Uinformert søk er en klasse av generelle søkealgoritmer som opererer på brute force-måte. Uinformerte søkealgoritmer har ikke tilleggsinformasjon om tilstand eller søkerom annet enn hvordan man krysser treet, så det kalles også blindsøk.
Følgende er de ulike typene uinformerte søkealgoritmer:
1. Bredde-først søk:
- Bredde-først-søk er den vanligste søkestrategien for å krysse et tre eller en graf. Denne algoritmen søker i bredden i et tre eller en graf, så det kalles bredde-først-søk.
- BFS-algoritmen begynner å søke fra rotnoden til treet og utvider alle etterfølgende noder på gjeldende nivå før de flyttes til noder på neste nivå.
- Bredde-først-søkealgoritmen er et eksempel på en generell grafsøkealgoritme.
- Bredde-første søk implementert ved hjelp av FIFO-kødatastruktur.
Fordeler:
- BFS vil gi en løsning hvis det finnes en løsning.
- Hvis det er mer enn én løsning for et gitt problem, vil BFS gi den minimale løsningen som krever minst antall trinn.
Ulemper:
- Det krever mye minne siden hvert nivå i treet må lagres i minnet for å utvide neste nivå.
- BFS trenger mye tid hvis løsningen er langt unna rotnoden.
Eksempel:
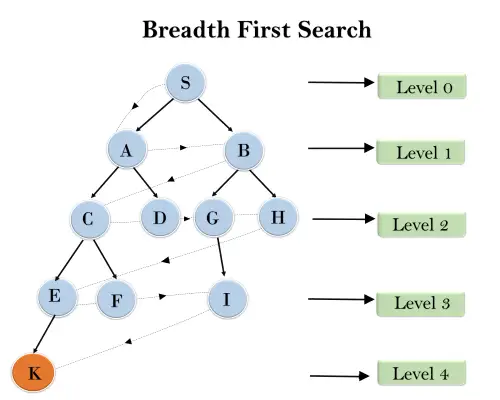
I trestrukturen nedenfor har vi vist kryssingen av treet ved hjelp av BFS-algoritmen fra rotnoden S til målnoden K. BFS-søkealgoritmen går i lag, så den vil følge banen som vises av den stiplede pilen, og krysset sti vil være:
S---> A--->B---->C--->D---->G--->H--->E---->F---->I---->K
Tidskompleksitet: Tidskompleksiteten til BFS-algoritmen kan oppnås ved antall noder som krysses i BFS til den grunneste noden. Der d = dybden til grunneste løsning og b er en node i hver tilstand.
T (b) = 1+b2+b3+......+ bd= O (bd)
matematikk.tilfeldig java
Plass kompleksitet: Romkompleksiteten til BFS-algoritmen er gitt av minnestørrelsen på grensen som er O(bd).
Fullstendighet: BFS er fullført, noe som betyr at hvis den grunneste målnoden er på en begrenset dybde, vil BFS finne en løsning.
Optimalitet: BFS er optimal hvis banekostnaden er en ikke-avtagende funksjon av dybden til noden.
2. Dybde-først søk
- Dybde-først-søk er en rekursiv algoritme for å krysse et tre eller en grafdatastruktur.
- Det kalles dybde-først-søket fordi det starter fra rotnoden og følger hver sti til dens største dybdenod før den går til neste bane.
- DFS bruker en stabeldatastruktur for implementeringen.
- Prosessen til DFS-algoritmen ligner på BFS-algoritmen.
Merk: Backtracking er en algoritmeteknikk for å finne alle mulige løsninger ved hjelp av rekursjon.
Fordel:
- DFS krever svært mindre minne da den bare trenger å lagre en stabel av nodene på banen fra rotnoden til den nåværende noden.
- Det tar kortere tid å nå målnoden enn BFS-algoritmen (hvis den går i riktig vei).
Ulempe:
- Det er mulighet for at mange stater fortsetter å oppstå, og det er ingen garanti for å finne løsningen.
- DFS-algoritmen går for dypt nedsøking, og noen ganger kan den gå til den uendelige sløyfen.
Eksempel:
I søketreet nedenfor har vi vist flyten av dybde-først søk, og den vil følge rekkefølgen som:
Rotnode--->Venstre node ----> høyre node.
Den vil begynne å søke fra rotnoden S, og traversere A, deretter B, deretter D og E, etter å ha krysset E, vil den spore treet tilbake ettersom E ikke har noen annen etterfølger og fortsatt målnoden ikke er funnet. Etter tilbakesporing vil den krysse node C og deretter G, og her vil den avsluttes når den fant målnoden.

