I operativsystemet måtte vi gi input til CPU, og CPU utfører instruksjonene og gir til slutt utdata. Men det var et problem med denne tilnærmingen. I en normal situasjon må vi forholde oss til mange prosesser, og vi vet at tiden det tar i I/O-operasjonen er veldig stor sammenlignet med tiden CPUen tar for å utføre instruksjonene. Så, i den gamle tilnærmingen, vil en prosess gi input ved hjelp av en inngangsenhet, og i løpet av denne tiden er CPU-en i inaktiv tilstand.
ups i java
Deretter utfører CPU-en instruksjonen, og utgangen blir igjen gitt til en utdataenhet, og på dette tidspunktet er CPU-en også i inaktiv tilstand. Etter å ha vist utdataene, starter neste prosess kjøringen. Så, mesteparten av tiden, er CPU-en inaktiv, som er den verste tilstanden vi kan ha i operativsystemer. Her kommer konseptet Spooling inn i bildet.
Hva er spooling
Spooling er en prosess der data midlertidig holdes for bruk og kjøring av en enhet, et program eller et system. Data sendes til og lagres i minne eller annen flyktig lagring til programmet eller datamaskinen ber om det for utførelse.
SPOOL er et akronym for samtidige perifere operasjoner på nett . Vanligvis opprettholdes spolen på datamaskinens fysiske minne, buffere eller I/O-enhetsspesifikke avbrudd. Spolen behandles i stigende rekkefølge, og fungerer basert på en FIFO (først inn, først ut) algoritme.
Spooling refererer til å legge data fra ulike I/O-jobber i en buffer. Denne bufferen er et spesielt område i minnet eller harddisken som er tilgjengelig for I/O-enheter. Et operativsystem utfører følgende aktiviteter relatert til det distribuerte miljøet:
- Håndterer I/O-enhetsdataspooling ettersom enheter har forskjellige datatilgangshastigheter.
- Opprettholder spoolbufferen, som gir en ventestasjon hvor data kan hvile mens den tregere enheten fanger opp.
- Opprettholder parallell beregning på grunn av spoolprosessen, da en datamaskin kan utføre I/O i parallell rekkefølge. Det blir mulig å få datamaskinen til å lese data fra et bånd, skrive data til disk og skrive ut til en båndskriver mens den gjør sin databehandlingsoppgave.
Hvordan spooling fungerer i operativsystemet
I et operativsystem fungerer spooling i følgende trinn, for eksempel:
- Spooling innebærer å lage en buffer kalt SPOOL, som brukes til å holde tilbake jobber og data til enheten der SPOOL er opprettet er klar til å ta i bruk og utføre den jobben eller operere på dataene.
- Når en raskere enhet sender data til en tregere enhet for å utføre en operasjon, bruker den et hvilket som helst sekundærminne som er koblet til som en SPOOL-buffer. Disse dataene lagres i SPOOL til den tregere enheten er klar til å bruke disse dataene. Når den tregere enheten er klar, blir dataene i SPOOL lastet inn i hovedminnet for de nødvendige operasjonene.
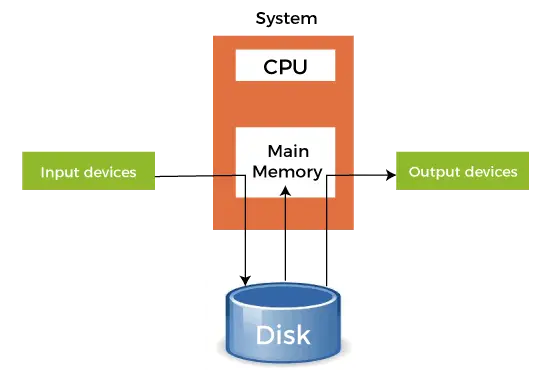
- Spooling anser hele det sekundære minnet som en enorm buffer som kan lagre mange jobber og data for mange operasjoner. Fordelen med spooling er at den kan lage en kø med jobber som kjøres i FIFO-rekkefølge for å utføre jobbene én etter én.
- En enhet kan koble til mange inngangsenheter, noe som kan kreve noe operasjon på dataene deres. Så alle disse inngangsenhetene kan legge dataene sine til det sekundære minnet (SPOOL), som deretter kan kjøres én etter én av enheten. Dette vil sørge for at CPU-en ikke er inaktiv når som helst. Så vi kan si at spooling er en kombinasjon av buffering og kø.
- Etter at CPU genererer noe utdata, lagres denne utgangen først i hovedminnet. Denne utgangen overføres til sekundærminnet fra hovedminnet, og derfra sendes utgangen til de respektive utgangsenhetene.

