Dyrepasser er en distribuert åpen kildekode-koordineringstjeneste for distribuerte applikasjoner. Den avslører et enkelt sett med primitiver for å implementere tjenester på høyere nivå for synkronisering, konfigurasjonsvedlikehold og gruppe- og navngivning.
I et distribuert system er det flere noder eller maskiner som trenger å kommunisere med hverandre og koordinere handlingene deres. ZooKeeper gir en måte å sikre at disse nodene er oppmerksomme på hverandre og kan koordinere sine handlinger. Den gjør dette ved å opprettholde et hierarkisk tre med datanoder kalt Znodes , som kan brukes til å lagre og hente data og vedlikeholde tilstandsinformasjon. ZooKeeper gir et sett med primitiver, som låser, barrierer og køer, som kan brukes til å koordinere handlingene til noder i et distribuert system. Det gir også funksjoner som ledervalg, failover og gjenoppretting, som kan bidra til å sikre at systemet er motstandsdyktig mot feil. ZooKeeper er mye brukt i distribuerte systemer som Hadoop, Kafka og HBase, og det har blitt en viktig komponent i mange distribuerte applikasjoner.
Hvorfor trenger vi det?
- Koordineringstjenester : Integrasjon/kommunikasjon av tjenester i et distribuert miljø.
- Koordineringstjenester er komplekse å få til. De er spesielt utsatt for feil som løpsforhold og vranglås.
- Race tilstand - To eller flere systemer prøver å utføre en oppgave.
- Vranglås – To eller flere operasjoner venter på hverandre.
- For å gjøre koordineringen mellom distribuerte miljøer enkel, kom utviklere opp med en idé kalt zookeeper, slik at de ikke trenger å frita distribuerte applikasjoner fra ansvaret for å implementere koordineringstjenester fra bunnen av.
Hva er distribuert system?
- Flere datasystemer jobber med ett enkelt problem.
- Det er et nettverk som består av autonome datamaskiner som kobles sammen ved hjelp av distribuert mellomvare.
- Nøkkelegenskaper : Samtidig, ressursdeling, uavhengig, global, større feiltoleranse og pris/ytelse-forhold er mye bedre.
- Nøkkelmål s: åpenhet, pålitelighet, ytelse, skalerbarhet.
- Utfordringer : Sikkerhet, feil, koordinering og ressursdeling.
Koordinasjonsutfordring
- Hvorfor er koordinering i et distribuert system det vanskelige problemet?
- Koordinerings- eller konfigurasjonsadministrasjon for en distribuert applikasjon som har mange systemer.
- Master Node hvor klyngedataene er lagret.
- Arbeidsnoder eller slavenoder henter dataene fra denne masternoden.
- enkelt feilpunkt.
- synkronisering er ikke lett.
- Nøye design og implementering er nødvendig.
Apache dyrepasser
Apache Zookeeper er en distribuert åpen kildekode-koordineringstjeneste for distribuerte systemer. Det gir et sentralt sted for distribuerte applikasjoner for å lagre data, kommunisere med hverandre og koordinere aktiviteter. Zookeeper brukes i distribuerte systemer for å koordinere distribuerte prosesser og tjenester. Den gir en enkel, trestrukturert datamodell, en enkel API og en distribuert protokoll for å sikre datakonsistens og tilgjengelighet. Zookeeper er designet for å være svært pålitelig og feiltolerant, og den kan håndtere høye nivåer av lese- og skrivegjennomstrømming.
Zookeeper er implementert i Java og er mye brukt i distribuerte systemer, spesielt i Hadoop-økosystemet. Det er et Apache Software Foundation-prosjekt og er utgitt under Apache License 2.0.
Arkitektur av Zookeeper
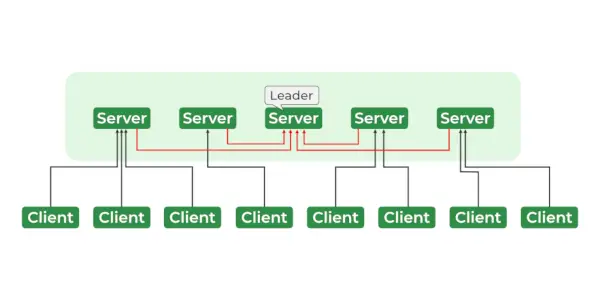
Dyrepassertjenester
ZooKeeper-arkitekturen består av et hierarki av noder kalt znoder, organisert i en trelignende struktur. Hver znode kan lagre data og har et sett med tillatelser som kontrollerer tilgangen til znoden. Znodene er organisert i et hierarkisk navneområde, som ligner på et filsystem. I roten av hierarkiet er rot-znoden, og alle andre znoder er barn av rot-znoden. Hierarkiet ligner på et filsystemhierarki, der hver znode kan ha barn og barnebarn, og så videre.
