Et viktig aspekt ved Maskinlæring er modellevaluering. Du må ha en eller annen mekanisme for å evaluere modellen din. Det er her disse ytelsesmålene kommer inn i bildet, de gir oss en følelse av hvor god en modell er. Hvis du er kjent med noe av det grunnleggende om Maskinlæring da må du ha kommet over noen av disse beregningene, som nøyaktighet, presisjon, tilbakekalling, auc-roc, etc., som vanligvis brukes til klassifiseringsoppgaver. I denne artikkelen vil vi utforske i dybden en slik beregning, som er AUC-ROC-kurven.
Innholdsfortegnelse
- Hva er AUC-ROC-kurven?
- Nøkkeltermer brukt i AUC og ROC Curve
- Forholdet mellom sensitivitet, spesifisitet, FPR og terskel.
- Hvordan fungerer AUC-ROC?
- Når skal vi bruke AUC-ROC-evalueringsberegningen?
- Spekulerer på ytelsen til modellen
- Forstå AUC-ROC-kurven
- Implementering ved hjelp av to ulike modeller
- Hvordan bruke ROC-AUC for en multi-klasse modell?
- Vanlige spørsmål for AUC ROC Curve i maskinlæring
Hva er AUC-ROC-kurven?
AUC-ROC-kurven, eller Area Under the Receiver Operating Characteristic-kurve, er en grafisk representasjon av ytelsen til en binær klassifiseringsmodell ved forskjellige klassifiseringsterskler. Det brukes ofte i maskinlæring for å vurdere en modells evne til å skille mellom to klasser, typisk den positive klassen (f.eks. tilstedeværelse av en sykdom) og den negative klassen (f.eks. fravær av en sykdom).
La oss først forstå betydningen av de to begrepene ROC og AUC .
- ROC : Driftsegenskaper for mottakeren
- AUC : Område under kurve
Receiver Operating Characteristics (ROC) kurve
ROC står for Receiver Operating Characteristics, og ROC-kurven er den grafiske representasjonen av effektiviteten til den binære klassifiseringsmodellen. Den plotter den sanne positive raten (TPR) vs den falske positive raten (FPR) ved forskjellige klassifiseringsterskler.
Område under kurve (AUC) Kurve:
AUC står for Area Under the Curve, og AUC-kurven representerer arealet under ROC-kurven. Den måler den generelle ytelsen til den binære klassifiseringsmodellen. Siden både TPR og FPR varierer mellom 0 og 1, vil området alltid ligge mellom 0 og 1, og En større verdi av AUC betyr bedre modellytelse. Vårt hovedmål er å maksimere dette området for å ha den høyeste TPR og laveste FPR ved den gitte terskelen. AUC måler sannsynligheten for at modellen vil tildele en tilfeldig valgt positiv forekomst en høyere predikert sannsynlighet sammenlignet med en tilfeldig valgt negativ forekomst.
Den representerer sannsynlighet som vår modell kan skille mellom de to klassene som er tilstede i målet vårt.
ROC-AUC Klassifisering Evaluering Metrikk
Nøkkeltermer brukt i AUC og ROC Curve
1. TPR og FPR
Dette er den vanligste definisjonen du ville ha møtt når du ville Google AUC-ROC. I utgangspunktet er ROC-kurven en graf som viser ytelsen til en klassifiseringsmodell ved alle mulige terskler (terskel er en bestemt verdi utover som du sier at et punkt tilhører en bestemt klasse). Kurven er plottet mellom to parametere
- TPR – Sann positiv rate
- FPR – Falsk positiv rate
Før vi forstår, la TPR og FPR oss raskt se på forvirringsmatrise .
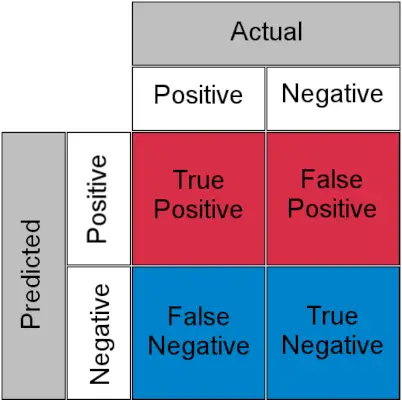
Forvirringsmatrise for en klassifiseringsoppgave
- Ekte positiv : Faktisk positiv og spådd som positiv
- Ekte negativ : Faktisk negativ og spådd som negativ
- Falsk positiv (Type I-feil) : Faktisk negativ, men spådd som positiv
- Falsk negativ (Type II-feil) : Faktisk positiv, men spådd som negativ
Enkelt sagt kan du kalle falsk positiv en falsk alarm og falsk negativ a gå glipp av . La oss nå se på hva TPR og FPR er.
