EN Convolutional Neural Network (CNN) er en type Deep Learning neural nettverksarkitektur som vanligvis brukes i Computer Vision. Datasyn er et felt av kunstig intelligens som gjør det mulig for en datamaskin å forstå og tolke bildet eller visuelle data.
Når det gjelder maskinlæring, Kunstige nevrale nettverk prestere veldig bra. Nevrale nettverk brukes i ulike datasett som bilder, lyd og tekst. Ulike typer nevrale nettverk brukes til forskjellige formål, for eksempel for å forutsi rekkefølgen av ord vi bruker Tilbakevendende nevrale nettverk mer presist en LSTM , på samme måte for bildeklassifisering bruker vi Convolution Neurale nettverk. I denne bloggen skal vi bygge en grunnleggende byggestein for CNN.
I et vanlig nevralt nettverk er det tre typer lag:
struktur i datastruktur
- Inndatalag: Det er laget der vi gir innspill til modellen vår. Antall nevroner i dette laget er lik det totale antallet funksjoner i dataene våre (antall piksler i tilfelle av et bilde).
- Skjult lag: Inndataene fra Input-laget mates deretter inn i det skjulte laget. Det kan være mange skjulte lag avhengig av vår modell og datastørrelse. Hvert skjult lag kan ha forskjellig antall nevroner som generelt er større enn antall funksjoner. Utgangen fra hvert lag beregnes ved matrisemultiplikasjon av utgangen fra det forrige laget med innlæringsbare vekter av det laget og deretter ved å legge til innlærbare skjevheter etterfulgt av aktiveringsfunksjon som gjør nettverket ikke-lineært.
- Utdatalag: Utdataene fra det skjulte laget mates deretter inn i en logistisk funksjon som sigmoid eller softmax som konverterer utdataene fra hver klasse til sannsynlighetsscore for hver klasse.
Dataene mates inn i modellen og utdata fra hvert lag hentes fra trinnet ovenfor kalles mate frem , beregner vi deretter feilen ved hjelp av en feilfunksjon, noen vanlige feilfunksjoner er kryssentropi, kvadrattapfeil osv. Feilfunksjonen måler hvor godt nettverket yter. Etter det forplanter vi oss tilbake til modellen ved å beregne derivatene. Dette trinnet kalles Convolutional Neural Network (CNN) er den utvidede versjonen av kunstige nevrale nettverk (ANN) som hovedsakelig brukes til å trekke ut funksjonen fra det rutenettlignende matrisedatasettet. For eksempel visuelle datasett som bilder eller videoer der datamønstre spiller en omfattende rolle.
CNN arkitektur
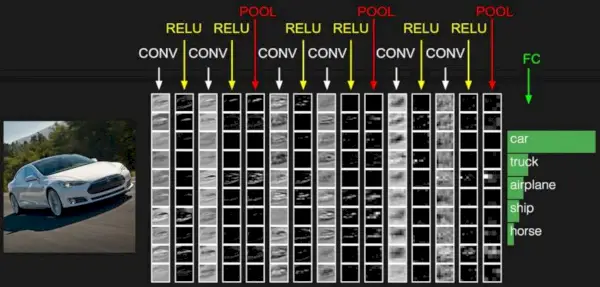
Convolutional Neural Network består av flere lag som inputlaget, Convolutional layer, Pooling layer og fullt tilkoblede lag.

Enkel CNN-arkitektur
Konvolusjonslaget bruker filtre på inngangsbildet for å trekke ut funksjoner, Pooling-laget nedsampler bildet for å redusere beregningen, og det fullt tilkoblede laget gjør den endelige prediksjonen. Nettverket lærer de optimale filtrene gjennom tilbakeforplantning og gradientnedstigning.
Hvordan Convolutional Layers fungerer
Convolution Neural Networks eller covnets er nevrale nettverk som deler sine parametere. Tenk deg at du har et bilde. Det kan representeres som en kuboid som har sin lengde, bredde (bildets dimensjon) og høyde (dvs. kanalen ettersom bilder generelt har røde, grønne og blå kanaler).
