IDENTITY-nøkkelordet er en egenskap i SQL Server. Når en tabellkolonne er definert med en identitetsegenskap, vil verdien være automatisk generert inkrementell verdi . Denne verdien opprettes automatisk av serveren. Derfor kan vi ikke manuelt legge inn en verdi i en identitetskolonne som bruker. Derfor, hvis vi merker en kolonne som identitet, vil SQL Server fylle den på en automatisk inkrementeringsmåte.
Syntaks
Følgende er syntaksen for å illustrere bruken av IDENTITY-egenskapen i SQL Server:
IDENTITY[(seed, increment)]
Syntaksparametrene ovenfor er forklart nedenfor:
La oss forstå dette konseptet gjennom et enkelt eksempel.
Anta at vi har en ' Student ' bord, og vi vil ha Student ID genereres automatisk. Vi har en begynnende student-ID av 10 og ønsker å øke den med 1 for hver ny ID. I dette scenariet må følgende verdier defineres.
Frø: 10
Økning: 1
CREATE TABLE Student ( StudentID INT IDENTITY(10, 1) PRIMARY KEY NOT NULL, )
MERK: Bare én identifikasjonskolonne er tillatt per tabell i SQL Server.
Eksempel på SQL Server IDENTITY
La oss forstå hvordan vi kan bruke identitetsegenskapen i tabellen. Identitetsegenskapen i en kolonne kan angis enten når den nye tabellen opprettes eller etter at den er opprettet. Her skal vi se begge tilfellene med eksempler.
IDENTITY-eiendom med ny tabell
Følgende setning vil opprette en ny tabell med identitetsegenskapen i den angitte databasen:
CREATE TABLE person ( PersonID INT IDENTITY(10,1) PRIMARY KEY NOT NULL, Fullname VARCHAR(100) NOT NULL, Occupation VARCHAR(50), Gender VARCHAR(10) NOT NULL );
Deretter vil vi sette inn en ny rad i denne tabellen med en PRODUKSJON klausul for å se den autogenererte person-IDen:
INSERT INTO person(Fullname, Occupation, Gender) OUTPUT inserted.PersonID VALUES('Sara Jackson', 'HR', 'Female');
Utførelse av denne spørringen vil vise utdataene nedenfor:
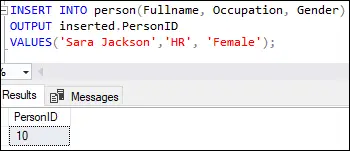
Denne utgangen viser at den første raden er satt inn med verdien ti i PersonID kolonne som spesifisert i tabelldefinisjonsidentitetskolonnen.
La oss sette inn en annen rad i person bord som Nedenfor:
INSERT INTO person(Fullname, Occupation, Gender) OUTPUT inserted.* VALUES('Mark Boucher', 'Cricketer', 'Male'), ('Josh Phillip', 'Writer', 'Male');
Denne spørringen vil returnere følgende utdata:

Denne utgangen viser at den andre raden er satt inn med verdien 11 og den tredje raden med verdien 12 i PersonID-kolonnen.
IDENTITY-egenskap med eksisterende tabell
Vi vil forklare dette konseptet ved først å slette tabellen ovenfor og lage dem uten identitetsegenskap. Utfør setningen nedenfor for å slippe tabellen:
DROP TABLE person;
Deretter lager vi en tabell ved å bruke spørringen nedenfor:
CREATE TABLE person ( Fullname VARCHAR(100) NOT NULL, Occupation VARCHAR(50), Gender VARCHAR(10) NOT NULL );
Hvis vi ønsker å legge til en ny kolonne med identitetsegenskapen i en eksisterende tabell, må vi bruke ALTER-kommandoen. Spørringen nedenfor vil legge til PersonID som en identitetskolonne i persontabellen:
ALTER TABLE person ADD PersonID INT IDENTITY(10,1) PRIMARY KEY NOT NULL;
Legger eksplisitt til verdi i identitetskolonnen
Hvis vi legger til en ny rad i tabellen ovenfor ved å spesifisere identitetskolonnen eksplisitt, vil SQL Server gi en feil. Se spørringen nedenfor:
INSERT INTO person(Fullname, Occupation, Gender, PersonID) VALUES('Mary Smith', 'Business Analyst', 'Female', 13);
Utførelse av denne spørringen vil gjennom følgende feil:

For å sette inn identitetskolonneverdien eksplisitt, må vi først sette IDENTITY_INSERT-verdien PÅ. Utfør deretter insert-operasjonen for å legge til en ny rad i tabellen og sett deretter IDENTITY_INSERT-verdien AV. Se kodeskriptet nedenfor:
SET IDENTITY_INSERT person ON /*INSERT VALUE*/ INSERT INTO person(Fullname, Occupation, Gender, PersonID) VALUES('Mary Smith', 'Business Analyst', 'Female', 14); SET IDENTITY_INSERT person OFF SELECT * FROM person;
IDENTITY_INSERT PÅ lar brukere legge data inn i identitetskolonner, mens IDENTITY_INSERT AV hindrer dem i å tilføre verdi til denne kolonnen.
Utførelse av kodeskriptet vil vise utdataene nedenfor der vi kan se at PersonID med verdi 14 er satt inn.

IDENTITET-funksjon
SQL Server gir noen identitetsfunksjoner for å arbeide med IDENTITY-kolonnene i en tabell. Disse identitetsfunksjonene er listet opp nedenfor:
- @@IDENTITY-funksjon
- SCOPE_IDENTITY() funksjon
- IDENT_CURRENT funksjon
- IDENTITET-funksjon
La oss ta en titt på IDENTITET-funksjonene med noen eksempler.
@@IDENTITY-funksjon
@@IDENTITY er en systemdefinert funksjon som viser den siste identitetsverdien (maksimal brukt identitetsverdi) opprettet i en tabell for IDENTITY-kolonnen i samme økt. Denne funksjonskolonnen returnerer identitetsverdien generert av setningen etter å ha satt inn en ny oppføring i en tabell. Den returnerer en NULL verdi når vi utfører en spørring som ikke skaper IDENTITY-verdier. Det fungerer alltid innenfor rammen av gjeldende økt. Den kan ikke brukes eksternt.
Eksempel
Anta at vi har den gjeldende maksimale identitetsverdien i persontabellen er 13. Nå vil vi legge til én post i samme økt som øker identitetsverdien med én. Deretter vil vi bruke @@IDENTITY-funksjonen for å få den siste identitetsverdien opprettet i samme økt.
Her er hele kodeskriptet:
SELECT MAX(PersonID) AS maxidentity FROM person; INSERT INTO person(Fullname, Occupation, Gender) VALUES('Brian Lara', 'Cricket', 'Male'); SELECT @@IDENTITY;
Utførelse av skriptet vil returnere følgende utdata der vi kan se maksimalt brukt identitetsverdi er 14.

SCOPE_IDENTITY() funksjon
SCOPE_IDENTITY() er en systemdefinert funksjon til vise den nyeste identitetsverdien i en tabell under gjeldende omfang. Dette omfanget kan være en modul, trigger, funksjon eller en lagret prosedyre. Den ligner på @@IDENTITY()-funksjonen, bortsett fra at denne funksjonen bare har et begrenset omfang. SCOPE_IDENTITY-funksjonen returnerer NULL hvis vi utfører den før innsettingsoperasjonen som genererer en verdi i samme omfang.
Eksempel
Koden nedenfor bruker både @@IDENTITY og SCOPE_IDENTITY() funksjonen i samme økt. Dette eksemplet vil først vise den siste identitetsverdien, og deretter sette inn én rad i tabellen. Deretter utfører den begge identitetsfunksjonene.
SELECT MAX(PersonID) AS maxid FROM person; INSERT INTO person(Fullname, Occupation, Gender) VALUES('Jennifer Winset', 'Actoress', 'Female'); SELECT SCOPE_IDENTITY(); SELECT @@IDENTITY;
Utførelse av koden vil vise samme verdi i gjeldende økt og lignende omfang. Se utdatabildet nedenfor:

Nå skal vi se hvordan begge funksjonene er forskjellige med et eksempel. Først vil vi lage to navngitte tabeller ansattdata og avdeling ved å bruke utsagnet nedenfor:
CREATE TABLE employee_data ( emp_id INT IDENTITY(1, 1) PRIMARY KEY NOT NULL, fullname VARCHAR(20) NULL ) GO CREATE TABLE department ( department_id INT IDENTITY(100, 5) PRIMARY KEY, department_name VARCHAR(20) NULL );
Deretter oppretter vi en INSERT-utløser på tabellen medarbeiderdata. Denne utløseren påkalles for å sette inn en rad i avdelingstabellen hver gang vi setter inn en rad i tabellen medarbeiderdata.
Spørringen nedenfor oppretter en trigger for å sette inn en standardverdi 'DEN' i avdelingstabellen på hver innsettingsspørring i ansattdatatabellen:
skuespiller zeenat aman
CREATE TRIGGER Insert_Department ON employee_data FOR INSERT AS BEGIN INSERT INTO department VALUES ('IT') END;
Etter å ha opprettet en utløser, skal vi sette inn én post i ansattdatatabellen og se utdataene fra både @@IDENTITY og SCOPE_IDENTITY() funksjoner.
INSERT INTO employee_data VALUES ('John Mathew');
Utførelse av spørringen vil legge til én rad i tabellen medarbeiderdata og generere en identitetsverdi i samme økt. Når insert-spørringen er utført i tabellen medarbeiderdata, kaller den automatisk en utløser for å legge til én rad i avdelingstabellen. Identitetsfrøverdien er 1 for ansattdataene og 100 for avdelingstabellen.
Til slutt utfører vi setningene nedenfor som viser utdata 100 for SELECT @@IDENTITY-funksjonen og 1 for SCOPE_IDENTITY-funksjonen fordi de bare returnerer identitetsverdi i samme omfang.
SELECT MAX(emp_id) FROM employee_data SELECT MAX(department_id) FROM department SELECT @@IDENTITY SELECT SCOPE_IDENTITY()
Her er resultatet:

IDENT_CURRENT() funksjon
IDENT_CURRENT er en systemdefinert funksjon til vise den nyeste IDENTITY-verdien generert for en gitt tabell under enhver tilkobling. Denne funksjonen tar ikke hensyn til omfanget av SQL-spørringen som skaper identitetsverdien. Denne funksjonen krever tabellnavnet som vi ønsker å få identitetsverdien for.
Eksempel
Vi kan forstå det ved først å åpne de to koblingsvinduene. Vi vil sette inn én post i det første vinduet som genererer identitetsverdien 15 i persontabellen. Deretter kan vi bekrefte denne identitetsverdien i et annet tilkoblingsvindu der vi kan se den samme utgangen. Her er hele koden:
1st Connection Window INSERT INTO person(Fullname, Occupation, Gender) VALUES('John Doe', 'Engineer', 'Male'); GO SELECT MAX(PersonID) AS maxid FROM person; 2nd Connection Window SELECT MAX(PersonID) AS maxid FROM person; GO SELECT IDENT_CURRENT('person') AS identity_value;
Utførelse av kodene ovenfor i to forskjellige vinduer vil vise samme identitetsverdi.

IDENTITY() funksjon
IDENTITY()-funksjonen er en systemdefinert funksjon brukes til å sette inn en identitetskolonne i en ny tabell . Denne funksjonen er forskjellig fra IDENTITY-egenskapen som vi bruker med CREATE TABLE- og ALTER TABLE-setningene. Vi kan bare bruke denne funksjonen i en SELECT INTO-setning, som brukes under overføring av data fra en tabell til en annen.
Følgende syntaks illustrerer bruken av denne funksjonen i SQL Server:
IDENTITY (data_type , seed , increment) AS column_name
Hvis en kildetabell har en IDENTITY-kolonne, arver tabellen som er dannet med en SELECT INTO-kommando den som standard. For eksempel , har vi tidligere opprettet en tabellperson med en identitetskolonne. Anta at vi lager en ny tabell som arver persontabellen ved å bruke SELECT INTO-setningene med IDENTITY()-funksjonen. I så fall vil vi få en feil fordi kildetabellen allerede har en identitetskolonne. Se spørringen nedenfor:
SELECT IDENTITY(INT, 100, 2) AS NEW_ID, PersonID, Fullname, Occupation, Gender INTO person_info FROM person;
Utførelse av setningen ovenfor vil returnere følgende feilmelding:

La oss lage en ny tabell uten identitetsegenskap ved å bruke setningen nedenfor:
CREATE TABLE student_data ( roll_no INT PRIMARY KEY NOT NULL, fullname VARCHAR(20) NULL )
Kopier deretter denne tabellen ved å bruke SELECT INTO-setningen inkludert IDENTITY-funksjonen som følger:
SELECT IDENTITY(INT, 100, 1) AS student_id, roll_no, fullname INTO temp_data FROM student_data;
Når setningen er utført, kan vi bekrefte den ved å bruke sp_hjelp kommando som viser tabellegenskaper.