2. Sensitivitet / sann positiv rate / tilbakekalling
I utgangspunktet er TPR/Recall/Sensitivitet forholdet mellom positive eksempler som er korrekt identifisert. Den representerer modellens evne til å identifisere positive tilfeller korrekt og beregnes som følger:

Sensitivitet/Tilbakekalling/TPR måler andelen av faktiske positive tilfeller som er korrekt identifisert av modellen som positive.
3. Falsk positiv rate
FPR er forholdet mellom negative eksempler som er feilklassifisert.

4. Spesifisitet
Spesifisitet måler andelen faktiske negative forekomster som er korrekt identifisert av modellen som negative. Det representerer modellens evne til å identifisere negative forekomster korrekt

Og som tidligere sagt er ROC ingenting annet enn plottet mellom TPR og FPR over alle mulige terskler og AUC er hele området under denne ROC-kurven.
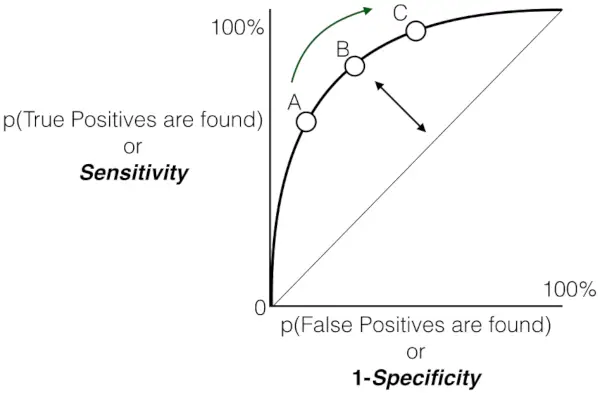
Plott for følsomhet versus falsk positiv rate
Forholdet mellom sensitivitet, spesifisitet, FPR og terskel .
Sensitivitet og spesifisitet:
- Omvendt forhold: sensitivitet og spesifisitet har en omvendt sammenheng. Når den ene øker, har den andre en tendens til å avta. Dette gjenspeiler den iboende avveiningen mellom sanne positive og sanne negative priser.
- Tuning via Threshold: Ved å justere terskelverdien kan vi kontrollere balansen mellom sensitivitet og spesifisitet. Lavere terskler fører til høyere sensitivitet (mer sanne positive) på bekostning av spesifisitet (flere falske positive). Omvendt øker en heving av terskelen spesifisitet (færre falske positive), men ofrer sensitivitet (flere falske negative).
Terskel og falsk positiv rate (FPR):
- FPR og spesifisitetstilkobling: False Positive Rate (FPR) er ganske enkelt komplementet til spesifisitet (FPR = 1 – spesifisitet). Dette betyr det direkte forholdet mellom dem: høyere spesifisitet oversettes til lavere FPR, og omvendt.
- FPR-endringer med TPR: På samme måte, som du har observert, er True Positive Rate (TPR) og FPR også koblet sammen. En økning i TPR (mer sanne positive) fører generelt til en økning i FPR (mer falske positive). Omvendt resulterer et fall i TPR (færre sanne positive) i en nedgang i FPR (færre falske positive)
Hvordan fungerer AUC-ROC?
Vi så på den geometriske tolkningen, men jeg antar at det fortsatt ikke er nok til å utvikle intuisjonen bak hva 0,75 AUC faktisk betyr, la oss nå se på AUC-ROC fra et sannsynlighetsperspektiv. La oss først snakke om hva AUC gjør, og senere vil vi bygge vår forståelse på toppen av dette
AUC måler hvor godt en modell er i stand til å skille mellom klasser.
