Et databaseskjema er en struktur som representerer den logiske lagringen av dataene i en database . Den representerer organiseringen av data og gir informasjon om relasjonene mellom tabellene i en gitt database. I dette emnet vil vi forstå mer om databaseskjema og dets typer. Før du forstår databaseskjemaet, la oss først forstå hva en database er.
Hva er database?
EN database er et sted å lagre informasjon. Den kan lagre de enkleste dataene, for eksempel en liste over personer, så vel som de mest komplekse dataene. Databasen lagrer informasjonen i et godt strukturert format.
Hva er databaseskjema?
- Et databaseskjema er den logiske representasjonen av en database, som viser hvordan dataene lagres logisk i hele databasen. Den inneholder en liste over attributter og instruksjoner som informerer databasemotoren om hvordan dataene er organisert og hvordan elementene er relatert til hverandre.
- Et databaseskjema inneholder skjemaobjekter som kan inkludere tabeller, felt, pakker, visninger, relasjoner, primærnøkkel, fremmednøkkel,
- I virkeligheten er dataene fysisk lagret i filer som kan være i ustrukturert form, men for å hente dem og bruke dem må vi legge dem i en strukturert form. For å gjøre dette brukes et databaseskjema. Den gir kunnskap om hvordan dataene er organisert i en database og hvordan de er knyttet til andre data.
- Et databaseskjemaobjekt inkluderer følgende:
- Konsekvent formatering for alle dataoppføringer.
- Databaseobjekter og unike nøkler for alle dataoppføringer.
- Tabeller med flere kolonner, og hver kolonne inneholder navnet og datatypen.
- Kompleksiteten og størrelsen på skjemaet varierer i henhold til størrelsen på prosjektet. Det hjelper utviklere å enkelt administrere og strukturere databasen før den koder den.
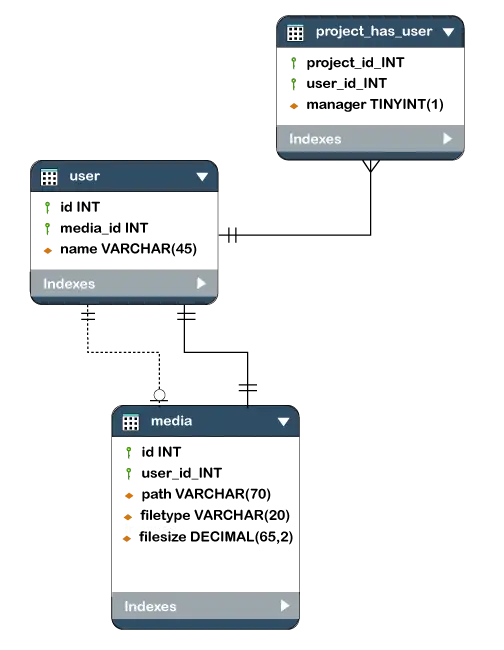
- Det gitte diagrammet er et eksempel på et databaseskjema. Den inneholder tre tabeller, deres datatyper. Dette representerer også relasjonene mellom tabellene og primærnøkler samt fremmednøkler.
Typer databaseskjema
Databaseskjemaet er delt inn i tre typer, som er:

1. Fysisk databaseskjema
Et fysisk databaseskjema spesifiserer hvordan dataene lagres fysisk på et lagringssystem eller disklagring i form av filer og indekser. Å designe en database på fysisk nivå kalles en fysisk skjema .
2. Logisk databaseskjema
Det logiske databaseskjemaet spesifiserer alle logiske begrensningene som må brukes på de lagrede dataene. Den definerer visningene, integritetsbegrensningene og tabellen. Her begrepet integritetsbegrensninger definere sett med regler som brukes av DBMS (Database Management System) for å opprettholde kvaliteten for innsetting og oppdatering av dataene. Det logiske skjemaet representerer hvordan dataene lagres i form av tabeller og hvordan attributtene til en tabell er koblet sammen.
På dette nivået jobber programmerere og administratorer, og implementeringen av datastrukturen er skjult på dette nivået.
Ulike verktøy brukes til å lage et logisk databaseskjema, og disse verktøyene demonstrerer forholdet mellom komponenten i dataene dine; denne prosessen kalles IS-modellering .
ER-modelleringen står for entity-relationship modellering, som spesifiserer relasjonene mellom ulike enheter.
Vi kan forstå det med et eksempel på en grunnleggende handelsapplikasjon. Nedenfor er skjemadiagrammet, den enkle ER-modellen som representerer den logiske flyten av transaksjoner i en handelsapplikasjon.

I det gitte eksemplet er Id-ene gitt i hver sirkel, og disse Id-ene er primærnøkkel og fremmednøkler.
De primærnøkkelen er brukes til å identifisere oppføringen i et dokument eller post unikt. Id-ene til de tre øverste sirklene er hovednøklene.
De Fremmednøkkel brukes som primærnøkkel for andre tabeller. FK representerer fremmednøkkelen i diagrammet. Det relaterer en tabell til en annen tabell.
3. Vis skjema
Visningsnivådesignet til en database er kjent som se skjema . Dette skjemaet beskriver generelt sluttbrukerinteraksjonen med databasesystemene.
