Som vi vet, kan Supervised Machine Learning-algoritmen i store trekk klassifiseres i regresjons- og klassifikasjonsalgoritmer. I regresjonsalgoritmer har vi spådd utgangen for kontinuerlige verdier, men for å forutsi de kategoriske verdiene trenger vi Klassifikasjonsalgoritmer.
Hva er klassifiseringsalgoritmen?
Klassifikasjonsalgoritmen er en overvåket læringsteknikk som brukes til å identifisere kategorien av nye observasjoner på grunnlag av treningsdata. I klassifisering lærer et program av det gitte datasettet eller observasjonene og klassifiserer deretter ny observasjon i en rekke klasser eller grupper. Som for eksempel, Ja eller Nei, 0 eller 1, Spam eller Ikke Spam, katt eller hund, osv. Klasser kan kalles som mål/etiketter eller kategorier.
okse vs okse
I motsetning til regresjon, er utgangsvariabelen til Klassifikasjon en kategori, ikke en verdi, slik som 'Grønn eller Blå', 'frukt eller dyr', osv. Siden Klassifikasjonsalgoritmen er en overvåket læringsteknikk, tar den derfor merket inndata, som betyr at den inneholder input med tilsvarende utgang.
I klassifiseringsalgoritmen blir en diskret utgangsfunksjon(y) tilordnet inngangsvariabel(x).
y=f(x), where y = categorical output
Det beste eksemplet på en ML-klassifiseringsalgoritme er Spamdetektor for e-post .
Hovedmålet med Klassifikasjonsalgoritmen er å identifisere kategorien til et gitt datasett, og disse algoritmene brukes hovedsakelig til å forutsi utdata for de kategoriske dataene.
Klassifiseringsalgoritmer kan forstås bedre ved å bruke diagrammet nedenfor. I diagrammet nedenfor er det to klasser, klasse A og klasse B. Disse klassene har egenskaper som ligner på hverandre og ikke ligner på andre klasser.
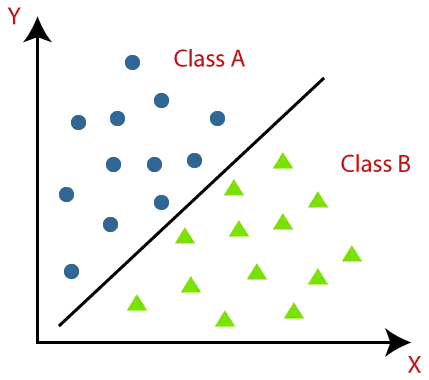
Algoritmen som implementerer klassifiseringen på et datasett er kjent som en klassifikator. Det finnes to typer klassifikasjoner:
Eksempler: JA eller NEI, HANN eller KVINNE, SPAM eller IKKE SPAM, KATT eller HUND, etc.
Eksempel: Klassifikasjoner av typer avlinger, Klassifisering av typer musikk.
Elever i klassifiseringsproblemer:
I klassifiseringsoppgavene er det to typer elever:
Eksempel: K-NN-algoritme, Kasusbasert resonnement
Typer ML-klassifiseringsalgoritmer:
Klassifiseringsalgoritmer kan videre deles inn i hovedsaklig to kategorier:
- Logistisk regresjon
- Støtte vektormaskiner
- K-Nærmeste Naboer
- Kjerne SVM
- Nave Bayes
- Klassifisering av beslutningstre
- Tilfeldig skogklassifisering
Merk: Vi vil lære algoritmene ovenfor i senere kapitler.
Evaluering av en klassifiseringsmodell:
Når modellen vår er fullført, er det nødvendig å evaluere ytelsen; enten er det en klassifiserings- eller regresjonsmodell. Så for å evaluere en klassifiseringsmodell har vi følgende måter:
1. Loggtap eller kryssentropitap:
- Den brukes til å evaluere ytelsen til en klassifikator, hvis utgang er en sannsynlighetsverdi mellom 0 og 1.
- For en god binær klassifiseringsmodell bør verdien av loggtap være nær 0.
- Verdien av loggtap øker hvis den anslåtte verdien avviker fra den faktiske verdien.
- Det lavere loggtapet representerer den høyere nøyaktigheten til modellen.
- For binær klassifisering kan kryssentropi beregnes som:
?(ylog(p)+(1?y)log(1?p))
Hvor y = Faktisk utgang, p = predikert utgang.
2. Forvirringsmatrise:
- Forvirringsmatrisen gir oss en matrise/tabell som utdata og beskriver ytelsen til modellen.
- Det er også kjent som feilmatrisen.
- Matrisen består av prediksjoner resulterer i en oppsummert form, som har et totalt antall korrekte prediksjoner og feil prediksjoner. Matrisen ser ut som i tabellen nedenfor:
| Faktisk positiv | Faktisk negativ | |
|---|---|---|
| Forutsagt positiv | Sant positiv | Falsk positiv |
| Forutsagt negativ | Falsk negativ | Ekte negativ |

3. AUC-ROC-kurve:
for loops java
- ROC-kurve står for Mottaker Driftsegenskaper Kurve og AUC står for Område under kurven .
- Det er en graf som viser ytelsen til klassifiseringsmodellen ved ulike terskler.
- For å visualisere ytelsen til flerklasseklassifiseringsmodellen bruker vi AUC-ROC-kurven.
- ROC-kurven er plottet med TPR og FPR, hvor TPR (True Positive Rate) på Y-aksen og FPR (False Positive Rate) på X-aksen.
Bruk tilfeller av klassifikasjonsalgoritmer
Klassifiseringsalgoritmer kan brukes på forskjellige steder. Nedenfor er noen populære brukstilfeller av klassifiseringsalgoritmer:
- Deteksjon av søppelpost på e-post
- Talegjenkjenning
- Identifikasjon av kreftsvulstceller.
- Klassifisering av narkotika
- Biometrisk identifikasjon, etc.