En AUC på 0,75 vil faktisk bety at la oss si at vi tar to datapunkter som tilhører separate klasser, så er det en 75 % sjanse for at modellen vil være i stand til å skille dem eller rangere dem riktig, dvs. positivt punkt har en høyere prediksjonssannsynlighet enn det negative. klasse. (forutsatt at en høyere prediksjonssannsynlighet betyr at punktet ideelt sett vil tilhøre den positive klassen). Her er et lite eksempel for å gjøre ting mer tydelig.
Indeks | Klasse | Sannsynlighet |
|---|---|---|
P1 | 1 | 0,95 |
P2 | 1 | 0,90 |
P3 | 0 | 0,85 |
P4 | 0 | 0,81 |
P5 | 1 | 0,78 |
P6 | 0 | 0,70 |
Her har vi 6 punkter der P1, P2 og P5 tilhører klasse 1 og P3, P4 og P6 tilhører klasse 0 og vi er tilsvarende predikerte sannsynligheter i Sannsynlighet-kolonnen, som vi sa hvis vi tar to punkter som tilhører separate klasser så hva er sannsynligheten for at modellen rangerer dem riktig.
Vi vil ta alle mulige par slik at det ene poenget tilhører klasse 1 og det andre tilhører klasse 0, vi vil ha totalt 9 slike par under er alle disse 9 mulige parene.
Par | er korrekt |
|---|---|
(P1,P3) | Ja |
(P1,P4) | Ja |
(P1,P6) | Ja |
(P2,P3) | Ja |
(P2,P4) | Ja |
(P2,P6) | Ja pyspark |
(P3,P5) | Nei |
(P4,P5) | Nei |
(P5,P6) | Ja |
Her kolonnen er Korrekt forteller om det nevnte paret er riktig rangert basert på den predikerte sannsynligheten, dvs. klasse 1 poeng har høyere sannsynlighet enn klasse 0 poeng, i 7 av disse 9 mulige parene er klasse 1 rangert høyere enn klasse 0, eller vi kan si at det er 77 % sjanse for at hvis du velger et poengpar som tilhører separate klasser, vil modellen kunne skille dem riktig. Nå tror jeg du kanskje har litt intuisjon bak dette AUC-nummeret, bare for å fjerne ytterligere tvil, la oss validere det ved å bruke Scikit learns AUC-ROC-implementering.
Python3
import> numpy as np> from> sklearn .metrics>import> roc_auc_score> y_true>=> [>1>,>1>,>0>,>0>,>1>,>0>]> y_pred>=> [>0.95>,>0.90>,>0.85>,>0.81>,>0.78>,>0.70>]> auc>=> np.>round>(roc_auc_score(y_true, y_pred),>3>)> print>(>'Auc for our sample data is {}'>.>format>(auc))> |
>
>
Produksjon:
AUC for our sample data is 0.778>
Når skal vi bruke AUC-ROC-evalueringsberegningen?
Det er noen områder hvor bruk av ROC-AUC kanskje ikke er ideelt. I tilfeller der datasettet er svært ubalansert, ROC-kurven kan gi en altfor optimistisk vurdering av modellens ytelse . Denne optimismeskjevheten oppstår fordi ROC-kurvens falske positive rate (FPR) kan bli svært liten når antallet faktiske negative er stort.
Ser på FPR-formelen,

vi observerer ,
- Den negative klassen er i flertall, nevneren til FPR er dominert av sanne negative, på grunn av hvilke FPR blir mindre følsom for endringer i spådommer knyttet til minoritetsklassen (positiv klasse).
- ROC-kurver kan være passende når kostnadene for falske positive og falske negative er balansert og datasettet ikke er sterkt ubalansert.
I så fall Presisjons-gjenkallingskurver kan brukes som gir en alternativ evalueringsmetrikk som er mer egnet for ubalanserte datasett, med fokus på ytelsen til klassifikatoren med hensyn til den positive (minoritets)klassen.
Spekulerer på ytelsen til modellen
- En høy AUC (nær 1) indikerer utmerket diskriminerende kraft. Dette betyr at modellen er effektiv til å skille mellom de to klassene, og dens spådommer er pålitelige.
- En lav AUC (nær 0) tyder på dårlig ytelse. I dette tilfellet sliter modellen med å skille mellom de positive og negative klassene, og spådommene er kanskje ikke til å stole på.
