters> mu1_hat, sigma1_hat>=> np.mean(X1), np.std(X1)> mu2_hat, sigma2_hat>=> np.mean(X2), np.std(X2)> pi1_hat, pi2_hat>=> len>(X1)>/> len>(X),>len>(X2)>/> len>(X)> |
>
>
Utfør EM-algoritme
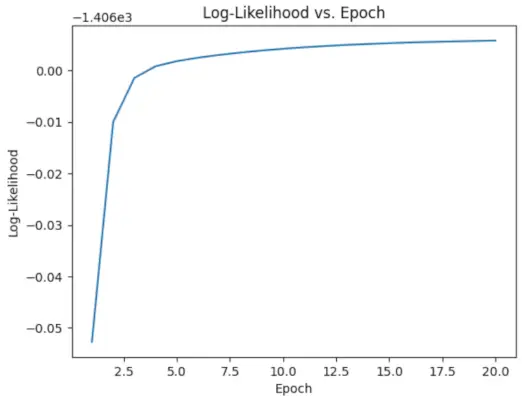
- Itererer for det angitte antallet epoker (20 i dette tilfellet).
- I hver epoke beregner E-steget ansvar (gammaverdier) ved å evaluere de Gaussiske sannsynlighetstetthetene for hver komponent og vekte dem med de tilsvarende proporsjonene.
- M-steget oppdaterer parameterne ved å beregne vektet gjennomsnitt og standardavvik for hver komponent
Python3
# Perform EM algorithm for 20 epochs> num_epochs>=> 20> log_likelihoods>=> []> for> epoch>in> range>(num_epochs):> ># E-step: Compute responsibilities> >gamma1>=> pi1_hat>*> norm.pdf(X, mu1_hat, sigma1_hat)> >gamma2>=> pi2_hat>*> norm.pdf(X, mu2_hat, sigma2_hat)> >total>=> gamma1>+> gamma2> >gamma1>/>=> total> >gamma2>/>=> total> > ># M-step: Update parameters> >mu1_hat>=> np.>sum>(gamma1>*> X)>/> np.>sum>(gamma1)> >mu2_hat>=> np.>sum>(gamma2>*> X)>/> np.>sum>(gamma2)> >sigma1_hat>=> np.sqrt(np.>sum>(gamma1>*> (X>-> mu1_hat)>*>*>2>)>/> np.>sum>(gamma1))> >sigma2_hat>=> np.sqrt(np.>sum>(gamma2>*> (X>-> mu2_hat)>*>*>2>)>/> np.>sum>(gamma2))> >pi1_hat>=> np.mean(gamma1)> >pi2_hat>=> np.mean(gamma2)> > ># Compute log-likelihood> >log_likelihood>=> np.>sum>(np.log(pi1_hat>*> norm.pdf(X, mu1_hat, sigma1_hat)> >+> pi2_hat>*> norm.pdf(X, mu2_hat, sigma2_hat)))> >log_likelihoods.append(log_likelihood)> # Plot log-likelihood values over epochs> plt.plot(>range>(>1>, num_epochs>+>1>), log_likelihoods)> plt.xlabel(>'Epoch'>)> plt.ylabel(>'Log-Likelihood'>)> plt.title(>'Log-Likelihood vs. Epoch'>)> plt.show()> |
>
>
Produksjon :
Epoke vs Logg-sannsynlighet
Plott den endelige estimerte tettheten
Python3
# Plot the final estimated density> X_sorted>=> np.sort(X)> density_estimation>=> pi1_hat>*>norm.pdf(X_sorted,> >mu1_hat,> >sigma1_hat)>+> pi2_hat>*> norm.pdf(X_sorted,> >mu2_hat,> >sigma2_hat)> plt.plot(X_sorted, gaussian_kde(X_sorted)(X_sorted), color>=>'green'>, linewidth>=>2>)> plt.plot(X_sorted, density_estimation, color>=>'red'>, linewidth>=>2>)> plt.xlabel(>'X'>)> plt.ylabel(>'Density'>)> plt.title(>'Density Estimation of X'>)> plt.legend([>'Kernel Density Estimation'>,>'Mixture Density'>])> plt.show()> |
>
edith mack hirsch
>
Produksjon :
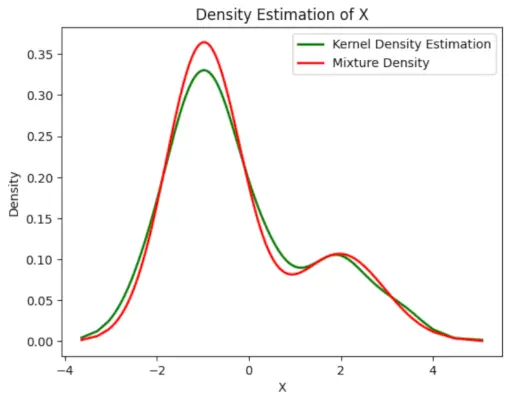
Estimert tetthet
Søknader av EM algoritme
- Den kan brukes til å fylle ut manglende data i en prøve.
- Den kan brukes som grunnlag for uovervåket læring av klynger.
- Den kan brukes til å estimere parametrene til Hidden Markov Model (HMM).
- Den kan brukes til å oppdage verdiene til latente variabler.
Fordeler med EM-algoritme
- Det er alltid garantert at sannsynligheten vil øke med hver iterasjon.
- E-steget og M-steget er ofte ganske enkelt for mange problemer når det gjelder implementering.
- Løsninger på M-trinnene finnes ofte i lukket form.
Ulemper med EM-algoritme
- Den har langsom konvergens.
- Det gjør kun konvergens til det lokale optima.
- Det krever både sannsynlighetene, fremover og bakover (numerisk optimalisering krever bare foroversannsynlighet).