Forestill deg nå å ta en liten lapp av dette bildet og kjøre et lite nevralt nettverk, kalt et filter eller kjerne på det, med si K-utganger og representere dem vertikalt. Skyv nå det nevrale nettverket over hele bildet, som et resultat vil vi få et annet bilde med forskjellige bredder, høyder og dybder. I stedet for bare R-, G- og B-kanaler har vi nå flere kanaler, men mindre bredde og høyde. Denne operasjonen kalles Konvolusjon . Hvis lappstørrelsen er den samme som på bildet, vil det være et vanlig nevralt nettverk. På grunn av denne lille lappen har vi færre vekter.
Bildekilde: Deep Learning Udacity
La oss nå snakke om litt matematikk som er involvert i hele konvolusjonsprosessen.
- Konvolusjonslag består av et sett med lærbare filtre (eller kjerner) med små bredder og høyder og samme dybde som inngangsvolum (3 hvis inngangslaget er bildeinndata).
- For eksempel, hvis vi må kjøre konvolusjon på et bilde med dimensjonene 34x34x3. Den mulige størrelsen på filtre kan være axax3, der 'a' kan være noe sånt som 3, 5 eller 7, men mindre sammenlignet med bildedimensjonen.
- Under foroverpasseringen skyver vi hvert filter over hele inngangsvolumet trinn for trinn der hvert trinn kalles skritt (som kan ha en verdi på 2, 3 eller til og med 4 for høydimensjonale bilder) og beregne punktproduktet mellom kjernevektene og lappen fra inngangsvolum.
- Når vi skyver filtrene våre, får vi en 2D-utgang for hvert filter, og vi stable dem sammen som et resultat, vi får utgangsvolum som har en dybde lik antall filtre. Nettverket vil lære alle filtrene.
Lag som brukes til å bygge ConvNets
En komplett Convolution Neural Networks-arkitektur er også kjent som covnets. En ovn er en sekvens av lag, og hvert lag forvandler ett volum til et annet gjennom en differensierbar funksjon.
Typer lag: datasett
La oss ta et eksempel ved å kjøre en kappe på et bilde med dimensjon 32 x 32 x 3.
heltall til streng
- Inndatalag: Det er laget der vi gir innspill til modellen vår. I CNN vil inndata vanligvis være et bilde eller en sekvens av bilder. Dette laget inneholder råinngangen til bildet med bredde 32, høyde 32 og dybde 3.
- Konvolusjonslag: Dette er laget som brukes til å trekke ut funksjonen fra inndatadatasettet. Den bruker et sett med innlærbare filtre kjent som kjernene på inngangsbildene. Filtrene/kjernene er mindre matriser, vanligvis 2×2, 3×3 eller 5×5 form. den glir over inndatabildedataene og beregner punktproduktet mellom kjernevekt og den tilsvarende inndatabildelappen. Utdataene fra dette laget blir referert til som funksjonskart. Anta at vi bruker totalt 12 filtre for dette laget, får vi et utgangsvolum på dimensjon 32 x 32 x 12.
- Aktiveringslag: Ved å legge til en aktiveringsfunksjon til utgangen fra det foregående laget, legger aktiveringslag til ikke-linearitet til nettverket. den vil bruke en elementvis aktiveringsfunksjon på utgangen av konvolusjonslaget. Noen vanlige aktiveringsfunksjoner er gjenoppta : maks(0, x), Fiskete , Utett RELU , etc. Volumet forblir uendret, og utgangsvolumet vil derfor ha dimensjonene 32 x 32 x 12.
- Samlingslag: Dette laget blir med jevne mellomrom satt inn i kappene og hovedfunksjonen er å redusere størrelsen på volumet, noe som gjør at beregningen raskt reduserer minne og forhindrer også overtilpasning. To vanlige typer pooling lag er maks sammenslåing og gjennomsnittlig sammenslåing . Hvis vi bruker et maks basseng med 2 x 2 filtre og skritt 2, vil det resulterende volumet være av dimensjon 16x16x12.
