I den virkelige verden har ikke alle data vi jobber med en målvariabel. Denne typen data kan ikke analyseres ved hjelp av overvåkede læringsalgoritmer. Vi trenger hjelp fra uovervåkede algoritmer. En av de mest populære typene analyser under uovervåket læring er kundesegmentering for målrettede annonser, eller i medisinsk bildebehandling for å finne ukjente eller nye infiserte områder og mange flere brukstilfeller som vi vil diskutere videre i denne artikkelen.
Innholdsfortegnelse
- Hva er Clustering?
- Typer av gruppering
- Bruk av Clustering
- Typer klyngealgoritmer
- Anvendelser av Clustering på forskjellige felt:
- Ofte stilte spørsmål (FAQs) om gruppering
Hva er Clustering?
Oppgaven med å gruppere datapunkter basert på deres likhet med hverandre kalles Clustering eller Cluster Analysis. Denne metoden er definert under grenen av Uovervåket læring , som tar sikte på å få innsikt fra umerkede datapunkter, det vil si i motsetning til veiledet læring vi har ikke en målvariabel.
Clustering tar sikte på å danne grupper av homogene datapunkter fra et heterogent datasett. Den evaluerer likheten basert på en metrikk som euklidisk avstand, cosinuslikhet, Manhattan-avstand osv. og grupperer deretter punktene med høyest likhetspoeng.
For eksempel, i grafen gitt nedenfor, kan vi tydelig se at det er 3 sirkulære klynger som dannes på grunnlag av avstand.
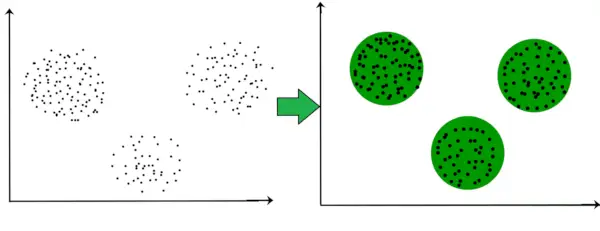
Nå er det ikke nødvendig at klynger som dannes må være sirkulære i form. Formen på klynger kan være vilkårlig. Det er mange algoritmer som fungerer godt med å oppdage vilkårlig formede klynger.
For eksempel, i den gitte grafen nedenfor kan vi se at klyngene som dannes ikke er sirkulære i form.
prologspråk

Typer av gruppering
Grovt sett er det 2 typer klynging som kan utføres for å gruppere lignende datapunkter:
- Hard Clustering: I denne typen clustering tilhører hvert datapunkt en klynge fullstendig eller ikke. For eksempel, la oss si at det er 4 datapunkter og vi må gruppere dem i 2 klynger. Så hvert datapunkt vil enten tilhøre klynge 1 eller klynge 2.
| Datapunkter | Klynger |
|---|---|
| EN | C1 |
| B | C2 |
| C | C2 |
| D | C1 |
- Myk gruppering: I denne typen klynge, i stedet for å tilordne hvert datapunkt til en separat klynge, blir en sannsynlighet eller sannsynlighet for at det punktet er det klyngen evaluert. For eksempel, la oss si at det er 4 datapunkter og vi må gruppere dem i 2 klynger. Så vi vil evaluere sannsynligheten for at et datapunkt tilhører begge klyngene. Denne sannsynligheten beregnes for alle datapunkter.
| Datapunkter | Sannsynlighet for C1 | Sannsynlighet for C2 |
| EN | 0,91 | 0,09 |
| B | 0,3 | 0,7 |
| C | 0,17 | 0,83 |
| D | 1 | 0 |
Bruk av Clustering
Nå før vi begynner med typer klyngealgoritmer, vil vi gå gjennom brukstilfellene til klyngealgoritmer. Klyngealgoritmer brukes hovedsakelig til:
- Markedssegmentering – Bedrifter bruker clustering for å gruppere kundene sine og bruker målrettede annonser for å tiltrekke seg flere publikum.
- Analyse av sosiale nettverk – Sosiale medier bruker dataene dine for å forstå nettleseratferden din og gi deg målrettede venneanbefalinger eller innholdsanbefalinger.
- Medisinsk bildebehandling - Leger bruker Clustering for å finne ut syke områder i diagnostiske bilder som røntgenstråler.
- Anomalideteksjon – For å finne uteliggere i en strøm av sanntidsdatasett eller prognoser for uredelige transaksjoner kan vi bruke klynging for å identifisere dem.