Forskjellen mellom det fysiske og det logiske databaseskjemaet
| Fysisk databaseskjema | Logisk databaseskjema |
|---|---|
| Den inkluderer ikke attributtene. | Det inkluderer attributtene. |
| Den inneholder både primære og sekundære nøkler. | Den inneholder også både primær- og sekundærnøkler. |
| Den inneholder tabellnavnet. | Den inneholder navnene på tabellene. |
| Den inneholder kolonnenavnene og deres datatyper. | Den inneholder ikke noe kolonnenavn eller datatype. |
Databaseforekomst eller databaseskjema er det samme?
Begrepene databaseskjema og databaseforekomster er relatert til hverandre og noen ganger forvirrende å brukes som det samme. Men begge er forskjellige fra hverandre.
Databaseskjema er en representasjon av en planlagt database og inneholder faktisk ikke dataene.
På den annen side, a databaseforekomst er en type øyeblikksbilde av en faktisk database slik den eksisterte på et tidspunkt. Derfor varierer den eller kan endres etter tidspunktet. Derimot er databaseskjemaet statisk og veldig komplekst for å endre strukturen til en database.
streng erstatte all java
Både forekomster og skjemaer er relatert til og påvirker hverandre gjennom DBMS. DBMS sikrer at hver databaseforekomst overholder begrensningene som er pålagt av databasedesignerne i databaseskjemaet.
Opprette skjema
For å lage et skjema, brukes 'CREATE SCHEMA'-setninger i hver type database. Men hver DBMS har en annen betydning for dette. Nedenfor forklarer vi å lage skjema i forskjellige databasesystemer:
1. MySQL
I MySQL , den ' LAG SKEMA ' uttalelse oppretter databasen. Det er fordi CREATE SCHEMA-setningen i MySQL ligner på CREATE DATABASE-setningen, og skjemaet er et synonym for databasen.
2. Oracle-database
I Oracle Database er hvert skjema allerede til stede hos hver databasebruker. Derfor lager CREATE SCHEMA faktisk ikke et skjema; snarere hjelper det å vise skjemaet med tabeller og visninger og gir tilgang til disse objektene uten å kreve flere SQL-setninger for flere transaksjoner. 'CREATE USER'-setningen brukes til å lage et skjema i Oracle.
3. SQL Server
I SQL server, oppretter 'CREATE SCHEMA'-setningen et nytt skjema med navnet oppgitt av brukeren.
Databaseskjemadesign
Et skjemadesign er det første trinnet i å bygge et grunnlag innen databehandling. Ineffektive skjemadesign er vanskelige å administrere og bruker mer minne og andre ressurser. Det avhenger logisk sett av forretningskravene. Det kreves å velge riktig databaseskjemadesign for å forenkle prosjektets livssyklus. Listen over noen populære databaseskjemadesign er gitt nedenfor:
Flat modell
Et flatt modellskjema er en type 2D-array der hver kolonne inneholder samme type data, og elementer i en rad er relatert til hverandre. Det kan forstås som et enkelt regneark eller en databasetabell uten relasjoner. Denne skjemadesignen er best egnet for små applikasjoner som ikke inneholder komplekse data.
Hierarkisk modell
Den hierarkiske modelldesignen inneholder en trelignende struktur. Trestrukturen inneholder rotnoden til data og dens underordnede noder. Mellom hver underordnede node og overordnede node er det en en-til-mange-relasjon. Slike typer databaseskjemaer presenteres av XML- eller JSON-filer, da disse filene kan inneholde enhetene med deres underenheter.
streng i java
De hierarkiske skjemamodellene er best egnet for lagring av nestede data, for eksempel representasjon Hominoid klassifisering.
Nettverksmodell
Nettverksmodelldesignet ligner på hierarkisk design ettersom det representerer en rekke noder og toppunkter. Hovedforskjellen mellom nettverksmodellen og den hierarkiske modellen er at nettverksmodellen tillater et mange-til-mange forhold. Derimot tillater den hierarkiske modellen bare et en-til-mange forhold.
Nettverksmodelldesignet er best egnet for applikasjoner som krever romlige beregninger. Det er også flott for å representere arbeidsflyter og hovedsakelig for saker med flere veier til samme resultat.
Relasjonsmodell
Relasjonsmodellene brukes for relasjonsdatabasen, som lagrer data som relasjoner til tabellen. Det er relasjonsoperatorer som brukes til å operere på data for å manipulere og beregne forskjellige verdier fra dem.
Stjerneskjema
Stjerneskjemaet er en annen måte for skjemadesign for å organisere dataene. Den egner seg best til å lagre og analysere en enorm mengde data, og den fungerer på 'Fakta' og 'Dimensjoner'. Her faktum er det numeriske datapunktet som kjører forretningsprosesser, og Dimensjon er en beskrivelse av fakta. Med Star Schema kan vi strukturere dataene til RDBMS .
Snøfnuggskjema
Snøfnuggskjemaet er en tilpasning av et stjerneskjema. Det er en hoved-'Fakta'-tabell i stjerneskjemaet som inneholder hoveddatapunktene og referanse til dimensjonstabellene. Men i snøfnugg kan dimensjonstabeller ha sine egne dimensjonstabeller.