- AUC rundt 0,5 antyder at modellen i hovedsak gjør tilfeldige gjetninger. Den viser ingen evne til å skille klassene, noe som indikerer at modellen ikke lærer noen meningsfulle mønstre fra dataene.
Forstå AUC-ROC-kurven
I en ROC-kurve representerer x-aksen typisk False Positive Rate (FPR), og y-aksen representerer True Positive Rate (TPR), også kjent som Sensitivity eller Recall. Så en høyere x-akseverdi (mot høyre) på ROC-kurven indikerer en høyere falsk positiv rate, og en høyere y-akseverdi (mot toppen) indikerer en høyere sann positiv rate. ROC-kurven er en grafisk representasjon av avveiningen mellom sann positiv rate og falsk positiv rate ved ulike terskler. Den viser ytelsen til en klassifiseringsmodell ved forskjellige klassifiseringsterskler. AUC (Area Under the Curve) er et sammendrag av ROC-kurvens ytelse. Valget av terskelen avhenger av de spesifikke kravene til problemet du prøver å løse og avveiningen mellom falske positive og falske negative som er akseptabelt i din sammenheng.
- Hvis du ønsker å prioritere å redusere falske positiver (minimere sjansene for å merke noe som positivt når det ikke er det), kan du velge en terskel som resulterer i en lavere falsk positiv rate.
- Hvis du vil prioritere å øke sanne positive (fange så mange faktiske positive som mulig), kan du velge en terskel som resulterer i en høyere sann positiv rate.
La oss vurdere et eksempel for å illustrere hvordan ROC-kurver genereres for forskjellige terskler og hvordan en bestemt terskel tilsvarer en forvirringsmatrise. Anta at vi har en binært klassifiseringsproblem med en modell som forutsier om en e-post er spam (positiv) eller ikke spam (negativ).
La oss vurdere de hypotetiske dataene,
Ekte etiketter: [1, 0, 1, 0, 1, 1, 0, 0, 1, 0]
Anslåtte sannsynligheter: [0,8, 0,3, 0,6, 0,2, 0,7, 0,9, 0,4, 0,1, 0,75, 0,55]
Tilfelle 1: Terskel = 0,5
Ekte etiketter | Forutsagte sannsynligheter | Forutsagte etiketter |
|---|---|---|
| 1 | 0,8 | 1 |
| 0 | 0,3 | 0 |
| 1 | 0,6 | 1 |
| 0 | 0,2 | 0 |
| 1 | 0,7 | 1 |
| 1 | 0,9 | 1 |
| 0 | 0,4 | 0 |
| 0 | 0,1 | 0 |
| 1 | 0,75 | 1 |
| 0 | 0,55 | 1 |
Forvirringsmatrise basert på spådommene ovenfor
| Prediksjon = 0 | Prediksjon = 1 |
|---|---|---|
Faktisk = 0 | TP=4 | FN=1 |
Faktisk = 1 | FP=0 | TN=5 |
Tilsvarende,
- Sann positiv rate (TPR) :
Andel av faktiske positive korrekt identifisert av klassifisereren er

- Falsk positiv rate (FPR) :
Andel faktiske negative feil klassifisert som positive



Så, ved terskelen på 0,5:
- Sann positiv rate (sensitivitet): 0,8
- Falsk positiv rate: 0
Tolkningen er at modellen, ved denne terskelen, korrekt identifiserer 80 % av faktiske positive (TPR), men feilaktig klassifiserer 0 % av faktiske negative som positive (FPR).