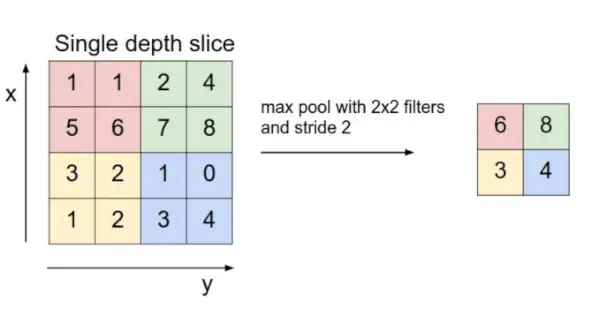
Bildekilde: cs231n.stanford.edu
- Utflating: De resulterende funksjonskartene blir flatet ut til en endimensjonal vektor etter konvolusjonen og sammenslåingslagene, slik at de kan overføres til et fullstendig koblet lag for kategorisering eller regresjon.
- Fullt tilkoblede lag: Den tar input fra forrige lag og beregner den endelige klassifiserings- eller regresjonsoppgaven.
Bildekilde: cs231n.stanford.edu
- Utdatalag: Utdataene fra de fullt tilkoblede lagene blir deretter matet inn i en logistisk funksjon for klassifiseringsoppgaver som sigmoid eller softmax som konverterer utdataene fra hver klasse til sannsynlighetsscore for hver klasse.
Eksempel:
La oss vurdere et bilde og bruke konvolusjonslaget, aktiveringslaget og sammenslåingslaget for å trekke ut den innvendige funksjonen.
css-tekstjustering
Inndatabilde:
Inndatabilde
Steg:
- importere de nødvendige bibliotekene
- angi parameteren
- definere kjernen
- Last inn bildet og plott det.
- Formater bildet på nytt
- Bruk konvolusjonslagsoperasjon og plott utdatabildet.
- Bruk aktiveringslagsoperasjon og plott utdatabildet.
- Bruk pooling layer-operasjon og plott utdatabildet.
Python3
# import the necessary libraries> import> numpy as np> import> tensorflow as tf> import> matplotlib.pyplot as plt> from> itertools>import> product> > # set the param> plt.rc(>'figure'>, autolayout>=>True>)> plt.rc(>'image'>, cmap>=>'magma'>)> > # define the kernel> kernel>=> tf.constant([[>->1>,>->1>,>->1>],> >[>->1>,>8>,>->1>],> >[>->1>,>->1>,>->1>],> >])> > # load the image> image>=> tf.io.read_file(>'Ganesh.webp'plain'>)> image>=> tf.io.decode_jpeg(image, channels>=>1>)> image>=> tf.image.resize(image, size>=>[>300>,>300>])> > # plot the image> img>=> tf.squeeze(image).numpy()> plt.figure(figsize>=>(>5>,>5>))> plt.imshow(img, cmap>=>'gray'>)> plt.axis(>'off'>)> plt.title(>'Original Gray Scale image'>)> plt.show();> > > # Reformat> image>=> tf.image.convert_image_dtype(image, dtype>=>tf.float32)> image>=> tf.expand_dims(image, axis>=>0>)> kernel>=> tf.reshape(kernel, [>*>kernel.shape,>1>,>1>])> kernel>=> tf.cast(kernel, dtype>=>tf.float32)> > # convolution layer> conv_fn>=> tf.nn.conv2d> > image_filter>=> conv_fn(> >input>=>image,> >filters>=>kernel,> >strides>=>1>,># or (1, 1)> >padding>=>'SAME'>,> )> > plt.figure(figsize>=>(>15>,>5>))> > # Plot the convolved image> plt.subplot(>1>,>3>,>1>)> > plt.imshow(> >tf.squeeze(image_filter)> )> plt.axis(>'off'>)> plt.title(>'Convolution'>)> > # activation layer> relu_fn>=> tf.nn.relu> # Image detection> image_detect>=> relu_fn(image_filter)> > plt.subplot(>1>,>3>,>2>)> plt.imshow(> ># Reformat for plotting> >tf.squeeze(image_detect)> )> > plt.axis(>'off'>)> plt.title(>'Activation'>)> > # Pooling layer> pool>=> tf.nn.pool> image_condense>=> pool(>input>=>image_detect,> >window_shape>=>(>2>,>2>),> >pooling_type>=>'MAX'>,> >strides>=>(>2>,>2>),> >padding>=>'SAME'>,> >)> > plt.subplot(>1>,>3>,>3>)> plt.imshow(tf.squeeze(image_condense))> plt.axis(>'off'>)> plt.title(>'Pooling'>)> plt.show()> |
>
unix toppkommando
>
Produksjon :

Originalt gråtonebilde
Produksjon
Fordeler med konvolusjonelle nevrale nettverk (CNN):
- God til å oppdage mønstre og funksjoner i bilder, videoer og lydsignaler.