Viktige komponenter i Zookeeper
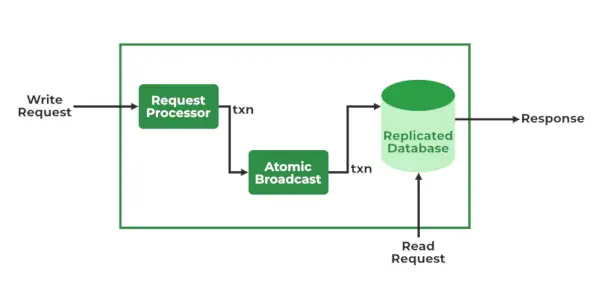
ZooKeeper-tjenester
- Leder og følger
- Be om prosessor – Aktiv i Leader Node og er ansvarlig for behandling av skriveforespørsler. Etter behandling sender den endringer til følgernodene
- Atomic Broadcast – Tilstede i både ledernoden og følgernoden. Den er ansvarlig for å sende endringene til andre noder.
- Databaser i minnet (Repliserte databaser)-Den er ansvarlig for å lagre dataene i dyrepasseren. Hver node inneholder sine egne databaser. Data skrives også til filsystemet som gir mulighet for gjenoppretting i tilfelle problemer med klyngen.
Andre komponenter
- Klient – En av nodene i vår distribuerte applikasjonsklynge. Få tilgang til informasjon fra serveren. Hver klient sender en melding til serveren for å fortelle serveren at klienten er i live.
- Server – Leverer alle tjenester til kunden. Gir anerkjennelse til klienten.
- Ensemble – Gruppe av Zookeeper-servere. Minimum antall noder som kreves for å danne et ensemble er 3.
Zookeeper datamodell
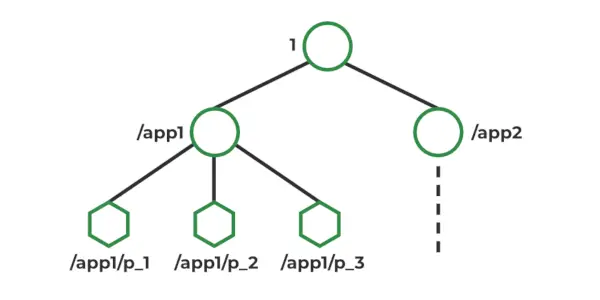
ZooKeeper datamodell
I Zookeeper lagres data i et hierarkisk navneområde, som ligner på et filsystem. Hver node i navneområdet kalles en Znode, og den kan lagre data og ha barn. Znoder ligner på filer og kataloger i et filsystem. Zookeeper tilbyr et enkelt API for å lage, lese, skrive og slette Znodes. Det gir også mekanismer for å oppdage endringer i dataene som er lagret i Znodes, for eksempel klokker og triggere. Znoder opprettholder en statistisk struktur som inkluderer: Versjonsnummer, ACL, tidsstempel, datalengde
Typer Znodes :
- Standhaftighet : Levende til de eksplisitt blir slettet.
- Ephemeral : Aktiv til klienttilkoblingen er aktiv.
- Sekvensiell : Enten vedvarende eller flyktig.
Hvorfor trenger vi ZooKeeper i Hadoop?
Zookeeper brukes til å administrere og koordinere nodene i en Hadoop-klynge, inkludert NameNode, DataNode og ResourceManager. I en Hadoop-klynge hjelper Zookeeper med å:
- Opprettholde konfigurasjonsinformasjon: Zookeeper lagrer konfigurasjonsinformasjonen for Hadoop-klyngen, inkludert plasseringen av NameNode, DataNode og ResourceManager.
- Administrer tilstanden til klyngen: Zookeeper sporer tilstanden til nodene i Hadoop-klyngen og kan brukes til å oppdage når en node har sviktet eller blitt utilgjengelig.
- Koordiner distribuerte prosesser: Zookeeper kan brukes til å koordinere distribuerte prosesser, for eksempel jobbplanlegging og ressursallokering, på tvers av nodene i en Hadoop-klynge.