Følgelig for forskjellige terskler vil vi få ,
Tilfelle 2: Terskel = 0,7
Ekte etiketter | Forutsagte sannsynligheter | Forutsagte etiketter |
|---|---|---|
| 1 | 0,8 | 1 |
| 0 | 0,3 java flyktige søkeord | 0 |
| 1 | 0,6 | 0 |
| 0 | 0,2 | 0 |
| 1 | 0,7 | 0 |
| 1 | 0,9 | 1 |
| 0 | 0,4 | 0 |
| 0 | 0,1 | 0 |
| 1 | 0,75 | 1 |
| 0 | 0,55 | 0 |
Forvirringsmatrise basert på spådommene ovenfor
| Prediksjon = 0 | Prediksjon = 1 |
|---|---|---|
Faktisk = 0 | TP=5 | FN=0 |
Faktisk = 1 | FP=2 | TN=3 |
Tilsvarende,
- Sann positiv rate (TPR) :
Andel av faktiske positive korrekt identifisert av klassifisereren er

- Falsk positiv rate (FPR) :
Andel faktiske negative feil klassifisert som positive



Tilfelle 3: Terskel = 0,4
Ekte etiketter | Forutsagte sannsynligheter | Forutsagte etiketter |
|---|---|---|
| 1 | 0,8 | 1 |
| 0 | 0,3 | 0 |
| 1 | 0,6 | 1 |
| 0 | 0,2 | 0 |
| 1 | 0,7 | 1 |
| 1 | 0,9 | 1 |
| 0 | 0,4 | 0 |
| 0 | 0,1 | 0 |
| 1 | 0,75 | 1 |
| 0 | 0,55 | 1 |
Forvirringsmatrise basert på spådommene ovenfor
| Prediksjon = 0 | Prediksjon = 1 |
|---|---|---|
Faktisk = 0 | TP=4 | FN=1 |
Faktisk = 1 | FP=0 | TN=5 |
Tilsvarende,
- Sann positiv rate (TPR) :
Andel av faktiske positive korrekt identifisert av klassifisereren er
- Falsk positiv rate (FPR) :
Andel faktiske negative feil klassifisert som positive
Tilfelle 4: Terskel = 0,2
Ekte etiketter | Forutsagte sannsynligheter | Forutsagte etiketter |
|---|---|---|
| 1 | 0,8 | 1 |
| 0 | 0,3 | 1 |
| 1 css bryte tekst | 0,6 | 1 |
| 0 | 0,2 | 0 |
| 1 | 0,7 | 1 |
| 1 | 0,9 | 1 |
| 0 | 0,4 | 1 |
| 0 | 0,1 | 0 |
| 1 | 0,75 | 1 |
| 0 | 0,55 | 1 |
Forvirringsmatrise basert på spådommene ovenfor
| Prediksjon = 0 | Prediksjon = 1 |
|---|---|---|
Faktisk = 0 | TP=2 | FN=3 |
Faktisk = 1 | FP=0 | TN=5 |
Tilsvarende,
- Sann positiv rate (TPR) :
Andel av faktiske positive korrekt identifisert av klassifisereren er

- Falsk positiv rate (FPR) :
Andel faktiske negative feil klassifisert som positive

Tilfelle 5: Terskel = 0,85
Ekte etiketter | Forutsagte sannsynligheter | Forutsagte etiketter |
|---|---|---|
| 1 | 0,8 | 0 |
| 0 | 0,3 | 0 |
| 1 | 0,6 | 0 |
| 0 | 0,2 | 0 |
| 1 | 0,7 | 0 |
| 1 | 0,9 | 1 |
| 0 | 0,4 | 0 |
| 0 | 0,1 | 0 |
| 1 | 0,75 | 0 |
| 0 | 0,55 | 0 |
Forvirringsmatrise basert på spådommene ovenfor
| Prediksjon = 0 | Prediksjon = 1 |
|---|---|---|
Faktisk = 0 | TP=5 | FN=0 |
Faktisk = 1 | FP=4 | TN=1 |
Tilsvarende,
- Sann positiv rate (TPR) :
Andel av faktiske positive korrekt identifisert av klassifisereren er
- Falsk positiv rate (FPR) :
Andel faktiske negative feil klassifisert som positive


Basert på resultatet ovenfor vil vi plotte ROC-kurven
Python3
true_positive_rate>=> [>0.4>,>0.8>,>0.8>,>1.0>,>1>]> false_positive_rate>=> [>0>,>0>,>0>,>0.2>,>0.8>]> plt.plot(false_positive_rate, true_positive_rate,>'o-'>, label>=>'ROC'>)> plt.plot([>0>,>1>], [>0>,>1>],>'--'>, color>=>'grey'>, label>=>'Worst case'>)> plt.xlabel(>'False Positive Rate'>)> plt.ylabel(>'True Positive Rate'>)> plt.title(>'ROC Curve'>)> plt.legend()> plt.show()> |
>
>
Produksjon:
Fra grafen antydes det at:
- Den grå stiplede linjen representerer det verste tilfellet, der modellens spådommer, dvs. TPR er FPR, er de samme. Denne diagonale linjen regnes som det verste scenarioet, og indikerer lik sannsynlighet for falske positive og falske negative.
