Introduksjon:
URL-forkortere er et eksempel på hashing da det kartlegger URL-adresser i stor størrelse til liten størrelse
Noen eksempler på hash-funksjoner:
- nøkkel % antall bøtter
- ASCII-verdi av tegnet * PrimeNumberx. Hvor x = 1, 2, 3….n
- Du kan lage din egen hash-funksjon, men det bør være en god hash-funksjon som gir mindre antall kollisjoner.
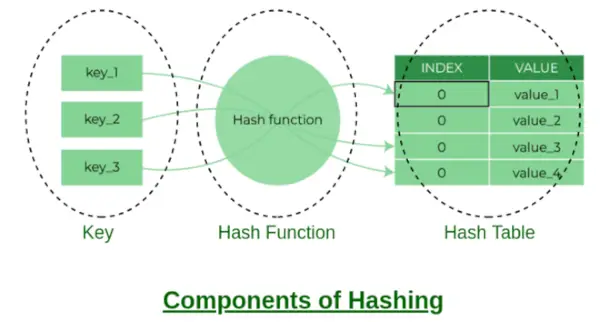
Komponenter av hashing
Bøtteindeks:
Verdien som returneres av Hash-funksjonen er bøtteindeksen for en nøkkel i en separat kjedemetode. Hver indeks i matrisen kalles en bøtte da den er en bøtte med en koblet liste.
Rehashing:
Rehashing er et konsept som reduserer kollisjon når elementene økes i gjeldende hashtabell. Den vil lage en ny matrise med doblet størrelse og kopiere de forrige matriseelementene til den, og den er som den interne driften av vektor i C++. Åpenbart bør Hash-funksjonen være dynamisk da den skal reflektere noen endringer når kapasiteten økes. Hash-funksjonen inkluderer kapasiteten til hash-tabellen i den, mens kopiering av nøkkelverdier fra den forrige array-hash-funksjonen gir derfor forskjellige bøtteindekser da den er avhengig av kapasiteten (bøttene) til hashtabellen. Vanligvis, når verdien av belastningsfaktoren er større enn 0,5 utføres rehashings.
- Dobbel størrelsen på matrisen.
- Kopier elementene i den forrige matrisen til den nye matrisen. Vi bruker hash-funksjonen mens vi kopierer hver node til en ny matrise igjen, derfor vil det redusere kollisjon.
- Slett den forrige matrisen fra minnet og pek hash-kartets innvendige matrisepeker til denne nye matrisen.
- Generelt er Load Factor = antall elementer i Hash Map / totalt antall buckets (kapasitet).
Kollisjon:
Kollisjon er situasjonen når bøtteindeksen ikke er tom. Det betyr at et koblet listehode er til stede ved den bøtteindeksen. Vi har to eller flere verdier som tilordnes den samme bøtteindeksen.
Hovedfunksjoner i programmet vårt
- Innsetting
- Søk
- Hash funksjon
- Slett
- Rehashing
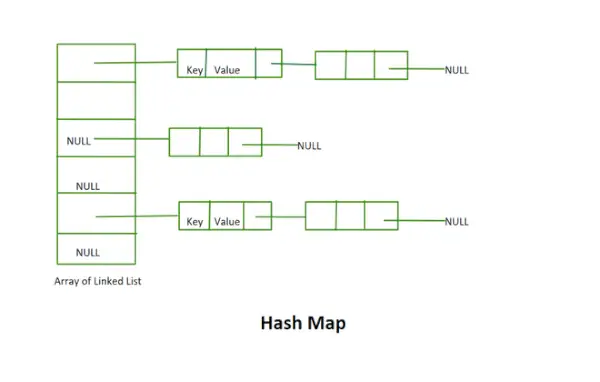
Hash kart
Implementering uten rehashing:
C
hvordan sortere en matrise i java
hvordan finne skjermstørrelsen
#include> #include> #include> // Linked List node> struct> node {> >// key is string> >char>* key;> >// value is also string> >char>* value;> >struct> node* next;> };> // like constructor> void> setNode(>struct> node* node,>char>* key,>char>* value)> {> >node->nøkkel = nøkkel;> >node->verdi = verdi;> >node->neste = NULL;> >return>;> };> struct> hashMap {> >// Current number of elements in hashMap> >// and capacity of hashMap> >int> numOfElements, capacity;> >// hold base address array of linked list> >struct> node** arr;> };> // like constructor> void> initializeHashMap(>struct> hashMap* mp)> {> >// Default capacity in this case> >mp->kapasitet = 100;> >mp->numOfElements = 0;> >// array of size = 1> >mp->arr = (>struct> node**)>malloc>(>sizeof>(>struct> node*)> >* mp->kapasitet);> >return>;> }> int> hashFunction(>struct> hashMap* mp,>char>* key)> {> >int> bucketIndex;> >int> sum = 0, factor = 31;> >for> (>int> i = 0; i <>strlen>(key); i++) {> >// sum = sum + (ascii value of> >// char * (primeNumber ^ x))...