Pandaer dataframe.corr() brukes til å finne den parvise korrelasjonen til alle kolonnene i Pandas Dataframe i Python. Noen NaN verdier blir automatisk ekskludert. For å ignorere eventuelle ikke-numeriske verdier, bruk parameteren numeric_only = True. I denne artikkelen vil vi lære om DataFrame.corr()-metoden i Python .
Pandas DataFrame corr() Metodesyntaks
Syntaks: DataFrame.corr(self, method='pearson', min_periods=1, numeric_only = False)
Parametere:
- metode:
- pearson: standard korrelasjonskoeffisient
- kendall: Kendall Tau korrelasjonskoeffisient
- spearman: Spearman rang korrelasjon
- min_perioder : Minimum antall observasjoner som kreves per kolonnepar for å ha et gyldig resultat. Foreløpig bare tilgjengelig for pearson- og spearman-korrelasjon
- numeric_only : Om bare de numeriske verdiene skal brukes eller ikke. Den er satt til False som standard.
Returnerer: count :y : DataFrame
røye til streng
Pandas Data Correlations corr() Metode
En god korrelasjon avhenger av bruken, men det er trygt å si at du har minst 0,6 (eller -0,6) for å kalle det en god korrelasjon. Et enkelt eksempel for å vise hvordan korrelasjon fungerer i Python .
Python3
import> pandas as pd> df>=> {> >'Array_1'>: [>30>,>70>,>100>],> >'Array_2'>: [>65.1>,>49.50>,>30.7>]> }> data>=> pd.DataFrame(df)> print>(data.corr())> |
>
>
Produksjon
Array_1 Array_2 Array_1 1.000000 -0.990773 Array_2 -0.990773 1.000000>
Opprette prøvedataramme
Skriver ut de første 10 radene i Dataframe.
Merk: Korrelasjonen til en variabel med seg selv er 1. For en lenke til CSV-filen Brukt i kode, klikk her
Python3
rund matematikk java
# importing pandas as pd> import> pandas as pd> # Making data frame from the csv file> df>=> pd.read_csv(>'nba.csv'>)> # Printing the first 10 rows of the data frame for visualization> df[:>10>]> |
>
>
Produksjon

Python Pandas DataFrame corr() Metodeeksempler
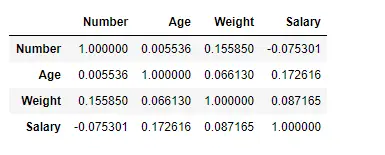
Finn korrelasjon mellom kolonnene ved å bruke pearson-metoden
Her bruker vi corr()-funksjonen for å finne korrelasjonen mellom kolonnene i datarammen ved å bruke 'Pearson'-metoden. Vi har bare fire numeriske kolonner i datarammen. Utdatadatarammen kan tolkes som for en hvilken som helst celle, radvariabelkorrelasjon med kolonnevariabelen er verdien av cellen. Som nevnt tidligere er korrelasjonen til en variabel med seg selv 1. Av den grunn er alle diagonalverdiene 1,00.
Python3
hvor mange null for en million
# To find the correlation among> # the columns using pearson method> df.corr(method>=>'pearson'>)> |
>
>
Produksjon
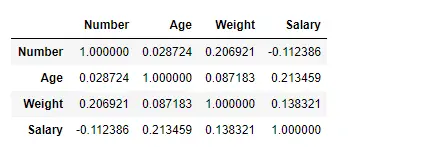
Finn korrelasjon mellom kolonnene ved å bruke Kendall-metoden
Bruk Pandas df.corr()-funksjonen for å finne korrelasjonen mellom kolonnene i datarammen ved å bruke ‘kendall’-metoden. Utdatadatarammen kan tolkes som for en hvilken som helst celle, radvariabelkorrelasjon med kolonnevariabelen er verdien av cellen. Som nevnt tidligere er korrelasjonen til en variabel med seg selv 1. Av den grunn er alle diagonalverdiene 1,00.
Python3
# importing pandas as pd> import> pandas as pd> # Making data frame from the csv file> df>=> pd.read_csv(>'nba.csv'>)> # To find the correlation among> # the columns using kendall method> df.corr(method>=>'kendall'>)> |
javascript trim
>
>
Produksjon