- Forenkle arbeid med store datasett – Hver klynge får en klynge-ID etter at klynge er fullført. Nå kan du redusere et funksjonssetts hele funksjonssett til dets klynge-ID. Clustering er effektivt når det kan representere en komplisert sak med en enkel klynge-ID. Ved å bruke samme prinsipp kan klyngedata gjøre komplekse datasett enklere.
Det er mange flere brukstilfeller for klynging, men det er noen av de viktigste og vanlige brukstilfellene for klynging. Fremover vil vi diskutere klyngealgoritmer som vil hjelpe deg med å utføre oppgavene ovenfor.
Typer klyngealgoritmer
På overflatenivå hjelper klynging i analysen av ustrukturerte data. Grafer, den korteste avstanden og tettheten til datapunktene er noen av elementene som påvirker klyngedannelsen. Clustering er prosessen med å bestemme hvor beslektede objektene er basert på en beregning kalt likhetsmålet. Likhetsberegninger er lettere å finne i mindre sett med funksjoner. Det blir vanskeligere å lage likhetsmål etter hvert som antallet funksjoner øker. Avhengig av typen klyngealgoritme som brukes i datautvinning, brukes flere teknikker for å gruppere dataene fra datasettene. I denne delen beskrives klyngeteknikkene. Ulike typer klyngealgoritmer er:
- Centroid-basert klynging (partisjoneringsmetoder)
- Tetthetsbasert gruppering (modellbaserte metoder)
- Tilkoblingsbasert clustering (hierarkisk clustering)
- Distribusjonsbasert klynging
Vi vil gå gjennom hver av disse typene i korte trekk.
1. Partisjoneringsmetoder er de enkleste klyngealgoritmene. De grupperer datapunkter på grunnlag av deres nærhet. Vanligvis er likhetsmålet valgt for disse algoritmene euklidisk avstand, Manhattan-avstand eller Minkowski-avstand. Datasettene er separert i et forhåndsbestemt antall klynger, og hver klynge refereres til av en vektor av verdier. Sammenlignet med vektorverdien viser inngangsdatavariabelen ingen forskjell og slutter seg til klyngen.
Den primære ulempen for disse algoritmene er kravet om at vi etablerer antall klynger, k, enten intuitivt eller vitenskapelig (ved bruk av albuemetoden) før et maskinlæringssystem for klynging begynner å tildele datapunktene. Til tross for dette er det fortsatt den mest populære typen clustering. K-betyr og K-medoider clustering er noen eksempler på denne typen clustering.
2. Tetthetsbasert gruppering (modellbaserte metoder)
Tetthetsbasert clustering, en modellbasert metode, finner grupper basert på tettheten av datapunkter. I motsetning til tyngdepunktsbasert clustering, som krever at antall klynger er forhåndsdefinert og er sensitiv for initialisering, bestemmer tetthetsbasert clustering antallet klynger automatisk og er mindre utsatt for startposisjoner. De er gode til å håndtere klynger i forskjellige størrelser og former, noe som gjør dem ideelle for datasett med uregelmessig formede eller overlappende klynger. Disse metodene håndterer både tette og sparsomme dataregioner ved å fokusere på lokal tetthet og kan skille klynger med en rekke morfologier.
I motsetning til dette har tyngdepunktsbasert gruppering, som k-betyr, problemer med å finne vilkårlig formede klynger. På grunn av det forhåndsinnstilte antallet klyngekrav og ekstreme følsomhet for den første plasseringen av tyngdepunktene, kan resultatene variere. Videre begrenser tendensen til tyngdepunktbaserte tilnærminger til å produsere sfæriske eller konvekse klynger deres kapasitet til å håndtere kompliserte eller uregelmessig formede klynger. Avslutningsvis overvinner tetthetsbasert clustering ulempene med tyngdepunktsbaserte teknikker ved autonomt å velge klyngestørrelser, være motstandsdyktig mot initialisering og vellykket fange opp klynger av forskjellige størrelser og former. Den mest populære tetthetsbaserte klyngealgoritmen er DBSCAN .
3. Tilkoblingsbasert clustering (hierarkisk clustering)
En metode for å sette sammen relaterte datapunkter til hierarkiske klynger kalles hierarkisk clustering. Hvert datapunkt tas i utgangspunktet i betraktning som en egen klynge, som deretter kombineres med de klyngene som ligner mest for å danne en stor klynge som inneholder alle datapunktene.