- Ettersom punktene avviker fra den tilfeldige gjettelinjen mot øvre venstre hjørne, forbedres modellens ytelse.
- The Area Under the Curve (AUC) er et kvantitativt mål på modellens diskriminerende evne. En høyere AUC-verdi, nærmere 1,0, indikerer overlegen ytelse. Best mulig AUC-verdi er 1,0, tilsvarende en modell som oppnår 100 % sensitivitet og 100 % spesifisitet.
Alt i alt fungerer Receiver Operating Characteristic (ROC)-kurven som en grafisk representasjon av avveiningen mellom en binær klassifiseringsmodells sanne positive rate (sensitivitet) og falsk positiv rate ved ulike beslutningsterskler. Når kurven grasiøst stiger mot øvre venstre hjørne, betyr det modellens prisverdige evne til å skille mellom positive og negative forekomster over en rekke konfidensgrenser. Denne oppadgående banen indikerer en forbedret ytelse, med høyere følsomhet oppnådd samtidig som falske positiver minimeres. De kommenterte tersklene, betegnet som A, B, C, D og E, gir verdifull innsikt i modellens dynamiske oppførsel på forskjellige konfidensnivåer.
Implementering ved hjelp av to ulike modeller
Installere biblioteker
Python3
import> numpy as np> import> pandas as pd> import> matplotlib.pyplot as plt> from> sklearn.datasets>import> make_classification> from> sklearn.model_selection>import> train_test_split> from> sklearn.linear_model>import> LogisticRegression> from> sklearn.ensemble>import> RandomForestClassifier> from> sklearn.metrics>import> roc_curve, auc> |
>
>
For å trene Tilfeldig skog og Logistisk regresjon modeller og for å presentere deres ROC-kurver med AUC-score, lager algoritmen kunstige binære klassifiseringsdata.
Generere data og dele data
Python3
# Generate synthetic data for demonstration> X, y>=> make_classification(> >n_samples>=>1000>, n_features>=>20>, n_classes>=>2>, random_state>=>42>)> # Split the data into training and testing sets> X_train, X_test, y_train, y_test>=> train_test_split(> >X, y, test_size>=>0.2>, random_state>=>42>)> |
>
>
Ved å bruke et 80-20 delt forhold lager algoritmen kunstige binære klassifiseringsdata med 20 funksjoner, deler den inn i trenings- og testsett, og tildeler et tilfeldig frø for å sikre reproduserbarhet.
understrek med css
Trening av de forskjellige modellene
Python3
# Train two different models> logistic_model>=> LogisticRegression(random_state>=>42>)> logistic_model.fit(X_train, y_train)> random_forest_model>=> RandomForestClassifier(n_estimators>=>100>, random_state>=>42>)> random_forest_model.fit(X_train, y_train)> |
>
>
Ved å bruke et fast tilfeldig frø for å sikre repeterbarhet, initialiserer og trener metoden en logistisk regresjonsmodell på treningssettet. På lignende måte bruker den treningsdataene og det samme tilfeldige frøet til å initialisere og trene en Random Forest-modell med 100 trær.
Spådommer
Python3
# Generate predictions> y_pred_logistic>=> logistic_model.predict_proba(X_test)[:,>1>]> y_pred_rf>=> random_forest_model.predict_proba(X_test)[:,>1>]> |
>
>
Ved hjelp av testdata og en trent Logistisk regresjon modell, forutsier koden den positive klassens sannsynlighet. På lignende måte, ved å bruke testdataene, bruker den den trente Random Forest-modellen for å produsere projiserte sannsynligheter for den positive klassen.
Opprette en dataramme
Python3
# Create a DataFrame> test_df>=> pd.DataFrame(> >{>'True'>: y_test,>'Logistic'>: y_pred_logistic,>'RandomForest'>: y_pred_rf})> |
>
>
Ved å bruke testdataene oppretter koden en DataFrame kalt test_df med kolonner merket True, Logistic og RandomForest, og legger til sanne etiketter og predikerte sannsynligheter fra Random Forest og Logistic Regression-modellene.