Du kan se IDENTITET-kolonnen i FRISTENDE egenskaper i henhold til de angitte forholdene.
Hvis vi bruker denne funksjonen med SELECT-setningen, vil SQL Server gjennom følgende feilmelding:
Melding 177, nivå 15, tilstand 1, linje 2 IDENTITY-funksjonen kan bare brukes når SELECT-setningen har en INTO-klausul.
Gjenbruk av IDENTITY-verdier
Vi kan ikke gjenbruke identitetsverdiene i SQL Server-tabellen. Når vi sletter en rad fra identitetskolonnetabellen, vil det bli opprettet et gap i identitetskolonnen. SQL Server vil også skape et gap når vi setter inn en ny rad i identitetskolonnen, og setningen mislyktes eller rulles tilbake. Gapet indikerer at identitetsverdiene går tapt og ikke kan genereres igjen i IDENTITET-kolonnen.
Tenk på eksemplet nedenfor for å forstå det praktisk. Vi har allerede en persontabell som inneholder følgende data:

Deretter vil vi lage ytterligere to tabeller med navn 'posisjon' , og ' person_posisjon ' ved å bruke følgende utsagn:
CREATE TABLE POSITION ( PositionID INT IDENTITY (1, 1) PRIMARY KEY, Position_name VARCHAR (255) NOT NULL ); CREATE TABLE person_position ( PersonID INT, PositionID INT, PRIMARY KEY (PersonID, PositionID), FOREIGN KEY (PersonID) REFERENCES person (PersonID), FOREIGN KEY (PositionID) REFERENCES POSITION (PositionID) );
Deretter prøver vi å sette inn en ny post i persontabellen og tilordne dem en posisjon ved å legge til en ny rad i person_position-tabellen. Vi vil gjøre dette ved å bruke transaksjonserklæringen som nedenfor:
BEGIN TRANSACTION BEGIN TRY -- insert a new row into the person table INSERT INTO person (Fullname, Occupation, Gender) VALUES('Joan Smith', 'Manager', 'Male'); -- assign a position to a new person INSERT INTO person_position (PersonID, PositionID) VALUES(@@IDENTITY, 10); END TRY BEGIN CATCH IF @@TRANCOUNT > 0 ROLLBACK TRANSACTION; END CATCH IF @@TRANCOUNT > 0 COMMIT TRANSACTION;
Transaksjonskodeskriptet ovenfor utfører den første insert-setningen vellykket. Men den andre uttalelsen mislyktes siden det ikke var noen posisjon med id ti i posisjonstabellen. Derfor ble hele transaksjonen rullet tilbake.
Siden vi har maksimal identitetsverdi i PersonID-kolonnen er 16, forbrukte den første insert-setningen identitetsverdien 17, og deretter ble transaksjonen rullet tilbake. Derfor, hvis vi setter inn neste rad i Person-tabellen, vil neste identitetsverdi være 18. Utfør setningen nedenfor:
INSERT INTO person(Fullname, Occupation, Gender) VALUES('Peter Drucker',' Writer', 'Female');
Etter å ha sjekket persontabellen på nytt, ser vi at den nylig tilføyde posten inneholder identitetsverdi 18.

To IDENTITY-kolonner i én enkelt tabell
Teknisk sett er det ikke mulig å lage to identitetskolonner i en enkelt tabell. Hvis vi gjør dette, gir SQL Server en feil. Se følgende spørring:
CREATE TABLE TwoIdentityTable ( ID1 INT IDENTITY (10, 1) NOT NULL, ID2 INT IDENTITY (100, 1) NOT NULL )
Når vi kjører denne koden, vil vi se følgende feil:

Imidlertid kan vi opprette to identitetskolonner i en enkelt tabell ved å bruke den beregnede kolonnen. Følgende spørring oppretter en tabell med en beregnet kolonne som bruker den opprinnelige identitetskolonnen og reduserer den med 1.
CREATE TABLE TwoIdentityTable ( ID1 INT IDENTITY (10, 1) NOT NULL, SecondID AS 10000-ID1, Descriptions VARCHAR(60) )
Deretter vil vi legge til noen data i denne tabellen ved å bruke kommandoen nedenfor:
INSERT INTO TwoIdentityTable (Descriptions) VALUES ('Javatpoint provides best educational tutorials'), ('www.javatpoint.com')
Til slutt sjekker vi tabelldataene ved å bruke SELECT-setningen. Den returnerer følgende utgang:

Vi kan se på bildet hvordan SecondID-kolonnen fungerer som en andre identitetskolonne, som reduseres med ti fra startverdien på 9990.
SQL Servers IDENTITY-kolonne feiloppfatninger
DBA-brukeren har mange misoppfatninger angående SQL Server-identitetskolonner. Følgende er listen over de vanligste misoppfatningene angående identitetskolonner som vil bli sett:
IDENTITY-kolonnen er UNIK: I følge SQL Servers offisielle dokumentasjon kan ikke identitetsegenskapen garantere at kolonneverdien er unik. Vi må bruke en PRIMÆRKØKKEL, UNIK begrensning eller UNIK indeks for å fremtvinge kolonneunikhet.
IDENTITY-kolonnen genererer fortløpende tall: Offisiell dokumentasjon sier tydelig at de tilordnede verdiene i identitetskolonnen kan gå tapt ved en databasefeil eller omstart av serveren. Det kan forårsake hull i identitetsverdien under innsetting. Gapet kan også opprettes når vi sletter verdien fra tabellen, eller insert-setningen rulles tilbake. Verdiene som genererer gap kan ikke brukes videre.
IDENTITY-kolonnen kan ikke automatisk generere eksisterende verdier: Det er ikke mulig for identitetskolonnen å automatisk generere eksisterende verdier før identitetsegenskapen er endret ved å bruke kommandoen DBCC CHECKIDENT. Den lar oss justere frøverdien (startverdien for raden) til identitetsegenskapen. Etter å ha utført denne kommandoen, vil ikke SQL Server sjekke de nyopprettede verdiene som allerede finnes i tabellen eller ikke.
IDENTITY-kolonnen som PRIMÆR NØKKEL er nok til å identifisere raden: Hvis en primærnøkkel inneholder identitetskolonnen i tabellen uten noen andre unike begrensninger, kan kolonnen lagre dupliserte verdier og forhindre kolonneunikk. Som vi vet kan ikke primærnøkkelen lagre duplikatverdier, men identitetskolonnen kan lagre duplikater; det anbefales å ikke bruke primærnøkkelen og identitetsegenskapen i samme kolonne.
Bruk av feil verktøy for å få tilbake identitetsverdier etter en innsetting: Det er også en vanlig misforståelse om uvitende om forskjellene mellom funksjonene @@IDENTITY, SCOPE_IDENTITY(), IDENT_CURRENT og IDENTITY() å få identitetsverdien direkte satt inn fra setningen vi nettopp har utført.
Forskjellen mellom SEKVENS og IDENTITET
Vi bruker både SEKVENS og IDENTITET for å generere automatiske tall. Imidlertid har den noen forskjeller, og hovedforskjellen er at identitet er tabellavhengig, mens sekvens ikke er det. La oss oppsummere forskjellene deres i tabellformen:
| IDENTITET | SEKVENS |
|---|---|
| Identitetsegenskapen brukes for en bestemt tabell og kan ikke deles med andre tabeller. | En DBA definerer sekvensobjektet som kan deles mellom flere tabeller fordi det er uavhengig av en tabell. |
| Denne egenskapen genererer automatisk verdier hver gang insert-setningen kjøres på tabellen. | Den bruker NEXT VALUE FOR-leddet for å generere neste verdi for et sekvensobjekt. |
| SQL Server tilbakestiller ikke kolonneverdien til identitetsegenskapen til den opprinnelige verdien. | SQL Server kan tilbakestille verdien for sekvensobjektet. |
| Vi kan ikke angi maksimumsverdien for identitetseiendom. | Vi kan sette maksimumsverdien for sekvensobjektet. |
| Den er introdusert i SQL Server 2000. | Den er introdusert i SQL Server 2012. |
| Denne egenskapen kan ikke generere identitetsverdi i synkende rekkefølge. | Den kan generere verdier i synkende rekkefølge. |
Konklusjon
Denne artikkelen vil gi en fullstendig oversikt over IDENTITY-egenskapen i SQL Server. Her har vi lært hvordan og når identitetsegenskap brukes, dens forskjellige funksjoner, misoppfatninger og hvordan den er forskjellig fra sekvensen.