Tenk på hvordan du kan ordne en samling av gjenstander basert på hvor like de er. Hvert objekt begynner som sin egen klynge ved bunnen av treet ved bruk av hierarkisk klynging, som skaper et dendrogram, en trelignende struktur. De nærmeste paringene av klynger kombineres deretter til større klynger etter at algoritmen undersøker hvor like objektene er hverandre. Når hvert objekt er i en klynge på toppen av treet, er sammenslåingsprosessen fullført. Å utforske ulike granularitetsnivåer er en av de morsomme tingene med hierarkisk klynging. For å få et gitt antall klynger kan du velge å kutte dendrogram i en bestemt høyde. Jo mer like to objekter er innenfor en klynge, jo nærmere er de. Det kan sammenlignes med å klassifisere gjenstander i henhold til deres familietrær, der de nærmeste slektningene er gruppert sammen og de bredere grenene indikerer mer generelle forbindelser. Det er 2 tilnærminger for hierarkisk klynging:
- Splittende gruppering : Det følger en top-down tilnærming, her anser vi alle datapunkter som en del av en stor klynge, og deretter deles denne klyngen inn i mindre grupper.
- Agglomerativ gruppering : Det følger en bottom-up-tilnærming, her anser vi alle datapunkter som en del av individuelle klynger, og deretter blir disse klyngene klubbet sammen for å lage en stor klynge med alle datapunkter.
4. Distribusjonsbasert klynging
Ved å bruke distribusjonsbasert klynging genereres og organiseres datapunkter i henhold til deres tilbøyelighet til å falle inn i den samme sannsynlighetsfordelingen (som en gaussisk, binomial eller annet) i dataene. Dataelementene er gruppert ved hjelp av en sannsynlighetsbasert fordeling som er basert på statistiske fordelinger. Inkludert er dataobjekter som har større sannsynlighet for å være i klyngen. Det er mindre sannsynlig at et datapunkt blir inkludert i en klynge jo lenger det er fra klyngens sentrale punkt, som finnes i hver klynge.
En bemerkelsesverdig ulempe med tetthet og grensebaserte tilnærminger er behovet for å spesifisere klyngene a priori for noen algoritmer, og først og fremst definisjonen av klyngeformen for hoveddelen av algoritmer. Det må være valgt minst én tuning eller hyper-parameter, og selv om det skal være enkelt, kan det få uventede konsekvenser å få feil. Distribusjonsbasert clustering har en klar fordel fremfor nærhet og tyngdepunktbasert clustering-tilnærminger når det gjelder fleksibilitet, nøyaktighet og klyngestruktur. Nøkkelen er at, for å unngå overmontering , fungerer mange klyngemetoder bare med simulerte eller produserte data, eller når hoveddelen av datapunktene absolutt tilhører en forhåndsinnstilt distribusjon. Den mest populære distribusjonsbaserte klyngealgoritmen er Gaussisk blandingsmodell .
Anvendelser av Clustering på forskjellige felt:
- Markedsføring: Den kan brukes til å karakterisere og oppdage kundesegmenter for markedsføringsformål.
- Biologi: Den kan brukes til klassifisering mellom forskjellige arter av planter og dyr.
- Biblioteker: Den brukes til å gruppere forskjellige bøker på grunnlag av emner og informasjon.
- Forsikring: Den brukes til å anerkjenne kundene, deres retningslinjer og identifisere svindelene.
- Byplanlegging: Det brukes til å lage grupper av hus og til å studere verdiene deres basert på deres geografiske plassering og andre faktorer som er tilstede.
- Jordskjelvstudier: Ved å lære de jordskjelvrammede områdene kan vi bestemme farlige soner.
- Bildebehandling : Clustering kan brukes til å gruppere lignende bilder sammen, klassifisere bilder basert på innhold og identifisere mønstre i bildedata.
- Genetikk: Clustering brukes til å gruppere gener som har lignende uttrykksmønstre og identifisere gennettverk som fungerer sammen i biologiske prosesser.
- Finansiere: Clustering brukes til å identifisere markedssegmenter basert på kundeadferd, identifisere mønstre i aksjemarkedsdata og analysere risiko i investeringsporteføljer.
- Kundeservice: Clustering brukes til å gruppere kundehenvendelser og -klager i kategorier, identifisere vanlige problemer og utvikle målrettede løsninger.
- Produksjon : Clustering brukes til å gruppere lignende produkter sammen, optimalisere produksjonsprosesser og identifisere defekter i produksjonsprosesser.