Tegn ROC-kurven for modellene
Python3
# Plot ROC curve for each model> plt.figure(figsize>=>(>7>,>5>))> for> model>in> [>'Logistic'>,>'RandomForest'>]:> >fpr, tpr, _>=> roc_curve(test_df[>'True'>], test_df[model])> >roc_auc>=> auc(fpr, tpr)> >plt.plot(fpr, tpr, label>=>f>'{model} (AUC = {roc_auc:.2f})'>)> # Plot random guess line> plt.plot([>0>,>1>], [>0>,>1>],>'r--'>, label>=>'Random Guess'>)> # Set labels and title> plt.xlabel(>'False Positive Rate'>)> plt.ylabel(>'True Positive Rate'>)> plt.title(>'ROC Curves for Two Models'>)> plt.legend()> plt.show()> |
>
>
Produksjon:

Koden genererer et plott med 8 x 6 tommers figurer. Den beregner AUC- og ROC-kurven for hver modell (Random Forest and Logistic Regression), og plotter deretter ROC-kurven. De ROC-kurve for tilfeldig gjetting er også representert med en rød stiplet linje, og etiketter, en tittel og en forklaring er satt for visualisering.
Hvordan bruke ROC-AUC for en multi-klasse modell?
For en multi-klasse-innstilling kan vi ganske enkelt bruke en vs all-metodikk, og du vil ha en ROC-kurve for hver klasse. La oss si at du har fire klassene A, B, C og D, så vil det være ROC-kurver og tilsvarende AUC-verdier for alle de fire klassene, det vil si at når A vil være én klasse og B, C og D kombinert vil de andre klassen være , på samme måte er B én klasse og A, C og D kombinert som andre klasse osv.
De generelle trinnene for å bruke AUC-ROC i sammenheng med en flerklasseklassifiseringsmodell er:
En-mot-alle-metodikk:
- For hver klasse i flerklasseproblemet ditt, behandle det som den positive klassen mens du kombinerer alle andre klasser i den negative klassen.
- Tren den binære klassifisereren for hver klasse mot resten av klassene.
Beregn AUC-ROC for hver klasse:
- Her plotter vi ROC-kurven for den gitte klassen mot resten.
- Plott ROC-kurvene for hver klasse på samme graf. Hver kurve representerer diskrimineringsytelsen til modellen for en spesifikk klasse.
- Undersøk AUC-poengsummene for hver klasse. En høyere AUC-score indikerer bedre diskriminering for den spesielle klassen.
Implementering av AUC-ROC i Multiclass Classification
Importerer biblioteker
Python3
import> numpy as np> import> matplotlib.pyplot as plt> from> sklearn.datasets>import> make_classification> from> sklearn.model_selection>import> train_test_split> from> sklearn.preprocessing>import> label_binarize> from> sklearn.multiclass>import> OneVsRestClassifier> from> sklearn.linear_model>import> LogisticRegression> from> sklearn.ensemble>import> RandomForestClassifier> from> sklearn.metrics>import> roc_curve, auc> from> itertools>import> cycle> |
>
>
Programmet lager kunstige multiklassedata, deler det inn i trenings- og testsett, og bruker deretter One-vs-Restclassifier teknikk for å trene klassifisere for både tilfeldig skog og logistisk regresjon. Til slutt plotter den de to modellenes flerklasse ROC-kurver for å demonstrere hvor godt de skiller mellom ulike klasser.
Generering av data og splitting
Python3
# Generate synthetic multiclass data> X, y>=> make_classification(> >n_samples>=>1000>, n_features>=>20>, n_classes>=>3>, n_informative>=>10>, random_state>=>42>)> # Binarize the labels> y_bin>=> label_binarize(y, classes>=>np.unique(y))> # Split the data into training and testing sets> X_train, X_test, y_train, y_test>=> train_test_split(> >X, y_bin, test_size>=>0.2>, random_state>=>42>)> |
>
>
Tre klasser og tjue funksjoner utgjør de syntetiske multiklassedataene produsert av koden. Etter etikettbinarisering deles dataene inn i trenings- og testsett i forholdet 80-20.
