- Redshift er en rask og kraftig, fullt administrert, petabyte-skala datavarehustjeneste i skyen.
- Kunder kan bruke Redshift for bare
- Redshift er en rask og kraftig, fullt administrert, petabyte-skala datavarehustjeneste i skyen.
- Kunder kan bruke Redshift for bare $0,25 per time uten forpliktelser eller forhåndskostnader og skalere til en petabyte eller mer for $1000 per terabyte per år.
OLAP
OLAP er en Online analysebehandlingssystem brukt av Rødforskyvning .
Eksempel på OLAP-transaksjon:
Anta at vi ønsker å beregne nettofortjenesten for EMEA og Stillehavet for digitalradioproduktet. Dette krever å trekke et stort antall poster. Følgende er postene som kreves for å beregne en netto fortjeneste:
- Summen av radioer solgt i EMEA.
- Summen av radioer solgt i Stillehavet.
- Enhetskostnad for radio i hver region.
- Salgspris for hver radio
- Salgspris - enhetskostnad
De komplekse spørringene er nødvendige for å hente postene gitt ovenfor. Datavarehusdatabaser bruker forskjellige typer arkitektur både fra et databaseperspektiv og infrastrukturlag.
Konfigurasjon av rødforskyvning
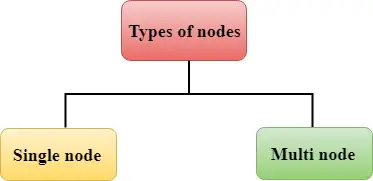
Rødforskyvning består av to typer noder:
Enkel node Multi-node Enkel node: En enkelt node lagrer opptil 160 GB.
Multi-node: Multi-node er en node som består av mer enn én node. Den er av to typer:
Ledernode
Den administrerer klientforbindelsene og mottar forespørsler. En ledernode mottar spørringene fra klientapplikasjonene, analyserer spørringene og utvikler utførelsesplanene. Den koordinerer med parallell utførelse av disse planene med beregningsnoden og kombinerer mellomresultatene til alle nodene, og returnerer deretter det endelige resultatet til klientapplikasjonen.Beregn node
En beregningsnode utfører utførelsesplanene, og deretter sendes mellomresultater til ledernoden for aggregering før de sendes tilbake til klientapplikasjonen. Den kan ha opptil 128 beregningsnoder.La oss forstå konseptet med ledernode og beregningsnoder gjennom et eksempel.
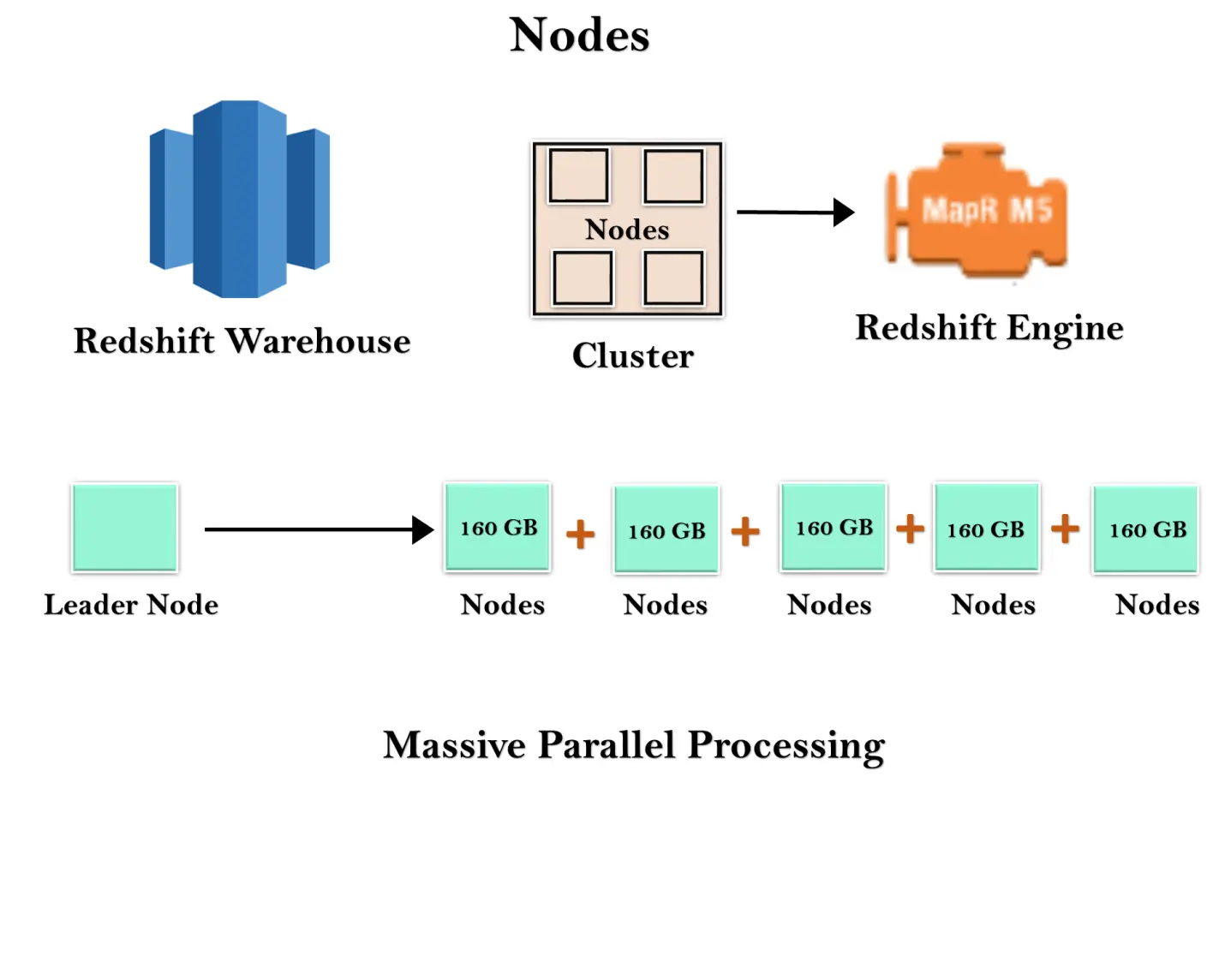
Redshift-varehus er en samling av dataressurser kjent som noder, og disse nodene er organisert i en gruppe kjent som en klynge. Hver klynge kjører i en Redshift Engine som inneholder en eller flere databaser.
Når du starter en Redshift-forekomst, starter den med en enkelt node på størrelse 160 GB. Når du vil vokse, kan du legge til flere noder for å dra nytte av parallell prosessering. Du har en ledernode som administrerer de flere nodene. Ledernoden håndterer klientforbindelsen så vel som beregningsnoder. Den lagrer dataene i beregningsnoder og utfører spørringen.
Hvorfor rødskift er 10 ganger raskere
Rødskifting er 10 ganger raskere på grunn av følgende årsaker:
Kolonnedatalagring
I stedet for å lagre data som en rekke rader, organiserer Amazon Redshift dataene etter kolonne. Radbaserte systemer er ideelle for transaksjonsbehandling, mens kolonnebaserte systemer er ideelle for datavarehus og analyser, der spørringer ofte involverer aggregater utført over store datasett. Siden bare kolonnene som er involvert i spørringene behandles og kolonnedata lagres i et lagringsmedium sekvensielt, krever kolonnebaserte systemer færre I/O-er, og forbedrer dermed spørringsytelsen.Avansert komprimering
Kolonnedatalagre kan komprimeres mye mer enn radbaserte datalagre fordi lignende data lagres sekvensielt på disken. Amazon Redshift bruker flere komprimeringsteknikker og kan ofte oppnå betydelig komprimering i forhold til tradisjonelle relasjonsdatalagre.
Amazon Redshift krever ikke indekser eller materialiserte visninger, så det krever mindre plass enn tradisjonelle relasjonsdatabasesystemer. Når du laster en data inn i en tom tabell, prøver Amazon Redshift dataene dine automatisk og velger den mest passende komprimeringsteknikken.Massivt parallell behandling
Amazon Redshift distribuerer automatisk dataene og laster spørringen over ulike noder. En Amazon Redshift gjør det enkelt å legge til nye noder til datavarehuset ditt, og dette lar oss oppnå raskere søkeytelse etter hvert som datavarehuset ditt vokser.Rødskiftefunksjoner
Funksjonene til Redshift er gitt nedenfor:
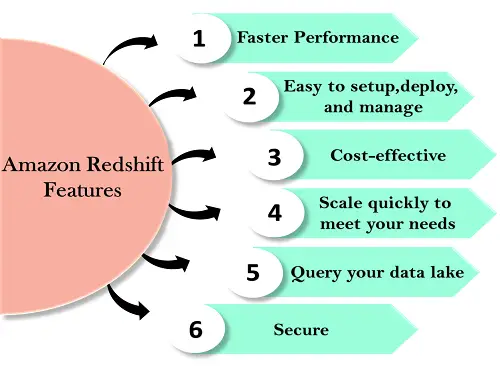
Enkel å sette opp, distribuere og administrere Automatisert klargjøring
Redshift er enkel å sette opp og betjene. Du kan distribuere et nytt datavarehus med bare noen få klikk i AWS-konsollen, og Redshift klargjør automatisk infrastrukturen for deg. I AWS er alle administrative oppgaver automatisert, som sikkerhetskopiering og replikering, du må fokusere på dataene dine, ikke på administrasjonen.Automatiserte sikkerhetskopier
Redshift sikkerhetskopierer dataene dine automatisk til S3. Du kan også replikere øyeblikksbildene i S3 i en annen region for enhver katastrofegjenoppretting.Kostnadseffektiv Ingen forhåndskostnader, betal mens du går
Amazon Redshift er den mest kostnadseffektive datavarehustjenesten ettersom du bare må betale for det du bruker.
Kostnadene starter med $0,25 per time uten forpliktelse og ingen forhåndskostnader og kan skaleres ut til $250 per terabyte per år.
Amazon Redshift er den eneste datavarehustjenesten som tilbyr On Demand-priser uten forhåndskostnader, og den tilbyr også reserverte forekomstpriser som sparer opptil 75 % ved å gi 1-3 års sikt.Velg nodetype.
Du kan velge en av de to nodene for å optimalisere rødforskyvningen.Tett beregningsnode
Tett beregningsnode kan skape et datavarehus med høy ytelse ved å bruke raske CPUer, en stor mengde RAM og solid-state disker.Tett lagringsnode
Hvis du vil redusere kostnadene, kan du bruke Dense storage node. Det skaper et kostnadseffektivt datavarehus ved å bruke en større harddisk.Skaler raskt for å møte dine behov. Petabyte-skala datavarehus
Amazon Redshift skalerer automatisk opp eller ned nodene i henhold til behovsendringene. Med bare noen få klikk i AWS-konsollen eller et enkelt API-kall kan du enkelt endre antall noder i et datavarehus.Exabyte-skala datainnsjøanalyse
Det er en funksjon i Redshift som lar deg kjøre spørringene mot exabyte med data i Amazon S3. Amazon S3 er en sikker og kostnadseffektiv data for å lagre ubegrenset data i et åpent format.Grenseløs samtidighet
Det er en funksjon av Redshift betyr at flere spørringer kan få tilgang til de samme dataene i Amazon S3. Den lar deg kjøre spørringene på tvers av flere noder uavhengig av kompleksiteten til en spørring eller mengden data.Spørr datainnsjøen din
Amazon Redshift er det eneste datavarehuset som brukes til å spørre Amazon S3-datasjøen uten å laste inn data. Dette gir fleksibilitet ved å lagre de ofte åpnede dataene i Redshift og ustrukturerte eller sjelden tilgang til data i Amazon S3.Sikre
Med et par parameterinnstillinger kan du stille inn Redshift til å bruke SSL for å sikre dataene dine. Du kan også aktivere kryptering, alle data som er skrevet til disken vil bli kryptert.Raskere ytelse
Amazon Redshift gir kolonnebasert datalagring, komprimering og parallell prosessering for å redusere mengden I/O som trengs for å utføre spørringer. Dette forbedrer søkeytelsen.
OLAP
OLAP er en Online analysebehandlingssystem brukt av Rødforskyvning .
Eksempel på OLAP-transaksjon:
Anta at vi ønsker å beregne nettofortjenesten for EMEA og Stillehavet for digitalradioproduktet. Dette krever å trekke et stort antall poster. Følgende er postene som kreves for å beregne en netto fortjeneste:
- Summen av radioer solgt i EMEA.
- Summen av radioer solgt i Stillehavet.
- Enhetskostnad for radio i hver region.
- Salgspris for hver radio
- Salgspris - enhetskostnad
De komplekse spørringene er nødvendige for å hente postene gitt ovenfor. Datavarehusdatabaser bruker forskjellige typer arkitektur både fra et databaseperspektiv og infrastrukturlag.
Konfigurasjon av rødforskyvning

Rødforskyvning består av to typer noder:
Enkel node: En enkelt node lagrer opptil 160 GB.
Multi-node: Multi-node er en node som består av mer enn én node. Den er av to typer:
Den administrerer klientforbindelsene og mottar forespørsler. En ledernode mottar spørringene fra klientapplikasjonene, analyserer spørringene og utvikler utførelsesplanene. Den koordinerer med parallell utførelse av disse planene med beregningsnoden og kombinerer mellomresultatene til alle nodene, og returnerer deretter det endelige resultatet til klientapplikasjonen.
En beregningsnode utfører utførelsesplanene, og deretter sendes mellomresultater til ledernoden for aggregering før de sendes tilbake til klientapplikasjonen. Den kan ha opptil 128 beregningsnoder.
La oss forstå konseptet med ledernode og beregningsnoder gjennom et eksempel.

Redshift-varehus er en samling av dataressurser kjent som noder, og disse nodene er organisert i en gruppe kjent som en klynge. Hver klynge kjører i en Redshift Engine som inneholder en eller flere databaser.
Når du starter en Redshift-forekomst, starter den med en enkelt node på størrelse 160 GB. Når du vil vokse, kan du legge til flere noder for å dra nytte av parallell prosessering. Du har en ledernode som administrerer de flere nodene. Ledernoden håndterer klientforbindelsen så vel som beregningsnoder. Den lagrer dataene i beregningsnoder og utfører spørringen.
Hvorfor rødskift er 10 ganger raskere
Rødskifting er 10 ganger raskere på grunn av følgende årsaker:
I stedet for å lagre data som en rekke rader, organiserer Amazon Redshift dataene etter kolonne. Radbaserte systemer er ideelle for transaksjonsbehandling, mens kolonnebaserte systemer er ideelle for datavarehus og analyser, der spørringer ofte involverer aggregater utført over store datasett. Siden bare kolonnene som er involvert i spørringene behandles og kolonnedata lagres i et lagringsmedium sekvensielt, krever kolonnebaserte systemer færre I/O-er, og forbedrer dermed spørringsytelsen.
Kolonnedatalagre kan komprimeres mye mer enn radbaserte datalagre fordi lignende data lagres sekvensielt på disken. Amazon Redshift bruker flere komprimeringsteknikker og kan ofte oppnå betydelig komprimering i forhold til tradisjonelle relasjonsdatalagre.
Amazon Redshift krever ikke indekser eller materialiserte visninger, så det krever mindre plass enn tradisjonelle relasjonsdatabasesystemer. Når du laster en data inn i en tom tabell, prøver Amazon Redshift dataene dine automatisk og velger den mest passende komprimeringsteknikken.
Amazon Redshift distribuerer automatisk dataene og laster spørringen over ulike noder. En Amazon Redshift gjør det enkelt å legge til nye noder til datavarehuset ditt, og dette lar oss oppnå raskere søkeytelse etter hvert som datavarehuset ditt vokser.
Rødskiftefunksjoner
Funksjonene til Redshift er gitt nedenfor:
sortere haug

- Redshift er en rask og kraftig, fullt administrert, petabyte-skala datavarehustjeneste i skyen.
- Kunder kan bruke Redshift for bare $0,25 per time uten forpliktelser eller forhåndskostnader og skalere til en petabyte eller mer for $1000 per terabyte per år.
- Summen av radioer solgt i EMEA.
- Summen av radioer solgt i Stillehavet.
- Enhetskostnad for radio i hver region.
- Salgspris for hver radio
- Salgspris - enhetskostnad
Redshift er enkel å sette opp og betjene. Du kan distribuere et nytt datavarehus med bare noen få klikk i AWS-konsollen, og Redshift klargjør automatisk infrastrukturen for deg. I AWS er alle administrative oppgaver automatisert, som sikkerhetskopiering og replikering, du må fokusere på dataene dine, ikke på administrasjonen.
Redshift sikkerhetskopierer dataene dine automatisk til S3. Du kan også replikere øyeblikksbildene i S3 i en annen region for enhver katastrofegjenoppretting.
Amazon Redshift er den mest kostnadseffektive datavarehustjenesten ettersom du bare må betale for det du bruker.
Kostnadene starter med
OLAP
OLAP er en Online analysebehandlingssystem brukt av Rødforskyvning .
Eksempel på OLAP-transaksjon:
Anta at vi ønsker å beregne nettofortjenesten for EMEA og Stillehavet for digitalradioproduktet. Dette krever å trekke et stort antall poster. Følgende er postene som kreves for å beregne en netto fortjeneste:
De komplekse spørringene er nødvendige for å hente postene gitt ovenfor. Datavarehusdatabaser bruker forskjellige typer arkitektur både fra et databaseperspektiv og infrastrukturlag.
Konfigurasjon av rødforskyvning
Rødforskyvning består av to typer noder:
Enkel node: En enkelt node lagrer opptil 160 GB.
Multi-node: Multi-node er en node som består av mer enn én node. Den er av to typer:
Den administrerer klientforbindelsene og mottar forespørsler. En ledernode mottar spørringene fra klientapplikasjonene, analyserer spørringene og utvikler utførelsesplanene. Den koordinerer med parallell utførelse av disse planene med beregningsnoden og kombinerer mellomresultatene til alle nodene, og returnerer deretter det endelige resultatet til klientapplikasjonen.
En beregningsnode utfører utførelsesplanene, og deretter sendes mellomresultater til ledernoden for aggregering før de sendes tilbake til klientapplikasjonen. Den kan ha opptil 128 beregningsnoder.
La oss forstå konseptet med ledernode og beregningsnoder gjennom et eksempel.
Redshift-varehus er en samling av dataressurser kjent som noder, og disse nodene er organisert i en gruppe kjent som en klynge. Hver klynge kjører i en Redshift Engine som inneholder en eller flere databaser.
Når du starter en Redshift-forekomst, starter den med en enkelt node på størrelse 160 GB. Når du vil vokse, kan du legge til flere noder for å dra nytte av parallell prosessering. Du har en ledernode som administrerer de flere nodene. Ledernoden håndterer klientforbindelsen så vel som beregningsnoder. Den lagrer dataene i beregningsnoder og utfører spørringen.
Hvorfor rødskift er 10 ganger raskere
Rødskifting er 10 ganger raskere på grunn av følgende årsaker:
I stedet for å lagre data som en rekke rader, organiserer Amazon Redshift dataene etter kolonne. Radbaserte systemer er ideelle for transaksjonsbehandling, mens kolonnebaserte systemer er ideelle for datavarehus og analyser, der spørringer ofte involverer aggregater utført over store datasett. Siden bare kolonnene som er involvert i spørringene behandles og kolonnedata lagres i et lagringsmedium sekvensielt, krever kolonnebaserte systemer færre I/O-er, og forbedrer dermed spørringsytelsen.
Kolonnedatalagre kan komprimeres mye mer enn radbaserte datalagre fordi lignende data lagres sekvensielt på disken. Amazon Redshift bruker flere komprimeringsteknikker og kan ofte oppnå betydelig komprimering i forhold til tradisjonelle relasjonsdatalagre.
Amazon Redshift krever ikke indekser eller materialiserte visninger, så det krever mindre plass enn tradisjonelle relasjonsdatabasesystemer. Når du laster en data inn i en tom tabell, prøver Amazon Redshift dataene dine automatisk og velger den mest passende komprimeringsteknikken.
Amazon Redshift distribuerer automatisk dataene og laster spørringen over ulike noder. En Amazon Redshift gjør det enkelt å legge til nye noder til datavarehuset ditt, og dette lar oss oppnå raskere søkeytelse etter hvert som datavarehuset ditt vokser.
Rødskiftefunksjoner
Funksjonene til Redshift er gitt nedenfor:
Redshift er enkel å sette opp og betjene. Du kan distribuere et nytt datavarehus med bare noen få klikk i AWS-konsollen, og Redshift klargjør automatisk infrastrukturen for deg. I AWS er alle administrative oppgaver automatisert, som sikkerhetskopiering og replikering, du må fokusere på dataene dine, ikke på administrasjonen.
Redshift sikkerhetskopierer dataene dine automatisk til S3. Du kan også replikere øyeblikksbildene i S3 i en annen region for enhver katastrofegjenoppretting.
Amazon Redshift er den mest kostnadseffektive datavarehustjenesten ettersom du bare må betale for det du bruker.
Kostnadene starter med $0,25 per time uten forpliktelse og ingen forhåndskostnader og kan skaleres ut til $250 per terabyte per år.
Amazon Redshift er den eneste datavarehustjenesten som tilbyr On Demand-priser uten forhåndskostnader, og den tilbyr også reserverte forekomstpriser som sparer opptil 75 % ved å gi 1-3 års sikt.
Du kan velge en av de to nodene for å optimalisere rødforskyvningen.
Tett beregningsnode kan skape et datavarehus med høy ytelse ved å bruke raske CPUer, en stor mengde RAM og solid-state disker.
Hvis du vil redusere kostnadene, kan du bruke Dense storage node. Det skaper et kostnadseffektivt datavarehus ved å bruke en større harddisk.
Amazon Redshift skalerer automatisk opp eller ned nodene i henhold til behovsendringene. Med bare noen få klikk i AWS-konsollen eller et enkelt API-kall kan du enkelt endre antall noder i et datavarehus.
Det er en funksjon i Redshift som lar deg kjøre spørringene mot exabyte med data i Amazon S3. Amazon S3 er en sikker og kostnadseffektiv data for å lagre ubegrenset data i et åpent format.
Det er en funksjon av Redshift betyr at flere spørringer kan få tilgang til de samme dataene i Amazon S3. Den lar deg kjøre spørringene på tvers av flere noder uavhengig av kompleksiteten til en spørring eller mengden data.
Amazon Redshift er det eneste datavarehuset som brukes til å spørre Amazon S3-datasjøen uten å laste inn data. Dette gir fleksibilitet ved å lagre de ofte åpnede dataene i Redshift og ustrukturerte eller sjelden tilgang til data i Amazon S3.
Med et par parameterinnstillinger kan du stille inn Redshift til å bruke SSL for å sikre dataene dine. Du kan også aktivere kryptering, alle data som er skrevet til disken vil bli kryptert.
Amazon Redshift gir kolonnebasert datalagring, komprimering og parallell prosessering for å redusere mengden I/O som trengs for å utføre spørringer. Dette forbedrer søkeytelsen.
Amazon Redshift er den eneste datavarehustjenesten som tilbyr On Demand-priser uten forhåndskostnader, og den tilbyr også reserverte forekomstpriser som sparer opptil 75 % ved å gi 1-3 års sikt.
Du kan velge en av de to nodene for å optimalisere rødforskyvningen.
Tett beregningsnode kan skape et datavarehus med høy ytelse ved å bruke raske CPUer, en stor mengde RAM og solid-state disker.
Hvis du vil redusere kostnadene, kan du bruke Dense storage node. Det skaper et kostnadseffektivt datavarehus ved å bruke en større harddisk.
Amazon Redshift skalerer automatisk opp eller ned nodene i henhold til behovsendringene. Med bare noen få klikk i AWS-konsollen eller et enkelt API-kall kan du enkelt endre antall noder i et datavarehus.
Det er en funksjon i Redshift som lar deg kjøre spørringene mot exabyte med data i Amazon S3. Amazon S3 er en sikker og kostnadseffektiv data for å lagre ubegrenset data i et åpent format.
Det er en funksjon av Redshift betyr at flere spørringer kan få tilgang til de samme dataene i Amazon S3. Den lar deg kjøre spørringene på tvers av flere noder uavhengig av kompleksiteten til en spørring eller mengden data.
Amazon Redshift er det eneste datavarehuset som brukes til å spørre Amazon S3-datasjøen uten å laste inn data. Dette gir fleksibilitet ved å lagre de ofte åpnede dataene i Redshift og ustrukturerte eller sjelden tilgang til data i Amazon S3.
Med et par parameterinnstillinger kan du stille inn Redshift til å bruke SSL for å sikre dataene dine. Du kan også aktivere kryptering, alle data som er skrevet til disken vil bli kryptert.
Amazon Redshift gir kolonnebasert datalagring, komprimering og parallell prosessering for å redusere mengden I/O som trengs for å utføre spørringer. Dette forbedrer søkeytelsen.