Eksempel på spole
Det største eksemplet på spooling er printing . Dokumentene som skal skrives ut lagres i SPOOL og legges deretter til utskriftskøen. I løpet av denne tiden kan mange prosesser utføre operasjonene sine og bruke CPU-en uten å vente mens skriveren utfører utskriftsprosessen på dokumentene én etter én.
sql konkat

Mange funksjoner kan også legges til utskriftsprosessen for spooling, som å angi prioriteter eller varsle når utskriftsprosessen er fullført eller å velge de forskjellige papirtypene som skal skrives ut på i henhold til brukerens valg.
Fordeler med spole
Her er følgende fordeler med spooling i et operativsystem, for eksempel:
- Antallet I/O-enheter eller operasjoner spiller ingen rolle. Mange I/O-enheter kan arbeide sammen samtidig uten forstyrrelser eller forstyrrelser for hverandre.
- Ved spooling er det ingen interaksjon mellom I/O-enhetene og CPU-en. Det betyr at det ikke er nødvendig for CPU-en å vente på at I/O-operasjonene skal finne sted. Slike operasjoner tar lang tid å fullføre, så CPU vil ikke vente på at de er ferdige.
- CPU i inaktiv tilstand anses ikke som veldig effektiv. De fleste protokoller er laget for å utnytte CPU-en effektivt på minimum tid. Ved spooling holdes CPU-en opptatt mesteparten av tiden og går bare til inaktiv tilstand når køen er oppbrukt. Så alle oppgavene legges til i køen, og CPU-en vil fullføre alle disse oppgavene og deretter gå inn i inaktiv tilstand.
- Den lar applikasjoner kjøre med CPU-hastigheten mens I/O-enhetene betjenes med deres respektive fulle hastigheter.
Ulemper med spole
I et operativsystem har spooling følgende ulemper, for eksempel:
- Spooling krever en stor mengde lagringsplass avhengig av antall forespørsler fra inngangen og antall tilkoblede inngangsenheter.
- Fordi SPOOL er opprettet i den sekundære lagringen, kan det å ha mange inngangsenheter som jobber samtidig ta opp mye plass på den sekundære lagringen og dermed øke disktrafikken. Dette resulterer i at disken blir tregere og tregere ettersom trafikken øker mer og mer.
- Spooling brukes til å kopiere og kjøre data fra en tregere enhet til en raskere enhet. Den tregere enheten lager en SPOOL for å lagre dataene som skal betjenes i en kø, og CPU-en jobber med den. Denne prosessen i seg selv gjør spooling unyttig å bruke i sanntidsmiljøer der vi trenger sanntidsresultater fra CPU. Dette er fordi inndataenheten er tregere og dermed produserer dataene sine i et langsommere tempo mens CPU-en kan operere raskere, så den går videre til neste prosess i køen. Dette er grunnen til at det endelige resultatet eller utgangen produseres på et senere tidspunkt i stedet for i sanntid.
Forskjellen mellom spooling og buffering
Spooling og buffering er de to måtene I/O-undersystemer forbedrer ytelsen og effektiviteten til datamaskinen ved å bruke en lagringsplass i hovedminnet eller på disken.

Den grunnleggende forskjellen mellom spooling og buffering er at spooling overlapper I/O-en til en jobb med utførelse av en annen jobb. Til sammenligning overlapper bufferingen I/U-en til én jobb med utføringen av den samme jobben. Nedenfor er noen flere forskjeller mellom spooling og buffering, for eksempel:
| Vilkår | Spoling | Bufring |
|---|---|---|
| Definisjon | Spooling, et akronym av Simultaneous Peripheral Operation Online (SPOOL), legger data inn i et midlertidig arbeidsområde som kan åpnes og behandles av et annet program eller en annen ressurs. | Bufring er en handling for å lagre data midlertidig i bufferen. Det hjelper med å matche hastigheten på datastrømmen mellom avsender og mottaker. |
| Ressursbehov | Spooling krever mindre ressursstyring ettersom ulike ressurser styrer prosessen for spesifikke jobber. | Bufring krever mer ressursstyring ettersom den samme ressursen styrer prosessen i den samme delte jobben. |
| Intern gjennomføring | Spooling overlapper input og output fra én jobb med beregningen av en annen jobb. | Bufring overlapper input og output fra én jobb med beregningen av den samme jobben. |
| Effektiv | Spooling er mer effektivt enn buffering. | Bufring er mindre effektivt enn spoling. |
| Prosessor | Spooling kan også behandle data på eksterne steder. Spooleren trenger bare å varsle når en prosess er fullført på den eksterne siden for å spoole neste prosess til den eksterne enheten. | Bufring støtter ikke fjernbehandling. |
| Størrelse på minne | Den anser disken som en stor spole eller buffer. | Buffer er et begrenset område i hovedminnet. |