Treningsmodeller
Python3
# Train two different multiclass models> logistic_model>=> OneVsRestClassifier(LogisticRegression(random_state>=>42>))> logistic_model.fit(X_train, y_train)> rf_model>=> OneVsRestClassifier(> >RandomForestClassifier(n_estimators>=>100>, random_state>=>42>))> rf_model.fit(X_train, y_train)> |
>
>
Programmet trener to multiklassemodeller: en Random Forest-modell med 100 estimatorer og en logistisk regresjonsmodell med One-vs-Rest-tilnærming . Med treningssettet med data er begge modellene utstyrt.
Plotte AUC-ROC-kurven
Python3
# Compute ROC curve and ROC area for each class> fpr>=> dict>()> tpr>=> dict>()> roc_auc>=> dict>()> models>=> [logistic_model, rf_model]> plt.figure(figsize>=>(>6>,>5>))> colors>=> cycle([>'aqua'>,>'darkorange'>])> for> model, color>in> zip>(models, colors):> >for> i>in> range>(model.classes_.shape[>0>]):> >fpr[i], tpr[i], _>=> roc_curve(> >y_test[:, i], model.predict_proba(X_test)[:, i])> >roc_auc[i]>=> auc(fpr[i], tpr[i])> >plt.plot(fpr[i], tpr[i], color>=>color, lw>=>2>,> >label>=>f>'{model.__class__.__name__} - Class {i} (AUC = {roc_auc[i]:.2f})'>)> # Plot random guess line> plt.plot([>0>,>1>], [>0>,>1>],>'k--'>, lw>=>2>, label>=>'Random Guess'>)> # Set labels and title> plt.xlabel(>'False Positive Rate'>)> plt.ylabel(>'True Positive Rate'>)> plt.title(>'Multiclass ROC Curve with Logistic Regression and Random Forest'>)> plt.legend(loc>=>'lower right'>)> plt.show()> |
>
>
Produksjon:

Random Forest og Logistic Regression-modellenes ROC-kurver og AUC-score beregnes av koden for hver klasse. Multiklasse ROC-kurvene plottes deretter, og viser diskrimineringsytelsen til hver klasse og har en linje som representerer tilfeldig gjetting. Det resulterende plottet gir en grafisk evaluering av modellenes klassifiseringsytelse.
Konklusjon
I maskinlæring vurderes ytelsen til binære klassifiseringsmodeller ved å bruke en avgjørende beregning kalt Area Under the Receiver Operating Characteristic (AUC-ROC). På tvers av ulike beslutningsterskler viser den hvordan sensitivitet og spesifisitet avveies. Større diskriminering mellom positive og negative tilfeller vises vanligvis av en modell med høyere AUC-score. Mens 0,5 angir tilfeldighet, representerer 1 feilfri ytelse. Modelloptimalisering og valg blir hjulpet av den nyttige informasjonen som AUC-ROC-kurven gir om en modells kapasitet til å skille mellom klasser. Når du arbeider med ubalanserte datasett eller applikasjoner der falske positive og falske negative har forskjellige kostnader, er det spesielt nyttig som et omfattende tiltak.
Vanlige spørsmål for AUC ROC Curve i maskinlæring
1. Hva er AUC-ROC-kurven?
For ulike klassifiseringsterskler er avveiningen mellom sann positiv rate (sensitivitet) og falsk positiv rate (spesifisitet) grafisk representert av AUC-ROC-kurven.
2. Hvordan ser en perfekt AUC-ROC-kurve ut?
Et område på 1 på en ideell AUC-ROC-kurve vil bety at modellen oppnår optimal sensitivitet og spesifisitet ved alle terskler.
3. Hva betyr en AUC-verdi på 0,5?
AUC på 0,5 indikerer at modellens ytelse er sammenlignbar med tilfeldig tilfeldighet. Det tyder på mangel på diskrimineringsevne.
4. Kan AUC-ROC brukes til flerklasseklassifisering?
AUC-ROC brukes ofte på problemer som involverer binær klassifisering. Variasjoner som makro-gjennomsnittlig eller mikro-gjennomsnittlig AUC kan tas i betraktning for multiklasseklassifisering.
5. Hvordan er AUC-ROC-kurven nyttig i modellevaluering?
En modells evne til å skille mellom klasser er omfattende oppsummert av AUC-ROC-kurven. Når du arbeider med ubalanserte datasett, er det spesielt nyttig.