> >// where x = 1, 2, 3....n> >sum = ((sum % mp->kapasitet)> >+ (((>int>)key[i]) * factor) % mp->kapasitet)> >% mp->kapasitet;> >// factor = factor * prime> >// number....(prime> >// number) ^ x> >factor = ((factor % __INT16_MAX__)> >* (31 % __INT16_MAX__))> >% __INT16_MAX__;> >}> >bucketIndex = sum;> >return> bucketIndex;> }> void> insert(>struct> hashMap* mp,>char>* key,>char>* value)> {> >// Getting bucket index for the given> >// key - value pair> >int> bucketIndex = hashFunction(mp, key);> >struct> node* newNode = (>struct> node*)>malloc>(> >// Creating a new node> >sizeof>(>struct> node));> >// Setting value of node> >setNode(newNode, key, value);> >// Bucket index is empty....no collision> >if> (mp->arr[bucketIndex] == NULL) {> >mp->arr[bucketIndex] = nyNode;> >}> >// Collision> >else> {> >// Adding newNode at the head of> >// linked list which is present> >// at bucket index....insertion at> >// head in linked list> >newNode->neste = mp->arr[bucketIndex];> >mp->arr[bucketIndex] = nyNode;> >}> >return>;> }> void> delete> (>struct> hashMap* mp,>char>* key)> {> >// Getting bucket index for the> >// given key> >int> bucketIndex = hashFunction(mp, key);> >struct> node* prevNode = NULL;> >// Points to the head of> >// linked list present at> >// bucket index> >struct> node* currNode = mp->arr[bucketIndex];> >while> (currNode != NULL) {> >// Key is matched at delete this> >// node from linked list> >if> (>strcmp>(key, currNode->nøkkel) == 0) {> >// Head node> >// deletion> >if> (currNode == mp->arr[bucketIndex]) {> >mp->arr[bucketIndex] = currNode->neste;> >}> >// Last node or middle node> >else> {> >prevNode->neste = currNode->neste;> >}> >free>(currNode);> >break>;> >}> >prevNode = currNode;> >currNode = currNode->neste;> >}> >return>;> }> char>* search(>struct> hashMap* mp,>char>* key)> {> >// Getting the bucket index> >// for the given key> >int> bucketIndex = hashFunction(mp, key);> >// Head of the linked list> >// present at bucket index> >struct> node* bucketHead = mp->arr[bucketIndex];> >while> (bucketHead != NULL) {> >// Key is found in the hashMap> >if> (bucketHead->tast == tast) {> >return> bucketHead->verdi;> >}> >bucketHead = bucketHead->neste;> >}> >// If no key found in the hashMap> >// equal to the given key> >char>* errorMssg = (>char>*)>malloc>(>sizeof>(>char>) * 25);> >errorMssg =>'Oops! No data found.