Zookeeper bidrar til å sikre tilgjengeligheten og påliteligheten til en Hadoop-klynge ved å tilby en sentral koordineringstjeneste for nodene i klyngen.
Hvordan fungerer ZooKeeper i Hadoop?
ZooKeeper fungerer som et distribuert filsystem og viser et enkelt sett med APIer som gjør det mulig for klienter å lese og skrive data til filsystemet. Den lagrer dataene sine i en trelignende struktur kalt en znode, som kan betraktes som en fil eller en katalog i et tradisjonelt filsystem. ZooKeeper bruker en konsensusalgoritme for å sikre at alle serverne har en konsistent oversikt over dataene som er lagret i Znodene. Dette betyr at hvis en klient skriver data til en znode, vil disse dataene bli replikert til alle de andre serverne i ZooKeeper-ensemblet.
En viktig funksjon ved ZooKeeper er dens evne til å støtte forestillingen om en klokke. En klokke lar en klient registrere seg for varsler når dataene som er lagret i en znode endres. Dette kan være nyttig for å overvåke endringer i dataene som er lagret i ZooKeeper og reagere på disse endringene i et distribuert system.
I Hadoop brukes ZooKeeper til en rekke formål, inkludert:
- Lagre konfigurasjonsinformasjon: ZooKeeper brukes til å lagre konfigurasjonsinformasjon som deles av flere Hadoop-komponenter. Den kan for eksempel brukes til å lagre plasseringen av NameNodes i en Hadoop-klynge eller adressene til JobTracker-noder.
- Gir distribuert synkronisering: ZooKeeper brukes til å koordinere aktivitetene til ulike Hadoop-komponenter og sikre at de fungerer sammen på en konsistent måte. For eksempel kan det brukes til å sikre at bare én NameNode er aktiv om gangen i en Hadoop-klynge.
- Vedlikeholde navn: ZooKeeper brukes til å opprettholde en sentralisert navnetjeneste for Hadoop-komponenter. Dette kan være nyttig for å identifisere og lokalisere ressurser i et distribuert system.
ZooKeeper er en viktig komponent i Hadoop og spiller en avgjørende rolle i å koordinere aktiviteten til de ulike underkomponentene.
Lese og skrive i Apache Zookeeper
ZooKeeper gir et enkelt og pålitelig grensesnitt for lesing og skriving av data. Dataene lagres i et hierarkisk navneområde, som ligner på et filsystem, med noder kalt znodes. Hver znode kan lagre data og ha underordnede znoder. ZooKeeper-klienter kan lese og skrive data til disse znodene ved å bruke henholdsvis getData()- og setData()-metodene. Her er et eksempel på lesing og skriving av data ved hjelp av ZooKeeper Java API:
Java
// Connect to the ZooKeeper ensemble> ZooKeeper zk =>new> ZooKeeper(>'localhost:2181'>,>3000>,>null>);> // Write data to the znode '/myZnode'> String path =>'/myZnode'>;> String data =>'hello world'>;> zk.create(path, data.getBytes(), Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);> // Read data from the znode '/myZnode'> byte>[] bytes = zk.getData(path,>false>,>null>);> String readData =>new> String(bytes);> // Prints 'hello world'> System.out.println(readData);> // Closing the connection> // to the ZooKeeper ensemble> zk.close();> |
>
>
Python3
from> kazoo.client>import> KazooClient> # Connect to ZooKeeper> zk>=> KazooClient(hosts>=>'localhost:2181'>)> zk.start()> # Create a node with some data> zk.ensure_path(>'/gfg_node'>)> zk.>set>(>'/gfg_node'>, b>'some_data'>)> # Read the data from the node> data, stat>=> zk.get(>'/gfg_node'>)> print>(data)> # Stop the connection to ZooKeeper> zk.stop()> |
>
starter med java
>
Sesjon og klokker
Økt
- Forespørsler i en økt utføres i FIFO-rekkefølge.
- Så snart økten er etablert øktnummer er tildelt klienten.
- Klienten sender hjerteslag for å holde økten gyldig
- økttidsavbrudd er vanligvis representert i millisekunder
Klokker
- Klokker er mekanismer for klienter for å få varsler om endringene i dyrepasseren
- Klienten kan se mens han leser en bestemt znode.
- Znodendringer er modifikasjoner av data knyttet til znodene eller endringer i znodens barn.
- Klokker utløses bare én gang.
- Hvis økten er utløpt, fjernes også klokker.