Excel-ark er veldig instinktive og brukervennlige, noe som gjør dem ideelle for å manipulere store datasett selv for mindre tekniske folk. Hvis du leter etter steder å lære å manipulere og automatisere ting i Excel-filer ved hjelp av Python , se ikke lenger. Du er på rett sted.
I denne artikkelen lærer du hvordan du bruker Pandaer å jobbe med Excel-regneark. I denne artikkelen vil vi lære om:
- Lese Excel-fil bruker Pandas i Python
- Installere og importere pandaer
- Lese flere Excel-ark ved hjelp av Pandas
- Anvendelse av forskjellige Panda-funksjoner
Leser Excel-fil ved hjelp av Pandas i Python
Installere pandaer
For å installere Pandas i Python, kan vi bruke følgende kommando i ledeteksten:
pip install pandas>
For å installere Pandas i Anaconda, kan vi bruke følgende kommando i Anaconda Terminal:
conda install pandas>
Importerer pandaer
Først av alt må vi importere Pandas-modulen som kan gjøres ved å kjøre kommandoen:
Python3
import> pandas as pd> |
>
>
Inndatafil: La oss anta at Excel-filen ser slik ut
Ark 1:

Ark 1
Ark 2:
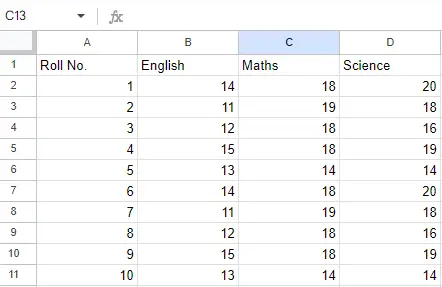
Ark 2
Nå kan vi importere Excel-filen ved å bruke read_excel-funksjonen i Pandas for å lese Excel-fil ved hjelp av Pandas i Python. Den andre setningen leser dataene fra Excel og lagrer dem i en pandas dataramme som er representert av variabelen newData.
Python3
df>=> pd.read_excel(>'Example.xlsx'>)> print>(df)> |
>
>
Produksjon:
Roll No. English Maths Science 0 1 19 13 17 1 2 14 20 18 2 3 15 18 19 3 4 13 14 14 4 5 17 16 20 5 6 19 13 17 6 7 14 20 18 7 8 15 18 19 8 9 13 14 14 9 10 17 16 20>
Laster flere ark ved hjelp av Concat()-metoden
Hvis det er flere ark i Excel-arbeidsboken, vil kommandoen importere data fra det første arket. For å lage en dataramme med alle arkene i arbeidsboken, er den enkleste metoden å lage forskjellige datarammer separat og deretter sette dem sammen. Read_excel-metoden tar argumentet sheet_name og index_col hvor vi kan spesifisere arket som rammen skal være laget av og index_col spesifiserer tittelkolonnen, som vist nedenfor:
Eksempel:
Den tredje setningen setter sammen begge arkene. Nå for å sjekke hele datarammen, kan vi ganske enkelt kjøre følgende kommando:
alfabet med tall
Python3
file> => 'Example.xlsx'> sheet1>=> pd.read_excel(>file>,> >sheet_name>=> 0>,> >index_col>=> 0>)> sheet2>=> pd.read_excel(>file>,> >sheet_name>=> 1>,> >index_col>=> 0>)> # concatinating both the sheets> newData>=> pd.concat([sheet1, sheet2])> print>(newData)> |
>
>
Produksjon:
Roll No. English Maths Science 1 19 13 17 2 14 20 18 3 15 18 19 4 13 14 14 5 17 16 20 6 19 13 17 7 14 20 18 8 15 18 19 9 13 14 14 10 17 16 20 1 14 18 20 2 11 19 18 3 12 18 16 4 15 18 19 5 13 14 14 6 14 18 20 7 11 19 18 8 12 18 16 9 15 18 19 10 13 14 14>
Head() og Tail() metoder i Pandas
For å se 5 kolonner fra toppen og fra bunnen av datarammen, kan vi kjøre kommandoen. Dette hode() og hale() metoden tar også argumenter som tall for antall kolonner som skal vises.
Python3
print>(newData.head())> print>(newData.tail())> |
>
>
Produksjon:
English Maths Science Roll No. 1 19 13 17 2 14 20 18 3 15 18 19 4 13 14 14 5 17 16 20 English Maths Science Roll No. 6 14 18 20 7 11 19 18 8 12 18 16 9 15 18 19 10 13 14 14>
Shape()-metoden
De form()-metoden kan brukes til å vise antall rader og kolonner i datarammen som følger:
Python3
newData.shape> |
>
>
Produksjon:
(20, 3)>
Sort_values()-metoden i Pandas
Hvis en kolonne inneholder numeriske data, kan vi sortere den kolonnen ved å bruke sort_verdier() metode i pandaer som følger:
Python3
java liste node
sorted_column>=> newData.sort_values([>'English'>], ascending>=> False>)> |
>
>
La oss nå anta at vi vil ha de 5 øverste verdiene i den sorterte kolonnen, vi kan bruke head()-metoden her:
Python3
sorted_column.head(>5>)> |
>
>
Produksjon:
English Maths Science Roll No. 1 19 13 17 6 19 13 17 5 17 16 20 10 17 16 20 3 15 18 19>
Vi kan gjøre det med en hvilken som helst numerisk kolonne i datarammen som vist nedenfor:
Python3
java programvare mønstre
newData[>'Maths'>].head()> |
>
>
Produksjon:
Roll No. 1 13 2 20 3 18 4 14 5 16 Name: Maths, dtype: int64>
Pandas Describe() metode
Anta nå at dataene våre stort sett er numeriske. Vi kan få statistisk informasjon som gjennomsnitt, maks, min osv. om datarammen ved å bruke beskrive() metode som vist nedenfor:
Python3
newData.describe()> |
>
>
Produksjon:
English Maths Science count 20.00000 20.000000 20.000000 mean 14.30000 16.800000 17.500000 std 2.29645 2.330575 2.164304 min 11.00000 13.000000 14.000000 25% 13.00000 14.000000 16.000000 50% 14.00000 18.000000 18.000000 75% 15.00000 18.000000 19.000000 max 19.00000 20.000000 20.000000>
Dette kan også gjøres separat for alle de numeriske kolonnene ved å bruke følgende kommando:
Python3
newData[>'English'>].mean()> |
>
kan en abstrakt klasse ha en konstruktør
>
Produksjon:
14.3>
Annen statistisk informasjon kan også beregnes ved hjelp av de respektive metodene. Som i Excel kan formler også brukes, og beregnede kolonner kan opprettes som følger:
Python3
newData[>'Total Marks'>]>=> >newData[>'English'>]>+> newData[>'Maths'>]>+> newData[>'Science'>]> newData[>'Total Marks'>].head()> |
>
>
Produksjon:
Roll No. 1 49 2 52 3 52 4 41 5 53 Name: Total Marks, dtype: int64>
Etter å ha operert på dataene i datarammen, kan vi eksportere dataene tilbake til en Excel-fil ved å bruke metoden to_excel. For dette må vi spesifisere en utdata Excel-fil der de transformerte dataene skal skrives, som vist nedenfor:
Python3
newData.to_excel(>'Output File.xlsx'>)> |
>
>
Produksjon:
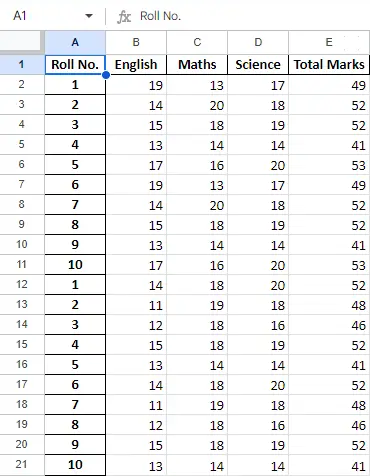
Endelig ark