Nevrale nettverk er beregningsmodeller som etterligner de komplekse funksjonene til den menneskelige hjernen. De nevrale nettverkene består av sammenkoblede noder eller nevroner som behandler og lærer av data, noe som muliggjør oppgaver som mønstergjenkjenning og beslutningstaking innen maskinlæring. Artikkelen utforsker mer om nevrale nettverk, deres virkemåte, arkitektur og mer.
Innholdsfortegnelse
- Evolusjon av nevrale nettverk
- Hva er nevrale nettverk?
- Hvordan fungerer nevrale nettverk?
- Læring av et nevralt nettverk
- Typer nevrale nettverk
- Enkel implementering av et nevralt nettverk
Evolusjon av nevrale nettverk
Siden 1940-tallet har det vært en rekke bemerkelsesverdige fremskritt innen nevrale nettverk:
- 1940-1950-tallet: Tidlige konsepter
Nevrale nettverk begynte med introduksjonen av den første matematiske modellen av kunstige nevroner av McCulloch og Pitts. Men beregningsmessige begrensninger gjorde fremgang vanskelig.
- 1960-1970-tallet: Perceptrons
Denne epoken er definert av Rosenblatts arbeid med perseptroner. Perceptrons er enkeltlagsnettverk hvis anvendelighet var begrenset til problemer som kunne løses lineært separat.
- 1980-tallet: Backpropagation and Connectionism
Flerlags nettverk trening ble muliggjort av Rumelhart, Hinton og Williams oppfinnelse av tilbakeformeringsmetoden. Med sin vekt på læring gjennom sammenkoblede noder, fikk konneksjonisme appell.
- 1990-tallet: Boom and Winter
Med applikasjoner innen bildeidentifikasjon, finans og andre felt, så nevrale nettverk en boom. Nevrale nettverksforskning opplevde imidlertid en vinter på grunn av ublu beregningskostnader og oppblåste forventninger.
- 2000-tallet: Gjenoppblomstring og dyp læring
Større datasett, innovative strukturer og forbedret prosesseringsevne ansporet til et comeback. Dyp læring har vist utrolig effektivitet i en rekke disipliner ved å bruke mange lag.
- 2010-årene: Deep Learning Dominance
Konvolusjonelle nevrale nettverk (CNN) og tilbakevendende nevrale nettverk (RNN), to dyplæringsarkitekturer, dominerte maskinlæring. Kraften deres ble demonstrert av innovasjoner innen spill, bildegjenkjenning og naturlig språkbehandling.
Hva er nevrale nettverk?
Nevrale nettverk trekke ut identifiserende funksjoner fra data, mangler forhåndsprogrammert forståelse. Nettverkskomponenter inkluderer nevroner, forbindelser, vekter, skjevheter, forplantningsfunksjoner og en læringsregel. Nevroner mottar innganger, styrt av terskler og aktiveringsfunksjoner. Forbindelser involverer vekter og skjevheter som regulerer informasjonsoverføring. Læring, justering av vekter og skjevheter skjer i tre stadier: inputberegning, produksjonsgenerering og iterativ foredling som forbedrer nettverkets ferdigheter i forskjellige oppgaver.
Disse inkluderer:
- Det nevrale nettverket simuleres av et nytt miljø.
- Deretter endres de frie parameterne til det nevrale nettverket som et resultat av denne simuleringen.
- Det nevrale nettverket reagerer deretter på en ny måte på miljøet på grunn av endringene i dets frie parametere.
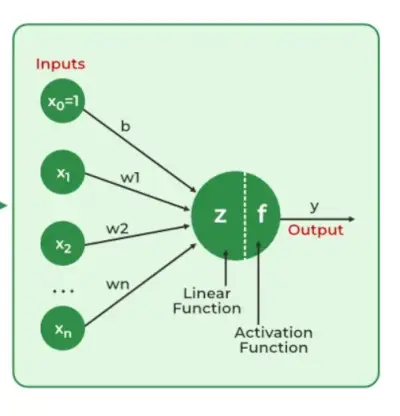
Viktigheten av nevrale nettverk
Evnen til nevrale nettverk til å identifisere mønstre, løse intrikate gåter og tilpasse seg skiftende omgivelser er avgjørende. Deres evne til å lære av data har vidtrekkende effekter, alt fra revolusjonerende teknologi som naturlig språkbehandling og selvkjørende biler for å automatisere beslutningsprosesser og øke effektiviteten i en rekke bransjer. Utviklingen av kunstig intelligens er i stor grad avhengig av nevrale nettverk, som også driver innovasjon og påvirker teknologiens retning.
Hvordan fungerer nevrale nettverk?
La oss forstå med et eksempel på hvordan et nevralt nettverk fungerer:
Vurder et nevralt nettverk for e-postklassifisering. Inndatalaget tar funksjoner som e-postinnhold, avsenderinformasjon og emne. Disse inngangene, multiplisert med justerte vekter, går gjennom skjulte lag. Gjennom opplæring lærer nettverket å gjenkjenne mønstre som indikerer om en e-post er spam eller ikke. Utdatalaget, med en binær aktiveringsfunksjon, forutsier om e-posten er spam (1) eller ikke (0). Ettersom nettverket iterativt avgrenser vektene sine gjennom backpropagation, blir det dyktig til å skille mellom spam og legitime e-poster, og viser frem det praktiske ved nevrale nettverk i virkelige applikasjoner som e-postfiltrering.
Arbeid av et nevralt nettverk
Nevrale nettverk er komplekse systemer som etterligner noen funksjoner i den menneskelige hjernens funksjon. Den er sammensatt av et inputlag, ett eller flere skjulte lag og et utgangslag som består av lag med kunstige nevroner som er koblet sammen. De to stadiene i den grunnleggende prosessen kalles backpropagation og forplantning fremover .
chmod 755
Forplantning fremover
- Inndatalag: Hver funksjon i inputlaget er representert av en node på nettverket, som mottar inngangsdata.
- Vekter og koblinger: Vekten av hver nevronal forbindelse indikerer hvor sterk forbindelsen er. Gjennom treningen endres disse vektene.
- Skjulte lag: Hvert skjult lagneuron behandler innganger ved å multiplisere dem med vekter, legge dem sammen og deretter sende dem gjennom en aktiveringsfunksjon. Ved å gjøre dette introduseres ikke-linearitet, noe som gjør det mulig for nettverket å gjenkjenne intrikate mønstre.
- Produksjon: Det endelige resultatet produseres ved å gjenta prosessen til utgangslaget er nådd.
Tilbakepropagering
- Tapsberegning: Nettverkets utgang blir evaluert mot de reelle målverdiene, og en tapsfunksjon brukes til å beregne differansen. For et regresjonsproblem kan Mean Squared Feil (MSE) brukes ofte som kostnadsfunksjon.
Tapsfunksjon:
- Gradientnedstigning: Gradientnedstigning brukes deretter av nettverket for å redusere tapet. For å redusere unøyaktigheten endres vektene basert på derivatet av tapet med hensyn til hver vekt.
- Justering av vekter: Vektene justeres ved hver tilkobling ved å bruke denne iterative prosessen, eller tilbakeforplantning , bakover over nettverket.
- Opplæring: Under trening med forskjellige dataprøver, gjøres hele prosessen med foroverforplantning, tapsberegning og tilbakepropagering iterativt, noe som gjør det mulig for nettverket å tilpasse og lære mønstre fra dataene.
- Aktiveringsfunksjoner: Modellens ikke-linearitet introduseres av aktiveringsfunksjoner som rettet lineær enhet (ReLU) timer sigmoid . Deres beslutning om hvorvidt de skal avfyre en nevron er basert på hele vektet input.

Læring av et nevralt nettverk
1. Læring med veiledet læring
I veiledet læring , blir det nevrale nettverket guidet av en lærer som har tilgang til begge input-output-parene. Nettverket lager utganger basert på input uten å ta hensyn til omgivelsene. Ved å sammenligne disse utgangene med de lærerkjente ønskede utgangene, genereres et feilsignal. For å redusere feil endres nettverkets parametere iterativt og stopper når ytelsen er på et akseptabelt nivå.
2. Læring med uovervåket læring
Ekvivalente utdatavariabler er fraværende i uovervåket læring . Hovedmålet er å forstå innkommende datas (X) underliggende struktur. Ingen instruktør er tilstede for å gi råd. Modellering av datamønstre og relasjoner er det tiltenkte resultatet i stedet. Ord som regresjon og klassifisering er relatert til veiledet læring, mens uovervåket læring er assosiert med klynging og assosiasjon.
3. Læring med forsterkende læring
Gjennom samhandling med omgivelsene og tilbakemeldinger i form av belønning eller straff, får nettverket kunnskap. Å finne en policy eller strategi som optimaliserer kumulative belønninger over tid er målet for nettverket. Denne typen brukes ofte i spill- og beslutningsapplikasjoner.
Typer nevrale nettverk
Det er syv typer nevrale nettverk som kan brukes.
- Feedforward-nettverk: EN feedforward nevrale nettverk er en enkel kunstig nevrale nettverksarkitektur der data beveger seg fra inngang til utgang i en enkelt retning. Den har input-, skjulte og output-lag; tilbakemeldingssløyfer er fraværende. Den enkle arkitekturen gjør den passende for en rekke applikasjoner, for eksempel regresjon og mønstergjenkjenning.
- Multilayer Perceptron (MLP): MLP er en type feedforward nevrale nettverk med tre eller flere lag, inkludert et inngangslag, ett eller flere skjulte lag og et utgangslag. Den bruker ikke-lineære aktiveringsfunksjoner.
- Convolutional Neural Network (CNN): EN Konvolusjonelt nevralt nettverk (CNN) er et spesialisert kunstig nevralt nettverk designet for bildebehandling. Den bruker konvolusjonslag for automatisk å lære hierarkiske funksjoner fra inndatabilder, noe som muliggjør effektiv bildegjenkjenning og klassifisering. CNN-er har revolusjonert datasyn og er sentrale i oppgaver som gjenstandsgjenkjenning og bildeanalyse.
- Tilbakevendende nevrale nettverk (RNN): En kunstig nevrale nettverkstype beregnet for sekvensiell databehandling kalles a Tilbakevendende nevrale nettverk (RNN). Det er hensiktsmessig for applikasjoner der kontekstuelle avhengigheter er kritiske, for eksempel tidsserieprediksjon og naturlig språkbehandling, siden den bruker tilbakemeldingsløkker, som gjør at informasjon kan overleve i nettverket.
- Langtidsminne (LSTM): LSTM er en type RNN som er designet for å overvinne problemet med forsvinnende gradient ved trening av RNN. Den bruker minneceller og porter for selektivt å lese, skrive og slette informasjon.
Enkel implementering av et nevralt nettverk
Python3
import> numpy as np> # array of any amount of numbers. n = m> X>=> np.array([[>1>,>2>,>3>],> >[>3>,>4>,>1>],> >[>2>,>5>,>3>]])> # multiplication> y>=> np.array([[.>5>, .>3>, .>2>]])> # transpose of y> y>=> y.T> # sigma value> sigm>=> 2> # find the delta> delt>=> np.random.random((>3>,>3>))>-> 1> for> j>in> range>(>100>):> > ># find matrix 1. 100 layers.> >m1>=> (y>-> (>1>/>(>1> +> np.exp(>->(np.dot((>1>/>(>1> +> np.exp(> >->(np.dot(X, sigm))))), delt))))))>*>((>1>/>(> >1> +> np.exp(>->(np.dot((>1>/>(>1> +> np.exp(> >->(np.dot(X, sigm))))), delt)))))>*>(>1>->(>1>/>(> >1> +> np.exp(>->(np.dot((>1>/>(>1> +> np.exp(> >->(np.dot(X, sigm))))), delt)))))))> ># find matrix 2> >m2>=> m1.dot(delt.T)>*> ((>1>/>(>1> +> np.exp(>->(np.dot(X, sigm)))))> >*> (>1>->(>1>/>(>1> +> np.exp(>->(np.dot(X, sigm)))))))> ># find delta> >delt>=> delt>+> (>1>/>(>1> +> np.exp(>->(np.dot(X, sigm))))).T.dot(m1)> ># find sigma> >sigm>=> sigm>+> (X.T.dot(m2))> # print output from the matrix> print>(>1>/>(>1> +> np.exp(>->(np.dot(X, sigm)))))> |
>
>
Produksjon:
[[0.99999325 0.99999375 0.99999352] [0.99999988 0.99999989 0.99999988] [1. 1. 1. ]]>
Fordeler med nevrale nettverk
Nevrale nettverk er mye brukt i mange forskjellige applikasjoner på grunn av deres mange fordeler:
- Tilpasningsevne: Nevrale nettverk er nyttige for aktiviteter der koblingen mellom input og output er kompleks eller ikke godt definert fordi de kan tilpasse seg nye situasjoner og lære av data.
- Mønstergjenkjenning: Deres ferdigheter i mønstergjenkjenning gjør dem effektive i oppgaver som lyd- og bildeidentifikasjon, naturlig språkbehandling og andre intrikate datamønstre.
- Parallell behandling: Fordi nevrale nettverk er i stand til parallell prosessering av natur, kan de behandle mange jobber samtidig, noe som øker hastigheten på og forbedrer effektiviteten til beregninger.
- Ikke-linearitet: Nevrale nettverk er i stand til å modellere og forstå kompliserte forhold i data i kraft av de ikke-lineære aktiveringsfunksjonene som finnes i nevroner, som overvinner ulempene med lineære modeller.
Ulemper med nevrale nettverk
Nevrale nettverk, selv om de er kraftige, er ikke uten ulemper og vanskeligheter:
- Beregningsintensitet: Trening i store nevrale nettverk kan være en arbeidskrevende og beregningskrevende prosess som krever mye datakraft.
- Black box Nature: Som svarte boksmodeller utgjør nevrale nettverk et problem i viktige applikasjoner siden det er vanskelig å forstå hvordan de tar beslutninger.
- Overmontering: Overtilpasning er et fenomen der nevrale nettverk forplikter treningsmateriale til minnet i stedet for å identifisere mønstre i dataene. Selv om regulariseringstilnærminger bidrar til å lindre dette, eksisterer problemet fortsatt.
- Behov for store datasett: For effektiv opplæring trenger nevrale nettverk ofte store, merkede datasett; ellers kan ytelsen deres lide av ufullstendige eller skjeve data.
Ofte stilte spørsmål (FAQs)
1. Hva er et nevralt nettverk?
Et nevralt nettverk er et kunstig system laget av sammenkoblede noder (nevroner) som behandler informasjon, modellert etter strukturen til den menneskelige hjernen. Den brukes i maskinlæringsjobber der mønstre trekkes ut fra data.
2. Hvordan fungerer et nevralt nettverk?
Lag med tilkoblede nevroner behandler data i nevrale nettverk. Nettverket behandler inndata, endrer vekter under trening, og produserer en utgang avhengig av mønstre det har oppdaget.
3. Hva er de vanlige typene nevrale nettverksarkitekturer?
Feedforward nevrale nettverk, tilbakevendende nevrale nettverk (RNN), konvolusjonelle nevrale nettverk (CNN) og langtidskorttidsminnenettverk (LSTM) er eksempler på vanlige arkitekturer som hver er designet for en bestemt oppgave.
4. Hva er forskjellen mellom overvåket og uovervåket læring i nevrale nettverk?
I overvåket læring brukes merkede data til å trene et nevralt nettverk slik at det kan lære å kartlegge innganger til matchende utganger. Uovervåket læring arbeider med umerkede data og ser etter strukturer eller mønstre i dataene .
5. Hvordan håndterer nevrale nettverk sekvensielle data?
Tilbakemeldingssløyfene som tilbakevendende nevrale nettverk (RNN-er) inneholder lar dem behandle sekvensielle data og over tid fange opp avhengigheter og kontekst.