'>;> >return> errorMssg;> }> // Drivers code> int> main()> {> >// Initialize the value of mp> >struct> hashMap* mp> >= (>struct> hashMap*)>malloc>(>sizeof>(>struct> hashMap));> >initializeHashMap(mp);> >insert(mp,>'Yogaholic'>,>'Anjali'>);> >insert(mp,>'pluto14'>,>'Vartika'>);> >insert(mp,>'elite_Programmer'>,>'Manish'>);> >insert(mp,>'GFG'>,>'techcodeview.com'>);> >insert(mp,>'decentBoy'>,>'Mayank'>);> >printf>(>'%s
'>, search(mp,>'elite_Programmer'>));> >printf>(>'%s
'>, search(mp,>'Yogaholic'>));> >printf>(>'%s
'>, search(mp,>'pluto14'>));> >printf>(>'%s
'>, search(mp,>'decentBoy'>));> >printf>(>'%s
'>, search(mp,>'GFG'>));> >// Key is not inserted> >printf>(>'%s
'>, search(mp,>'randomKey'>));> >printf>(>'
After deletion :
'>);> >// Deletion of key> >delete> (mp,>'decentBoy'>);> >printf>(>'%s
'>, search(mp,>'decentBoy'>));> >return> 0;> }> |
>
>
C++
forskjell på kjærlighet og like
#include> #include> // Linked List node> struct> node {> >// key is string> >char>* key;> >// value is also string> >char>* value;> >struct> node* next;> };> // like constructor> void> setNode(>struct> node* node,>char>* key,>char>* value) {> >node->nøkkel = nøkkel;> >node->verdi = verdi;> >node->neste = NULL;> >return>;> }> struct> hashMap {> >// Current number of elements in hashMap> >// and capacity of hashMap> >int> numOfElements, capacity;> >// hold base address array of linked list> >struct> node** arr;> };> // like constructor> void> initializeHashMap(>struct> hashMap* mp) {> >// Default capacity in this case> >mp->kapasitet = 100;> >mp->numOfElements = 0;> >// array of size = 1> >mp->arr = (>struct> node**)>malloc>(>sizeof>(>struct> node*) * mp->kapasitet);> >return>;> }> int> hashFunction(>struct> hashMap* mp,>char>* key) {> >int> bucketIndex;> >int> sum = 0, factor = 31;> >for> (>int> i = 0; i <>strlen>(key); i++) {> >// sum = sum + (ascii value of> >// char * (primeNumber ^ x))...> >// where x = 1, 2, 3....n> >sum = ((sum % mp->kapasitet) + (((>int>)key[i]) * factor) % mp->kapasitet) % mp->kapasitet;> >// factor = factor * prime> >// number....(prime> >// number) ^ x> >factor = ((factor % __INT16_MAX__) * (31 % __INT16_MAX__)) % __INT16_MAX__;> >}> >bucketIndex = sum;> >return> bucketIndex;> }> void> insert(>struct> hashMap* mp,>char>* key,>char>* value) {> >// Getting bucket index for the given> >// key - value pair> >int> bucketIndex = hashFunction(mp, key);> >struct> node* newNode = (>struct> node*)>malloc>(> >// Creating a new node> >sizeof>(>struct> node));> >// Setting value of node> >setNode(newNode, key, value);> >// Bucket index is empty....no collision> >if> (mp->arr[bucketIndex] == NULL) {> >mp->arr[bucketIndex] = nyNode;> >}> >// Collision> >else> {> >// Adding newNode at the head of> >// linked list which is present> >// at bucket index....insertion at> >// head in linked list> >newNode->neste = mp->arr[bucketIndex];> >mp->arr[bucketIndex] = nyNode;> >}> >return>;> }> void> deleteKey(>struct> hashMap* mp,>char>* key) {> >// Getting bucket index for the> >// given key> >int> bucketIndex = hashFunction(mp, key);> >struct> node* prevNode = NULL;> >// Points to the head of> >// linked list present at> >// bucket index> >struct> node* currNode = mp->arr[bucketIndex];> >while> (currNode != NULL) {> >// Key is matched at delete this> >// node from linked list> >if> (>strcmp>(key, currNode->nøkkel) == 0) {> >// Head node> >// deletion> >if> (currNode == mp->arr[bucketIndex]) {> >mp->arr[bucketIndex] = currNode->neste;> >}> >// Last node or middle node> >else> {> >prevNode->neste = currNode->neste;> }> free>(currNode);> break>;> }> prevNode = currNode;> >currNode = currNode->neste;> >}> return>;> }> char>* search(>struct> hashMap* mp,>char>* key) {> // Getting the bucket index for the given key> int> bucketIndex = hashFunction(mp, key);> // Head of the linked list present at bucket index> struct> node* bucketHead = mp->arr[bucketIndex];> while> (bucketHead != NULL) {> > >// Key is found in the hashMap> >if> (>strcmp>(bucketHead->nøkkel, nøkkel) == 0) {> >return> bucketHead->verdi;> >}> > >bucketHead = bucketHead->neste;> }> // If no key found in the hashMap equal to the given key> char>* errorMssg = (>char>*)>malloc>(>sizeof>(>char>) * 25);> strcpy>(errorMssg,>'Oops! No data found.