- Medisinsk diagnose: Clustering brukes til å gruppere pasienter med lignende symptomer eller sykdommer, noe som hjelper til med å stille nøyaktige diagnoser og identifisere effektive behandlinger.
- Svindeloppdagelse: Clustering brukes til å identifisere mistenkelige mønstre eller anomalier i økonomiske transaksjoner, noe som kan hjelpe til med å oppdage svindel eller annen økonomisk kriminalitet.
- Trafikkanalyse: Clustering brukes til å gruppere lignende mønstre av trafikkdata, for eksempel topptider, ruter og hastigheter, som kan hjelpe til med å forbedre transportplanlegging og infrastruktur.
- Analyse av sosiale nettverk: Clustering brukes til å identifisere samfunn eller grupper i sosiale nettverk, noe som kan hjelpe til med å forstå sosial atferd, påvirkning og trender.
- Cybersikkerhet: Clustering brukes til å gruppere lignende mønstre av nettverkstrafikk eller systematferd, noe som kan hjelpe til med å oppdage og forhindre nettangrep.
- Klimaanalyse: Clustering brukes til å gruppere lignende mønstre av klimadata, som temperatur, nedbør og vind, som kan hjelpe til med å forstå klimaendringer og deres innvirkning på miljøet.
- Sportsanalyse: Clustering brukes til å gruppere lignende mønstre av spiller- eller teamytelsesdata, noe som kan hjelpe til med å analysere spillerens eller lagets styrker og svakheter og ta strategiske beslutninger.
- Kriminalitetsanalyse: Clustering brukes til å gruppere lignende mønstre av kriminalitetsdata, for eksempel sted, tid og type, som kan hjelpe til med å identifisere kriminalitetshotspots, forutsi fremtidige kriminalitetstrender og forbedre kriminalitetsforebyggende strategier.
Konklusjon
I denne artikkelen diskuterte vi Clustering, dets typer, og det er applikasjoner i den virkelige verden. Det er mye mer som skal dekkes i uovervåket læring, og klyngeanalyse er bare det første trinnet. Denne artikkelen kan hjelpe deg med å komme i gang med Clustering-algoritmer og hjelpe deg med å få et nytt prosjekt som kan legges til porteføljen din.
Ofte stilte spørsmål (FAQs) om gruppering
Sp. Hva er den beste klyngemetoden?
De 10 beste klyngealgoritmene er:
- K-betyr Clustering
- Hierarkisk gruppering
- DBSCAN (densitetsbasert romlig klynging av applikasjoner med støy)
- Gaussiske blandingsmodeller (GMM)
- Agglomerativ gruppering
- Spektral gruppering
- Gjennomsnittlig Shift Clustering
- Affinitetsforplantning
- OPTIKK (bestillingspunkter for å identifisere klyngestrukturen)
- Birch (balansert iterativ reduksjon og gruppering ved bruk av hierarkier)
Sp. Hva er forskjellen mellom gruppering og klassifisering?
Hovedforskjellen mellom clustering og klassifisering er at klassifisering er en overvåket læringsalgoritme og clustering er en uovervåket læringsalgoritme. Det vil si at vi bruker clustering på de datasettene som ikke har en målvariabel.
Sp. Hva er fordelene med klyngeanalyse?
Data kan organiseres i meningsfulle grupper ved å bruke det sterke analytiske verktøyet klyngeanalyse. Du kan bruke den til å finne segmenter, finne skjulte mønstre og forbedre beslutninger.
Q. Hvilken er den raskeste klyngemetoden?
K-betyr klynging regnes ofte som den raskeste klyngemetoden på grunn av dens enkelhet og beregningseffektivitet. Den tildeler iterativt datapunkter til nærmeste klyngesenter, noe som gjør den egnet for store datasett med lav dimensjonalitet og et moderat antall klynger.
Sp. Hva er begrensningene ved klynging?
Begrensninger ved clustering inkluderer følsomhet for startforhold, avhengighet av valg av parametere, vanskeligheter med å bestemme det optimale antallet klynger og utfordringer med å håndtere høydimensjonale eller støyende data.
Spørsmål. Hva er kvaliteten på resultatet av klynging avhengig av?
Kvaliteten på klyngeresultater avhenger av faktorer som valg av algoritme, avstandsmetrikk, antall klynger, initialiseringsmetode, dataforbehandlingsteknikker, klyngevalueringsberegninger og domenekunnskap. Disse elementene påvirker samlet effektiviteten og nøyaktigheten til klyngeresultatet.