Fullstendighet: DFS-søkealgoritmen er komplett innenfor begrenset tilstandsrom, da den vil utvide hver node innenfor et begrenset søketre.
Tidskompleksitet: Tidskompleksiteten til DFS vil tilsvare noden som krysses av algoritmen. Den er gitt av:
T(n)= 1+ n2+ n3+.........+ nm=O(nm)
Hvor, m = maksimal dybde for en hvilken som helst node og denne kan være mye større enn d (grunneste løsningsdybde)
Plass kompleksitet: DFS-algoritmen trenger kun å lagre en enkelt bane fra rotnoden, og romkompleksiteten til DFS er derfor ekvivalent med størrelsen på frynsesettet, som er O(bm) .
Optimal: DFS-søkealgoritmen er ikke optimal, siden den kan generere et stort antall trinn eller høye kostnader for å nå målnoden.
3. Dybdebegrenset søkealgoritme:
En dybdebegrenset søkealgoritme ligner på dybde-først-søk med en forhåndsbestemt grense. Dybdebegrenset søk kan løse ulempen med den uendelige banen i Dybde-først-søket. I denne algoritmen vil noden ved dybdegrensen behandle ettersom den ikke har noen etterfølgernoder videre.
Dybdebegrenset søk kan avsluttes med to betingelser for feil:
- Standard feilverdi: Det indikerer at problemet ikke har noen løsning.
- Cutoff-feilverdi: Den definerer ingen løsning for problemet innenfor en gitt dybdegrense.
Fordeler:
Dybdebegrenset søk er minneeffektivt.
Ulemper:
- Dybdebegrenset søk har også en ulempe med ufullstendighet.
- Det er kanskje ikke optimalt hvis problemet har mer enn én løsning.
Eksempel:

Fullstendighet: DLS-søkealgoritmen er fullført hvis løsningen er over dybdegrensen.
Tidskompleksitet: Tidskompleksiteten til DLS-algoritmen er O(bℓ) .
forskjellen mellom array og arraylist
Plass kompleksitet: Romkompleksiteten til DLS-algoritmen er O (b�ℓ) .
Optimal: Dybdebegrenset søk kan sees på som et spesialtilfelle av DFS, og det er heller ikke optimalt selv om ℓ>d.
4. Søkealgoritme for enhetlige kostnader:
Ensartet kostnadssøk er en søkealgoritme som brukes for å krysse et vektet tre eller en graf. Denne algoritmen kommer inn når en annen kostnad er tilgjengelig for hver kant. Det primære målet med enhetskostnadssøket er å finne en vei til målnoden som har den laveste kumulative kostnaden. Ensartet kostnadssøk utvider noder i henhold til deres banekostnader fra rotnoden. Den kan brukes til å løse enhver graf/tre der den optimale kostnaden er etterspurt. En enhetlig kostnadssøkealgoritme implementeres av prioritetskøen. Det gir maksimal prioritet til den laveste kumulative kostnaden. Ensartet kostnadssøk tilsvarer BFS-algoritmen hvis banekostnaden for alle kanter er den samme.
Fordeler:
- Ensartet kostnadssøk er optimalt fordi banen med minst kostnad velges i hver stat.
Ulemper:
- Den bryr seg ikke om antall trinn som involverer i søk, og er bare bekymret for stikostnadene. På grunn av dette kan denne algoritmen sitte fast i en uendelig sløyfe.
Eksempel:

Fullstendighet:
Ensartet kostnadssøk er fullført, for eksempel hvis det er en løsning, vil UCS finne den.
Tidskompleksitet:
La C* er Kostnad for den optimale løsningen , og e er hvert trinn for å komme nærmere målnoden. Da er antall trinn = C*/ε+1. Her har vi tatt +1, da vi starter fra tilstand 0 og slutter til C*/ε.
Derfor er den verste tidskompleksiteten til Uniform-cost-søk O(b1 + [C*/e])/ .
Plass kompleksitet:
Den samme logikken er for plasskompleksitet, så den verste romkompleksiteten til Uniform-cost-søk er O(b1 + [C*/e]) .
Optimal:
Ensartet kostnadssøk er alltid optimalt ettersom det bare velger en sti med den laveste banekostnaden.
5. Iterativ fordypning-først-søk:
Den iterative fordypningsalgoritmen er en kombinasjon av DFS- og BFS-algoritmer. Denne søkealgoritmen finner ut den beste dybdegrensen og gjør det ved å gradvis øke grensen til et mål er funnet.
java stack
Denne algoritmen utfører dybde-først-søk opp til en viss 'dybdegrense', og den fortsetter å øke dybdegrensen etter hver iterasjon til målnoden er funnet.
Denne søkealgoritmen kombinerer fordelene med Breadth-first-søks raske søk og dybde-først-søks minneeffektivitet.
Den iterative søkealgoritmen er nyttig, uinformert søk når søkeområdet er stort, og dybden til målnoden er ukjent.
Fordeler:
- Den kombinerer fordelene med BFS- og DFS-søkealgoritmer når det gjelder raskt søk og minneeffektivitet.
Ulemper:
- Den største ulempen med IDDFS er at den gjentar alt arbeidet fra forrige fase.
Eksempel:
Følgende trestruktur viser det iterative dybdesøket først. IDDFS-algoritmen utfører forskjellige iterasjoner til den ikke finner målnoden. Iterasjonen utført av algoritmen er gitt som:

1. iterasjon-----> A
2. iterasjon----> A, B, C
3. iterasjon------>A, B, D, E, C, F, G
Fjerde iterasjon------>A, B, D, H, I, E, C, F, K, G
I den fjerde iterasjonen vil algoritmen finne målnoden.
Fullstendighet:
Denne algoritmen er fullført hvis forgreningsfaktoren er endelig.
Tidskompleksitet:
La oss anta at b er forgreningsfaktoren og dybden er d, så er tidskompleksiteten i verste fall O(bd) .
Plass kompleksitet:
Romkompleksiteten til IDDFS vil være O(bd) .
Optimal:
IDDFS-algoritmen er optimal hvis banekostnaden er en ikke-avtagende funksjon av dybden til noden.
6. Toveis søkealgoritme:
Toveis søkealgoritme kjører to samtidige søk, en form for starttilstand kalt fremoversøk og en annen fra målnoden kalt bakoversøk, for å finne målnoden. Toveis søk erstatter én enkelt søkegraf med to små undergrafer, der den ene starter søket fra et første toppunkt og det andre starter fra et målpunkt. Søket stopper når disse to grafene krysser hverandre.
overvåket maskinlæring
Toveis søk kan bruke søketeknikker som BFS, DFS, DLS, etc.
Fordeler:
- Toveissøk er raskt.
- Toveis søk krever mindre minne
Ulemper:
- Implementering av det toveis søketreet er vanskelig.
Eksempel:
I søketreet nedenfor brukes toveis søkealgoritme. Denne algoritmen deler en graf/tre i to undergrafer. Den begynner å krysse fra node 1 i retning forover og starter fra målnode 16 i retning bakover.
Algoritmen avsluttes ved node 9 hvor to søk møtes.

Fullstendighet: Toveissøk er fullført hvis vi bruker BFS i begge søkene.
Tidskompleksitet: Tidskompleksiteten til toveissøk ved hjelp av BFS er O(bd) .
Plass kompleksitet: Plass kompleksitet av toveis søk er O(bd) .
Optimal: Toveissøk er optimalt.