- Robust til translasjon, rotasjon og skaleringsinvarians.
- End-to-end trening, ikke behov for manuell funksjonsutvinning.
- Kan håndtere store datamengder og oppnå høy nøyaktighet.
Ulemper med konvolusjonelle nevrale nettverk (CNN):
- Beregningsmessig dyrt å trene og krever mye minne.
- Kan være utsatt for overtilpasning hvis ikke nok data eller riktig regularisering brukes.
- Krever store mengder merkede data.
- Tolkbarheten er begrenset, det er vanskelig å forstå hva nettverket har lært.
Ofte stilte spørsmål (FAQs)
1: Hva er et Convolutional Neural Network (CNN)?
A Convolutional Neural Network (CNN) er en type dyplæringsnevrale nettverk som er godt egnet for bilde- og videoanalyse. CNN-er bruker en serie konvolusjoner og sammenslåingslag for å trekke ut funksjoner fra bilder og videoer, og bruker deretter disse funksjonene til å klassifisere eller oppdage objekter eller scener.
2: Hvordan fungerer CNN?
CNN-er fungerer ved å bruke en serie med konvolusjon og sammenslåing av lag på et inngangsbilde eller video. Convolution-lag trekker ut funksjoner fra inngangen ved å skyve et lite filter, eller kjerne, over bildet eller videoen og beregne punktproduktet mellom filteret og inngangen. Samlingslag nedsamler deretter utdataene fra konvolusjonslagene for å redusere dimensjonaliteten til dataene og gjøre dem mer beregningseffektive.
sammenligne i java
3: Hva er noen vanlige aktiveringsfunksjoner som brukes i CNN-er?
Noen vanlige aktiveringsfunksjoner som brukes i CNN inkluderer:
- Rectified Linear Unit (ReLU): ReLU er en ikke-mettende aktiveringsfunksjon som er beregningseffektiv og enkel å trene.
- Leaky Rectified Linear Unit (Leaky ReLU): Leaky ReLU er en variant av ReLU som lar en liten mengde negativ gradient strømme gjennom nettverket. Dette kan bidra til å forhindre at nettverket dør under trening.
- Parametric Rectified Linear Unit (PReLU): PReLU er en generalisering av Leaky ReLU som gjør at helningen til den negative gradienten kan læres.
4: Hva er hensikten med å bruke flere konvolusjonslag i et CNN?
Ved å bruke flere konvolusjonslag i en CNN kan nettverket lære stadig mer komplekse funksjoner fra inngangsbildet eller videoen. De første konvolusjonslagene lærer enkle funksjoner, som kanter og hjørner. De dypere konvolusjonslagene lærer mer komplekse funksjoner, for eksempel former og objekter.
5: Hva er noen vanlige regulariseringsteknikker som brukes i CNN?
Regulariseringsteknikker brukes for å forhindre at CNN-er overtilpasser treningsdataene. Noen vanlige regulariseringsteknikker som brukes i CNN inkluderer:
- Frafall: Frafall faller tilfeldig ut nevroner fra nettverket under trening. Dette tvinger nettverket til å lære mer robuste funksjoner som ikke er avhengige av noen enkelt nevron.
- L1-regularisering: L1-regularisering regulariserer den absolutte verdien av vektene i nettverket. Dette kan bidra til å redusere antall vekter og gjøre nettverket mer effektivt.
- L2-regularisering: L2-regularisering regulariserer kvadratet av vektene i nettverket. Dette kan også bidra til å redusere antall vekter og gjøre nettet mer effektivt.
6: Hva er forskjellen mellom et konvolusjonslag og et sammenslåingslag?
Et konvolusjonslag trekker ut funksjoner fra et inngangsbilde eller video, mens et sammenslåingslag nedsampler utdataene fra konvolusjonslagene. Konvolusjonslag bruker en rekke filtre for å trekke ut funksjoner, mens sammenslåingslag bruker en rekke teknikker for å nedsample dataene, for eksempel maksimal sammenslåing og gjennomsnittlig sammenslåing.