'>);> return> errorMssg;> }> // Drivers code> int> main()> {> // Initialize the value of mp> struct> hashMap* mp = (>struct> hashMap*)>malloc>(>sizeof>(>struct> hashMap));> initializeHashMap(mp);> insert(mp,>'Yogaholic'>,>'Anjali'>);> insert(mp,>'pluto14'>,>'Vartika'>);> insert(mp,>'elite_Programmer'>,>'Manish'>);> insert(mp,>'GFG'>,>'techcodeview.com'>);> insert(mp,>'decentBoy'>,>'Mayank'>);> printf>(>'%s
'>, search(mp,>'elite_Programmer'>));> printf>(>'%s
'>, search(mp,>'Yogaholic'>));> printf>(>'%s
'>, search(mp,>'pluto14'>));> printf>(>'%s
'>, search(mp,>'decentBoy'>));> printf>(>'%s
'>, search(mp,>'GFG'>));> // Key is not inserted> printf>(>'%s
'>, search(mp,>'randomKey'>));> printf>(>'
After deletion :
'>);> // Deletion of key> deleteKey(mp,>'decentBoy'>);> // Searching the deleted key> printf>(>'%s
'>, search(mp,>'decentBoy'>));> return> 0;> }> |
>
>Produksjon
Manish Anjali Vartika Mayank techcodeview.com Oops! No data found. After deletion : Oops! No data found.>
Forklaring:
- insertion: Setter inn nøkkel-verdi-paret øverst på en koblet liste som er til stede i den gitte bøtteindeksen. hashFunction: Gir bøtteindeksen for den gitte nøkkelen. Vår hash-funksjon = ASCII-verdi av tegnet * primeNumberx . Primtallet i vårt tilfelle er 31 og verdien av x øker fra 1 til n for påfølgende tegn i en nøkkel. sletting: Sletter nøkkel-verdi-par fra hash-tabellen for den gitte nøkkelen. Den sletter noden fra den koblede listen som inneholder nøkkelverdi-paret. Søk: Søk etter verdien til den gitte nøkkelen.
- Denne implementeringen bruker ikke rehashing-konseptet. Det er en rekke koblede lister med fast størrelse.
- Nøkkel og verdi er begge strenger i det gitte eksemplet.
Tidskompleksitet og romkompleksitet:
Tidskompleksiteten for innsetting og sletting av hashtabeller er O(1) i gjennomsnitt. Det er noen matematiske beregninger som beviser det.
- Tidskompleksitet for innsetting: I gjennomsnittlig tilfelle er den konstant. I verste fall er den lineær. Tidskompleksitet for søk: I gjennomsnittlig tilfelle er den konstant. I verste fall er den lineær. Tidskompleksitet for sletting: I gjennomsnittlige tilfeller er den konstant. I verste fall er den lineær. Romkompleksitet: O(n) da den har n antall elementer.
Relaterte artikler:
- Separat kjettingkollisjonshåndteringsteknikk i hashing.