- dnorm()
dnorm(x, mean, sd)>pnorm()
pnorm(x, mean, sd)>qnorm()
qnorm(p, mean, sd)>rnorm()
rnorm(n, mean, sd)>hvor,
– x representerer datasettet med verdier – gjennomsnitt (x) representerer gjennomsnittet av datasettet x . Dens standardverdi er 0.>– sd(x) representerer standardavviket til datasettet x . Dens standardverdi er 1.>– n er antall observasjoner. – s er vektor av sannsynligheter
Funksjoner for å generere normalfordeling i R
dnorm()
dnorm()> funksjon i R programmering måler tetthet funksjon av distribusjon. I statistikk måles det med formelen nedenfor->hvor,
 er slem og
er slem og 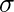 er standardavvik. Syntaks:
er standardavvik. Syntaks: dnorm(x, mean, sd)>Eksempel:
# creating a sequence of values> # between -15 to 15 with a difference of 0.1> x>=> seq(>->15>,>15>, by>=>0.1>)> > y>=> dnorm(x, mean(x), sd(x))> > # output to be present as PNG file> png(>file>=>'dnormExample.webp'>)> > # Plot the graph.> plot(x, y)> > # saving the file> dev.off()> |
>
>Produksjon:
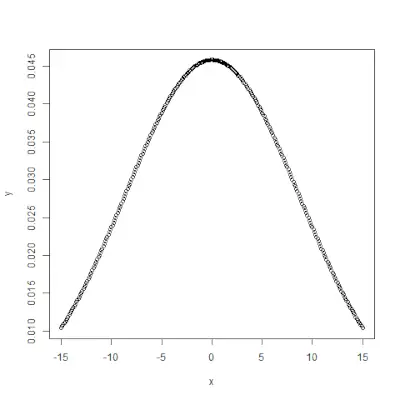
pnorm()
pnorm()> funksjon er den kumulative fordelingsfunksjonen som måler sannsynligheten for at et tilfeldig tall X tar en verdi mindre enn eller lik x, dvs. i statistikk er det gitt av->Syntaks:
pnorm(x, mean, sd)>Eksempel:
# creating a sequence of values> # between -10 to 10 with a difference of 0.1> x <>-> seq(>->10>,>10>, by>=>0.1>)> > y <>-> pnorm(x, mean>=> 2.5>, sd>=> 2>)> > # output to be present as PNG file> png(>file>=>'pnormExample.webp'>)> > # Plot the graph.> plot(x, y)> > # saving the file> dev.off()> |
>
>Utgang:
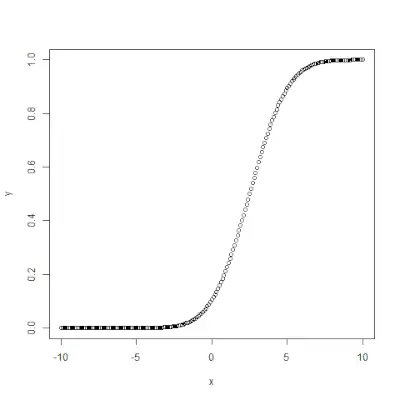
qnorm()
qnorm()> funksjon er det motsatte av pnorm()>funksjon. Den tar sannsynlighetsverdien og gir utdata som tilsvarer sannsynlighetsverdien. Det er nyttig for å finne persentilene til en normalfordeling. Syntaks: qnorm(p, mean, sd)>Eksempel:
# Create a sequence of probability values> # incrementing by 0.02.> x <>-> seq(>0>,>1>, by>=> 0.02>)> > y <>-> qnorm(x, mean(x), sd(x))> > # output to be present as PNG file> png(>file> => 'qnormExample.webp'>)> > # Plot the graph.> plot(x, y)> > # Save the file.> dev.off()> |
>
>Produksjon:
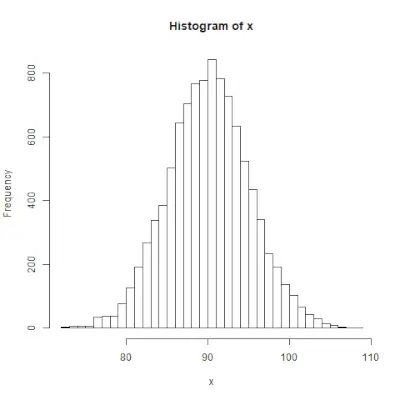
rnorm()
rnorm()> funksjon i R-programmering brukes til å generere en vektor av tilfeldige tall som er normalfordelt. Syntaks: rnorm(x, mean, sd)>Eksempel:
# Create a vector of 1000 random numbers> # with mean=90 and sd=5> x <>-> rnorm(>10000>, mean>=>90>, sd>=>5>)> > # output to be present as PNG file> png(>file> => 'rnormExample.webp'>)> > # Create the histogram with 50 bars> hist(x, breaks>=>50>)> > # Save the file.> dev.off()> |
>
>Utgang: