Logistisk regresjon er en overvåket maskinlæringsalgoritme brukes til klassifiseringsoppgaver hvor målet er å forutsi sannsynligheten for at en instans tilhører en gitt klasse eller ikke. Logistisk regresjon er en statistisk algoritme som analyserer forholdet mellom to datafaktorer. Artikkelen utforsker det grunnleggende om logistisk regresjon, dens typer og implementeringer.
Innholdsfortegnelse
- Hva er logistisk regresjon?
- Logistikkfunksjon – Sigmoidfunksjon
- Typer logistisk regresjon
- Forutsetninger om logistisk regresjon
- Hvordan fungerer logistisk regresjon?
- Kodeimplementering for logistikkregresjon
- Presisjon-gjenkalling avveining i logistisk regresjonsterskelinnstilling
- Hvordan evaluere logistisk regresjonsmodell?
- Forskjeller mellom lineær og logistisk regresjon
Hva er logistisk regresjon?
Logistisk regresjon brukes for binær klassifisering hvor vi bruker sigmoid funksjon , som tar inndata som uavhengige variabler og produserer en sannsynlighetsverdi mellom 0 og 1.
For eksempel har vi to klasser Klasse 0 og Klasse 1 hvis verdien av logistikkfunksjonen for en inngang er større enn 0,5 (terskelverdi), så hører den til Klasse 1 ellers tilhører den Klasse 0. Det refereres til som regresjon fordi den er forlengelsen av lineær regresjon men brukes hovedsakelig til klassifiseringsproblemer.
hvilke måneder er q1
Viktige punkter:
- Logistisk regresjon forutsier produksjonen av en kategorisk avhengig variabel. Derfor må utfallet være en kategorisk eller diskret verdi.
- Det kan være enten Ja eller Nei, 0 eller 1, sant eller usant, osv., men i stedet for å gi den nøyaktige verdien som 0 og 1, gir det sannsynlighetsverdiene som ligger mellom 0 og 1.
- I logistisk regresjon, i stedet for å tilpasse en regresjonslinje, tilpasser vi en S-formet logistisk funksjon, som forutsier to maksimale verdier (0 eller 1).
Logistikkfunksjon – Sigmoidfunksjon
- Sigmoid-funksjonen er en matematisk funksjon som brukes til å kartlegge de predikerte verdiene til sannsynligheter.
- Den kartlegger enhver reell verdi til en annen verdi innenfor et område på 0 og 1. Verdien av den logistiske regresjonen må være mellom 0 og 1, som ikke kan gå utover denne grensen, så den danner en kurve som S-formen.
- S-formkurven kalles Sigmoid-funksjonen eller logistikkfunksjonen.
- I logistisk regresjon bruker vi begrepet terskelverdi, som definerer sannsynligheten for enten 0 eller 1. Som at verdier over terskelverdien har en tendens til 1, og en verdi under terskelverdiene har en tendens til 0.
Typer logistisk regresjon
På grunnlag av kategoriene kan logistisk regresjon klassifiseres i tre typer:
- Binomial: I binomial logistisk regresjon kan det bare være to mulige typer av de avhengige variablene, for eksempel 0 eller 1, Bestått eller Ikke bestått, etc.
- Multinomial: I multinomial logistisk regresjon kan det være 3 eller flere mulige uordnede typer av den avhengige variabelen, for eksempel katt, hund eller sau
- Ordinal: I ordinal logistisk regresjon kan det være 3 eller flere mulige sorterte typer avhengige variabler, for eksempel lav, middels eller høy.
Forutsetninger om logistisk regresjon
Vi vil utforske forutsetningene om logistisk regresjon, da det er viktig å forstå disse forutsetningene for å sikre at vi bruker riktig anvendelse av modellen. Antakelsen inkluderer:
- Uavhengige observasjoner: Hver observasjon er uavhengig av den andre. betyr at det ikke er noen korrelasjon mellom noen inputvariabler.
- Binære avhengige variabler: Det tar antagelsen at den avhengige variabelen må være binær eller dikotom, noe som betyr at den bare kan ta to verdier. For mer enn to kategorier brukes SoftMax-funksjoner.
- Linearitetsforhold mellom uavhengige variabler og logoddser: Forholdet mellom de uavhengige variablene og logoddsene til den avhengige variabelen bør være lineær.
- Ingen uteliggere: Det skal ikke være noen uteliggere i datasettet.
- Stor prøvestørrelse: Prøvestørrelsen er tilstrekkelig stor
Terminologier involvert i logistisk regresjon
Her er noen vanlige termer involvert i logistisk regresjon:
- Uavhengige variabler: Inndatakarakteristikkene eller prediktorfaktorene brukt på den avhengige variabelens prediksjoner.
- Avhengig variabel: Målvariabelen i en logistisk regresjonsmodell, som vi prøver å forutsi.
- Logistikkfunksjon: Formelen som brukes til å representere hvordan de uavhengige og avhengige variablene forholder seg til hverandre. Den logistiske funksjonen transformerer inngangsvariablene til en sannsynlighetsverdi mellom 0 og 1, som representerer sannsynligheten for at den avhengige variabelen er 1 eller 0.
- Odds: Det er forholdet mellom noe som skjer og noe som ikke skjer. det er forskjellig fra sannsynlighet ettersom sannsynligheten er forholdet mellom noe som skjer og alt som kan skje.
- Logg-oddser: Log-oddsene, også kjent som logit-funksjonen, er den naturlige logaritmen til oddsen. I logistisk regresjon er logoddsene til den avhengige variabelen modellert som en lineær kombinasjon av de uavhengige variablene og skjæringspunktet.
- Koeffisient: Den logistiske regresjonsmodellens estimerte parametere viser hvordan de uavhengige og avhengige variablene forholder seg til hverandre.
- Avskjære: Et konstant ledd i den logistiske regresjonsmodellen, som representerer logoddsene når alle uavhengige variabler er lik null.
- Maksimal sannsynlighetsestimering : Metoden som brukes til å estimere koeffisientene til den logistiske regresjonsmodellen, som maksimerer sannsynligheten for å observere dataene gitt modellen.
Hvordan fungerer logistisk regresjon?
Den logistiske regresjonsmodellen transformerer lineær regresjon funksjon kontinuerlig verdiutgang til kategorisk verdiutgang ved hjelp av en sigmoid-funksjon, som kartlegger ethvert sett med uavhengige variabler med reell verdi til en verdi mellom 0 og 1. Denne funksjonen er kjent som den logistiske funksjonen.
La de uavhengige inngangsfunksjonene være:
og den avhengige variabelen er Y som bare har binær verdi, dvs. 0 eller 1.
Bruk deretter den multi-lineære funksjonen på inngangsvariablene X.
Her
hva vi diskuterte ovenfor er lineær regresjon .
Sigmoid funksjon
Nå bruker vi sigmoid funksjon hvor inngangen vil være z og vi finner sannsynligheten mellom 0 og 1. dvs. predikert y.
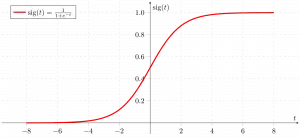
Sigmoid funksjon
Som vist ovenfor, konverterer figuren sigmoid-funksjonen de kontinuerlige variable dataene til sannsynlighet dvs. mellom 0 og 1.
sigma(z) tenderer mot 1 asz ightarrowinfty sigma(z) tenderer mot 0 somz ightarrow-infty sigma(z) er alltid avgrenset mellom 0 og 1
hvor sannsynligheten for å være en klasse kan måles som:
Logistisk regresjonsligning
Oddet er forholdet mellom noe som oppstår og noe som ikke skjer. det er forskjellig fra sannsynlighet ettersom sannsynligheten er forholdet mellom noe som skjer og alt som kan skje. så rart vil være:
java arraylist sortert
Bruker naturlig pålogging odd. da vil loggodd være:
da vil den endelige logistiske regresjonsligningen være:
Sannsynlighetsfunksjon for logistisk regresjon
De forutsagte sannsynlighetene vil være:
- for y=1 De predikerte sannsynlighetene vil være: p(X;b,w) = p(x)
- for y = 0 De predikerte sannsynlighetene vil være: 1-p(X;b,w) = 1-p(x)
Tar naturlige tømmerstokker på begge sider
Gradient av log-likelihood-funksjonen
For å finne de maksimale sannsynlighetsestimatene, differensierer vi w.r.t.
Kodeimplementering for logistikkregresjon
Binomial logistisk regresjon:
Målvariabel kan bare ha 2 mulige typer: 0 eller 1 som kan representere seier vs tap, bestått vs mislykket, død vs levende, etc., i dette tilfellet brukes sigmoid-funksjoner, som allerede er diskutert ovenfor.
Importere nødvendige biblioteker basert på kravet til modell. Denne Python-koden viser hvordan du bruker brystkreftdatasettet til å implementere en logistisk regresjonsmodell for klassifisering.
Python3 # import the necessary libraries from sklearn.datasets import load_breast_cancer from sklearn.linear_model import LogisticRegression from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score # load the breast cancer dataset X, y = load_breast_cancer(return_X_y=True) # split the train and test dataset X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=23) # LogisticRegression clf = LogisticRegression(random_state=0) clf.fit(X_train, y_train) # Prediction y_pred = clf.predict(X_test) acc = accuracy_score(y_test, y_pred) print('Logistic Regression model accuracy (in %):', acc*100)> Produksjon :
Logistikkregresjonsmodellnøyaktighet (i %): 95,6140350877193
Multinomial logistisk regresjon:
Målvariabel kan ha 3 eller flere mulige typer som ikke er sortert (dvs. typer har ingen kvantitativ betydning) som sykdom A vs sykdom B vs sykdom C.
I dette tilfellet brukes softmax-funksjonen i stedet for sigmoid-funksjonen. Softmax funksjon for K-klasser vil være:
Her, K representerer antall elementer i vektoren z, og i, j itererer over alle elementene i vektoren.
Da vil sannsynligheten for klasse c være:
I multinomial logistisk regresjon kan utdatavariabelen ha mer enn to mulige diskrete utganger . Tenk på sifferdatasettet.
Python3 from sklearn.model_selection import train_test_split from sklearn import datasets, linear_model, metrics # load the digit dataset digits = datasets.load_digits() # defining feature matrix(X) and response vector(y) X = digits.data y = digits.target # splitting X and y into training and testing sets X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4, random_state=1) # create logistic regression object reg = linear_model.LogisticRegression() # train the model using the training sets reg.fit(X_train, y_train) # making predictions on the testing set y_pred = reg.predict(X_test) # comparing actual response values (y_test) # with predicted response values (y_pred) print('Logistic Regression model accuracy(in %):', metrics.accuracy_score(y_test, y_pred)*100)> Produksjon:
java liste metoder
Logistikkregresjonsmodellnøyaktighet (i %): 96,52294853963839
Hvordan evaluere logistisk regresjonsmodell?
Vi kan evaluere den logistiske regresjonsmodellen ved å bruke følgende beregninger:
- Nøyaktighet: Nøyaktighet gir andelen korrekt klassifiserte forekomster.
Accuracy = frac{True , Positives + True , Negatives}{Total}
- Presisjon: Presisjon fokuserer på nøyaktigheten av positive spådommer.
Precision = frac{True , Positives }{True, Positives + False , Positives}
- Tilbakekalling (sensitivitet eller sann positiv rate): Minnes måler andelen korrekt predikerte positive tilfeller blant alle faktiske positive tilfeller.
Recall = frac{ True , Positives}{True, Positives + False , Negatives}
- F1-poengsum: F1-score er det harmoniske middelet for presisjon og gjenkalling.
F1 , Score = 2 * frac{Precision * Recall}{Precision + Recall}
- Område under mottakerens driftskarakteristikk (AUC-ROC): ROC-kurven plotter den sanne positive frekvensen mot den falske positive frekvensen ved forskjellige terskler. AUC-ROC måler arealet under denne kurven, og gir et samlet mål på en modells ytelse på tvers av ulike klassifiseringsterskler.
- Område under presisjonsgjenkallingskurven (AUC-PR): I likhet med AUC-ROC, AUC-PR måler området under presisjon-gjenkalling-kurven, og gir et sammendrag av en modells ytelse på tvers av forskjellige presisjon-gjenkalling-avveininger.
Presisjon-gjenkalling avveining i logistisk regresjonsterskelinnstilling
Logistisk regresjon blir en klassifiseringsteknikk først når en beslutningsterskel bringes inn i bildet. Innstillingen av terskelverdien er et svært viktig aspekt ved logistisk regresjon og er avhengig av selve klassifiseringsproblemet.
Beslutningen om verdien av terskelverdien påvirkes i stor grad av verdiene til presisjon og tilbakekalling. Ideelt sett ønsker vi at både presisjon og gjenkalling skal være 1, men dette er sjelden tilfelle.
I tilfelle av en Avveining mellom presisjon og tilbakekalling , bruker vi følgende argumenter for å bestemme terskelen:
- Lav presisjon/høy gjenkalling: I applikasjoner hvor vi ønsker å redusere antall falske negative uten nødvendigvis å redusere antall falske positive, velger vi en beslutningsverdi som har en lav verdi på Precision eller en høy verdi på Recall. For eksempel, i en søknad om kreftdiagnose, ønsker vi ikke at en berørt pasient skal klassifiseres som ikke berørt uten å legge stor vekt på dersom pasienten feilaktig blir diagnostisert med kreft. Dette er fordi fravær av kreft kan oppdages ved ytterligere medisinske sykdommer, men tilstedeværelsen av sykdommen kan ikke oppdages hos en allerede avvist kandidat.
- Høy presisjon/lav gjenkalling: I applikasjoner hvor vi ønsker å redusere antall falske positive uten nødvendigvis å redusere antall falske negative, velger vi en beslutningsverdi som har høy verdi på Presisjon eller lav verdi på Recall. For eksempel, hvis vi klassifiserer kunder om de vil reagere positivt eller negativt på en personlig annonse, vil vi være helt sikre på at kunden vil reagere positivt på annonsen, fordi ellers kan en negativ reaksjon føre til tap av potensielt salg fra kunde.
Forskjeller mellom lineær og logistisk regresjon
Forskjellen mellom lineær regresjon og logistisk regresjon er at lineær regresjonsutgang er den kontinuerlige verdien som kan være hva som helst mens logistisk regresjon forutsier sannsynligheten for at en forekomst tilhører en gitt klasse eller ikke.
Lineær regresjon | Logistisk regresjon |
|---|---|
Lineær regresjon brukes til å forutsi den kontinuerlige avhengige variabelen ved å bruke et gitt sett med uavhengige variabler. | Logistisk regresjon brukes til å forutsi den kategoriske avhengige variabelen ved å bruke et gitt sett med uavhengige variabler. |
Lineær regresjon brukes for å løse regresjonsproblem. | Den brukes til å løse klassifiseringsproblemer. |
I denne predikerer vi verdien av kontinuerlige variabler | I denne predikerer vi verdier av kategoriske variabler |
I denne finner vi best passform linje. | I denne finner vi S-Kurve. |
Minste kvadratisk estimeringsmetode brukes for estimering av nøyaktighet. | Maksimal sannsynlighetsestimeringsmetode brukes for estimering av nøyaktighet. |
Utgangen må være kontinuerlig verdi, som pris, alder osv. | Utdata må være kategorisk verdi som 0 eller 1, Ja eller nei osv. |
Det krevde lineært forhold mellom avhengige og uavhengige variabler. | Det krevde ikke lineært forhold. instansiering i java |
Det kan være kolinearitet mellom de uavhengige variablene. | Det skal ikke være kolinearitet mellom uavhengige variabler. |
Logistisk regresjon – ofte stilte spørsmål (FAQs)
Hva er logistisk regresjon i maskinlæring?
Logistisk regresjon er en statistisk metode for å utvikle maskinlæringsmodeller med binære avhengige variabler, dvs. binære. Logistisk regresjon er en statistisk teknikk som brukes til å beskrive data og forholdet mellom én avhengig variabel og én eller flere uavhengige variabler.
Hva er de tre typene logistisk regresjon?
Logistisk regresjon er klassifisert i tre typer: binær, multinomial og ordinal. De er forskjellige i utførelse så vel som teori. Binær regresjon er opptatt av to mulige utfall: ja eller nei. Multinomial logistisk regresjon brukes når det er tre eller flere verdier.
Hvorfor brukes logistisk regresjon for klassifiseringsproblem?
Logistisk regresjon er lettere å implementere, tolke og trene. Den klassifiserer ukjente poster veldig raskt. Når datasettet er lineært separerbart, gir det gode resultater. Modellkoeffisienter kan tolkes som indikatorer for funksjonsviktighet.
Hva skiller logistisk regresjon fra lineær regresjon?
Mens lineær regresjon brukes til å forutsi kontinuerlige utfall, brukes logistisk regresjon til å forutsi sannsynligheten for at en observasjon faller inn i en bestemt kategori. Logistisk regresjon bruker en S-formet logistikkfunksjon for å kartlegge predikerte verdier mellom 0 og 1.
Hvilken rolle spiller logistikkfunksjonen i logistisk regresjon?
Logistisk regresjon er avhengig av den logistiske funksjonen for å konvertere utdataene til en sannsynlighetsscore. Denne poengsummen representerer sannsynligheten for at en observasjon tilhører en bestemt klasse. Den S-formede kurven hjelper til med å terskelgjøre og kategorisere data i binære utfall.