Python er et flott språk for å gjøre dataanalyse, først og fremst på grunn av det fantastiske økosystemet med datasentrisk Python pakker. Pandaer er en av disse pakkene og gjør import og analyse av data mye enklere.
Pandas DataFrame mean()
Pandaer dataframe.mean() funksjonen returnerer gjennomsnittet av verdiene for den forespurte aksen. Hvis metoden brukes på et pandaserieobjekt, returnerer metoden en skalarverdi som er middelverdien av alle observasjonene i Pandas dataramme . Hvis metoden brukes på et Pandas Dataframe-objekt, returnerer metoden en Panda-serien objekt som inneholder gjennomsnittet av verdiene over den angitte aksen.
Syntaks: DataFrame.mean(axis=0, skipna=True, level=None, numeric_only=False, **kwargs)
Parametere:
- akse: {indeks (0), kolonner (1)}
- rekkefølge : Ekskluder NA/null-verdier ved beregning av resultatet
- nivå: Hvis aksen er en multiindeks (hierarkisk), tell langs et bestemt nivå og kollapser til en serie
- numeric_only : Inkluder bare float, int, booleske kolonner. Hvis Ingen, vil forsøke å bruke alt, bruk kun numeriske data. Ikke implementert for serier.
Returnerer: betyr: Series eller DataFrame (hvis nivå spesifisert)
matematikk pow java
Pandas DataFrame.mean() Eksempler
Eksempel 1:
Bruk funksjonen mean() for å finne gjennomsnittet av alle observasjonene over indeksaksen.
Python # importing pandas as pd import pandas as pd # Creating the dataframe df = pd.DataFrame({'A':[12, 4, 5, 44, 1], 'B':[5, 2, 54, 3, 2], 'C':[20, 16, 7, 3, 8], 'D':[14, 3, 17, 2, 6]}) # Print the dataframe df> 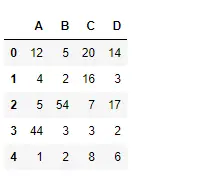
La oss bruke Dataframe.mean()-funksjonen for å finne gjennomsnittet over indeksaksen.
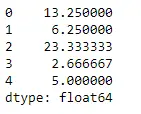
Python # Even if we do not specify axis = 0, # the method will return the mean over # the index axis by default df.mean(axis = 0)>
Produksjon:
Eksempel 2:
Bruk mean()-funksjonen på en dataramme som har ingen verdier. Finn også gjennomsnittet over kolonneaksen.
Python # importing pandas as pd import pandas as pd # Creating the dataframe df = pd.DataFrame({'A':[12, 4, 5, None, 1], 'B':[7, 2, 54, 3, None], 'C':[20, 16, 11, 3, 8], 'D':[14, 3, None, 2, 6]}) # skip the Na values while finding the mean df.mean(axis = 1, skipna = True)> Produksjon: