BERT, et akronym for toveis koderepresentasjoner fra transformatorer , står som en åpen kildekode rammeverk for maskinlæring designet for riket av naturlig språkbehandling (NLP) . Med opprinnelse i 2018, ble dette rammeverket laget av forskere fra Google AI Language. Artikkelen tar sikte på å utforske arkitektur, arbeid og applikasjoner av BERT .
Hva er BERT?
BERT (Toveis koderepresentasjoner fra transformatorer) utnytter et transformatorbasert nevralt nettverk for å forstå og generere menneskelignende språk. BERT bruker en koder-arkitektur. I originalen Transformatorarkitektur , er det både koder- og dekodermoduler. Beslutningen om å bruke en kun koderarkitektur i BERT antyder en primær vekt på å forstå inngangssekvenser i stedet for å generere utgangssekvenser.
Toveis tilnærming av BERT
Tradisjonelle språkmodeller behandler tekst sekvensielt, enten fra venstre til høyre eller høyre til venstre. Denne metoden begrenser modellens bevissthet til den umiddelbare konteksten før målordet. BERT bruker en toveis tilnærming som vurderer både venstre og høyre kontekst av ord i en setning, i stedet for å analysere teksten sekvensielt, ser BERT på alle ordene i en setning samtidig.
Eksempel: Banken ligger på _______ av elven.
I en ensrettet modell vil forståelsen av blanketten i stor grad avhenge av de foregående ordene, og modellen kan slite med å finne ut om banken refererer til en finansinstitusjon eller siden av elven.
BERT, som er toveis, vurderer samtidig både venstre (Breden ligger på) og høyre kontekst (av elven), noe som muliggjør en mer nyansert forståelse. Den forstår at det manglende ordet sannsynligvis er relatert til bankens geografiske plassering, noe som viser den kontekstuelle rikdommen som den toveis tilnærmingen gir.
Førtrening og finjustering
BERT-modellen gjennomgår en to-trinns prosess:
- Foropplæring på store mengder umerket tekst for å lære kontekstuelle innebygginger.
- Finjustering av merkede data for spesifikke NLP oppgaver.
Foropplæring på store data
- BERT er forhåndsopplært på store mengder umerket tekstdata. Modellen lærer kontekstuelle innebygginger, som er representasjoner av ord som tar hensyn til deres omgivende kontekst i en setning.
- BERT engasjerer seg i ulike uovervåkede førtreningsoppgaver. Den kan for eksempel lære å forutsi manglende ord i en setning (Masked Language Model eller MLM-oppgave), forstå forholdet mellom to setninger, eller forutsi neste setning i et par.
Finjustering av merkede data
- Etter foropplæringsfasen finjusteres BERT-modellen, bevæpnet med dens kontekstuelle innebygging, for spesifikke NLP-oppgaver (natural language processing). Dette trinnet skreddersyr modellen til mer målrettede applikasjoner ved å tilpasse dens generelle språkforståelse til nyansene i den spesielle oppgaven.
- BERT er finjustert ved å bruke merkede data som er spesifikke for nedstrømsoppgavene av interesse. Disse oppgavene kan omfatte sentimentanalyse, svar på spørsmål, navngitt enhetsgodkjenning , eller en annen NLP-applikasjon. Modellens parametere justeres for å optimalisere ytelsen for de spesielle kravene til oppgaven.
BERTs enhetlige arkitektur lar den tilpasse seg ulike nedstrømsoppgaver med minimale modifikasjoner, noe som gjør den til et allsidig og svært effektivt verktøy i naturlig språkforståelse og behandling.
Hvordan fungerer BERT?
BERT er designet for å generere en språkmodell, så det er kun kodemekanismen som brukes. Sekvens av tokens mates til Transformer-koderen. Disse tokens blir først innebygd i vektorer og deretter behandlet i det nevrale nettverket. Utgangen er en sekvens av vektorer, som hver tilsvarer et inputtoken, og gir kontekstualiserte representasjoner.
Når du trener språkmodeller, er det en utfordring å definere et prediksjonsmål. Mange modeller forutsier neste ord i en sekvens, som er en retningsbestemt tilnærming og kan begrense kontekstlæring. BERT løser denne utfordringen med to innovative treningsstrategier:
- Masked Language Model (MLM)
- Prediksjon av neste setning (NSP)
1. Masked Language Model (MLM)
I BERTs foropplæringsprosess maskeres en del av ordene i hver inndatasekvens, og modellen trenes til å forutsi de opprinnelige verdiene til disse maskerte ordene basert på konteksten gitt av de omkringliggende ordene.
For å si det enkelt,
- Maskeringsord: Før BERT lærer av setninger, skjuler den noen ord (ca. 15%) og erstatter dem med et spesielt symbol, som [MASK].
- Gjett skjulte ord: BERTs jobb er å finne ut hva disse skjulte ordene er ved å se på ordene rundt dem. Det er som et spill med å gjette hvor noen ord mangler, og BERT prøver å fylle ut tomrommene.
- Slik lærer BERT:
- BERT legger et spesielt lag på toppen av læringssystemet sitt for å gjøre disse gjetningene. Den sjekker deretter hvor nær gjetningene er de faktiske skjulte ordene.
- Det gjør dette ved å konvertere sine gjetninger til sannsynligheter, og si: Jeg tror dette ordet er X, og jeg er så sikker på det.
- Spesiell oppmerksomhet til skjulte ord
- BERTs hovedfokus under trening er å få disse skjulte ordene riktig. Den bryr seg mindre om å forutsi ordene som ikke er skjult.
- Dette er fordi den virkelige utfordringen er å finne ut de manglende delene, og denne strategien hjelper BERT til å bli virkelig god til å forstå betydningen og konteksten til ord.
I tekniske termer,
- BERT legger til et klassifiseringslag på toppen av utdataene fra koderen. Dette laget er avgjørende for å forutsi de maskerte ordene.
- Utgangsvektorene fra klassifiseringslaget multipliseres med den innebygde matrisen, og transformerer dem til vokabulardimensjonen. Dette trinnet hjelper til med å justere de forutsagte representasjonene med ordforrådet.
- Sannsynligheten for hvert ord i vokabularet beregnes ved å bruke SoftMax aktiveringsfunksjon . Dette trinnet genererer en sannsynlighetsfordeling over hele vokabularet for hver maskerte posisjon.
- Tapsfunksjonen som brukes under trening vurderer kun prediksjonen av de maskerte verdiene. Modellen straffes for avviket mellom dens prediksjoner og de faktiske verdiene til de maskerte ordene.
- Modellen konvergerer langsommere enn retningsbestemte modeller. Dette er fordi BERT under trening kun er opptatt av å forutsi de maskerte verdiene, og ignorerer prediksjonen til de ikke-maskerte ordene. Den økte kontekstbevisstheten oppnådd gjennom denne strategien kompenserer for den langsommere konvergensen.
2. Prediksjon av neste setning (NSP)
BERT forutsier om den andre setningen er koblet til den første. Dette gjøres ved å transformere utgangen til [CLS]-tokenet til en 2×1-formet vektor ved å bruke et klassifiseringslag, og deretter beregne sannsynligheten for om den andre setningen følger den første ved å bruke SoftMax.
- I opplæringsprosessen lærer BERT å forstå forholdet mellom setningspar, og forutsi om den andre setningen følger den første i originaldokumentet.
- 50 % av inputparene har den andre setningen som påfølgende setning i originaldokumentet, og de andre 50 % har en tilfeldig valgt setning.
- For å hjelpe modellen med å skille mellom koblede og frakoblede setningspar. Inndata behandles før du går inn i modellen:
- Et [CLS]-token settes inn i begynnelsen av den første setningen, og et [SEP]-token legges til på slutten av hver setning.
- En setning som angir setning A eller setning B, legges til hver token.
- En posisjonell innebygging indikerer posisjonen til hvert token i sekvensen.
- BERT forutsier om den andre setningen er koblet til den første. Dette gjøres ved å transformere utgangen til [CLS]-tokenet til en 2×1-formet vektor ved å bruke et klassifiseringslag, og deretter beregne sannsynligheten for om den andre setningen følger den første ved å bruke SoftMax.
Under opplæringen av BERT-modellen trenes Masked LM og Next Sentence Prediction sammen. Modellen tar sikte på å minimere den kombinerte tapsfunksjonen til Masked LM og Next Sentence Prediction, noe som fører til en robust språkmodell med forbedrede evner til å forstå kontekst i setninger og forhold mellom setninger.
Hvorfor trene Masked LM og Next Sentence Prediction sammen?
Masked LM hjelper BERT å forstå konteksten innenfor en setning og Neste setningsprediksjon hjelper BERT å forstå sammenhengen eller forholdet mellom setningspar. Trening av begge strategiene sammen sikrer derfor at BERT lærer en bred og omfattende forståelse av språk, og fanger både detaljer i setninger og flyten mellom setninger.
BERT arkitekturer
Arkitekturen til BERT er en flerlags toveis transformatorkoder som er ganske lik transformatormodellen. En transformatorarkitektur er et koder-dekodernettverk som bruker selvoppmerksomhet på kodersiden og oppmerksomhet på dekodersiden.
- BERTUTGANGSPUNKThar 1 2 lag i Encoder-stabelen mens BERTSTORhar 24 lag i Encoder-stabelen . Disse er mer enn Transformer-arkitekturen beskrevet i den originale artikkelen ( 6 koderlag ).
- BERT-arkitekturer (BASE og LARGE) har også større feedforward-nettverk (henholdsvis 768 og 1024 skjulte enheter), og flere oppmerksomhetshoder (henholdsvis 12 og 16) enn Transformer-arkitekturen antydet i den originale artikkelen. Det inneholder 512 skjulte enheter og 8 oppmerksomhetshoder .
- BERTUTGANGSPUNKTinneholder 110M parametere mens BERTSTORhar 340M parametere.

BERT BASE og BERT LARGE arkitektur.
Denne modellen tar CLS token som input først, deretter blir den etterfulgt av en sekvens med ord som input. Her er CLS et klassifiseringstegn. Den sender deretter inndataene til lagene ovenfor. Hvert lag gjelder selvoppmerksomhet og sender resultatet gjennom et feedforward-nettverk etter at det overføres til neste koder. Modellen sender ut en vektor med skjult størrelse ( 768 for BERT BASE). Hvis vi ønsker å sende ut en klassifikator fra denne modellen, kan vi ta utgangen som tilsvarer CLS-tokenet.
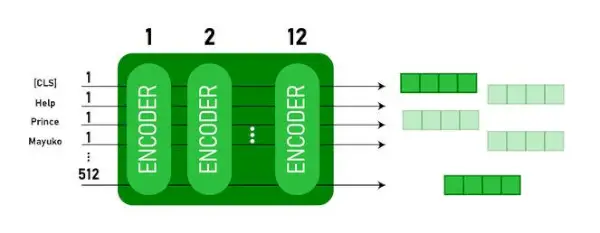
BERT-utgang som innebygginger
Nå kan denne trente vektoren brukes til å utføre en rekke oppgaver som klassifisering, oversettelse osv. For eksempel oppnår papiret flotte resultater bare ved å bruke et enkelt lag Nevrale nettverket på BERT-modellen i klassifiseringsoppgaven.
Hvordan bruke BERT-modellen i NLP?
BERT kan brukes til ulike naturlig språkbehandling (NLP) oppgaver som:
1. Klassifiseringsoppgave
- BERT kan brukes til klassifiseringsoppgaver som sentimentanalyse , målet er å klassifisere teksten i forskjellige kategorier (positiv/negativ/nøytral), BERT kan brukes ved å legge til et klassifiseringslag på toppen av transformatorutgangen for [CLS] token.
- [CLS]-tokenet representerer den aggregerte informasjonen fra hele inndatasekvensen. Denne sammenslåtte representasjonen kan deretter brukes som input for et klassifiseringslag for å lage spådommer for den spesifikke oppgaven.
2. Spørsmålssvar
- I spørsmålsoppgaver, hvor modellen er pålagt å lokalisere og merke svaret innenfor en gitt tekstsekvens, kan BERT trenes til dette formålet.
- BERT er opplært til å svare på spørsmål ved å lære ytterligere to vektorer som markerer begynnelsen og slutten av svaret. Under opplæringen blir modellen utstyrt med spørsmål og tilsvarende passasjer, og den lærer å forutsi start- og sluttposisjonene til svaret i passasjen.
3. Navngitt enhetsgjenkjenning (NER)
- BERT kan brukes for NER, hvor målet er å identifisere og klassifisere enheter (f.eks. Person, Organisasjon, Dato) i en tekstsekvens.
- En BERT-basert NER-modell trenes ved å ta utgangsvektoren til hvert token fra transformatoren og mate den inn i et klassifiseringslag. Laget forutsier den navngitte enhetsetiketten for hvert token, og indikerer typen enhet det representerer.
Hvordan tokenisere og kode tekst ved hjelp av BERT?
For å tokenisere og kode tekst ved hjelp av BERT, vil vi bruke 'transformator'-biblioteket i Python.
Kommando for å installere transformatorer:
!pip install transformers>
- Vi vil laste den forhåndstrente BERT-tokeniseringen med et vokabular med bokser ved hjelp av BertTokenizer.from_pretrained(bert-base-cased) .
- tokenizer.encode(tekst) tokeniserer inndatateksten og konverterer den til en sekvens av token-ID-er.
- print (Token IDer:, koding) skriver ut token-ID-ene som er oppnådd etter koding.
- tokenizer.convert_ids_to_tokens(encoding) konverterer token-ID-ene tilbake til deres tilsvarende tokens.
- print (Tokens:, tokens) skriver ut tokenene som er oppnådd etter konvertering av token-ID-ene
Python3
from> transformers>import> BertTokenizer> # Load pre-trained BERT tokenizer> tokenizer>=> BertTokenizer.from_pretrained(>'bert-base-cased'>)> # Input text> text>=> 'ChatGPT is a language model developed by OpenAI, based on the GPT (Generative Pre-trained Transformer) architecture. '> # Tokenize and encode the text> encoding>=> tokenizer.encode(text)> # Print the token IDs> print>(>'Token IDs:'>, encoding)> # Convert token IDs back to tokens> tokens>=> tokenizer.convert_ids_to_tokens(encoding)> # Print the corresponding tokens> print>(>'Tokens:'>, tokens)> |
>
>
Produksjon:
Token IDs: [101, 24705, 1204, 17095, 1942, 1110, 170, 1846, 2235, 1872, 1118, 3353, 1592, 2240, 117, 1359, 1113, 1103, 15175, 1942, 113, 9066, 15306, 11689, 118, 3972, 13809, 23763, 114, 4220, 119, 102] Tokens: ['[CLS]', 'Cha', '##t', '##GP', '##T', 'is', 'a', 'language', 'model', 'developed', 'by', 'Open', '##A', '##I', ',', 'based', 'on', 'the', 'GP', '##T', '(', 'Gene', '##rative', 'Pre', '-', 'trained', 'Trans', '##former', ')', 'architecture', '.', '[SEP]']> De tokenizer.encode metoden legger til det spesielle [CLS] – klassifisering og [SEP] – separator tokens på begynnelsen og slutten av den kodede sekvensen.
Anvendelse av BERT
BERT brukes til:
- Tekstrepresentasjon: BERT brukes til å generere ordinnbygging eller representasjon for ord i en setning.
- Navngitt enhetsgjenkjenning (NER) : BERT kan finjusteres for navngitte enhetsgjenkjenningsoppgaver, der målet er å identifisere enheter som navn på personer, organisasjoner, lokasjoner osv. i en gitt tekst.
- Tekstklassifisering: BERT er mye brukt for tekstklassifiseringsoppgaver, inkludert sentimentanalyse, spam-deteksjon og emnekategorisering. Den har vist utmerket ytelse når det gjelder å forstå og klassifisere konteksten til tekstdata.
- Spørsmålssvarssystemer: BERT har blitt brukt på spørsmålssvarssystemer, der modellen er opplært til å forstå konteksten til et spørsmål og gi relevante svar. Dette er spesielt nyttig for oppgaver som leseforståelse.
- Maskinoversettelse: BERTs kontekstuelle innebygginger kan utnyttes for å forbedre maskinoversettelsessystemer. Modellen fanger opp nyansene i språket som er avgjørende for nøyaktig oversettelse.
- Tekstoppsummering: BERT kan brukes til abstrakt tekstoppsummering, der modellen genererer konsise og meningsfulle oppsummeringer av lengre tekster ved å forstå konteksten og semantikken.
- Konversasjons-AI: BERT er ansatt i å bygge konversasjons-AI-systemer, som chatbots, virtuelle assistenter og dialogsystemer. Dens evne til å forstå kontekst gjør den effektiv for å forstå og generere naturlige språkresponser.
- Semantisk likhet: BERT-innbygginger kan brukes til å måle semantisk likhet mellom setninger eller dokumenter. Dette er verdifullt i oppgaver som duplikatdeteksjon, parafraseidentifikasjon og informasjonsinnhenting.
BERT vs GPT
Forskjellen mellom BERT og GPT er som følger:
| BERT | GPT | |
|---|---|---|
| Arkitektur | BERT er designet for toveis representasjonslæring. Den bruker et maskert språkmodellmål, der det forutsier manglende ord i en setning basert på både venstre og høyre kontekst. | GPT, på den annen side, er designet for generativ språkmodellering. Den forutsier det neste ordet i en setning gitt den foregående konteksten, ved å bruke en ensrettet autoregressiv tilnærming. |
| Mål før opplæring | BERT er forhåndsopplært ved å bruke et maskert språkmodellmål og neste setningsprediksjon. Den fokuserer på å fange toveis kontekst og forstå forhold mellom ord i en setning. | GPT er forhåndsopplært til å forutsi neste ord i en setning, noe som oppmuntrer modellen til å lære en sammenhengende representasjon av språk og generere kontekstuelt relevante sekvenser. |
| Kontekstforståelse | BERT er effektivt for oppgaver som krever en dyp forståelse av kontekst og relasjoner i en setning, for eksempel tekstklassifisering, navngitt enhetsgjenkjenning og spørsmålssvar. | GPT er sterk i å generere sammenhengende og kontekstuelt relevant tekst. Det brukes ofte i kreative oppgaver, dialogsystemer og oppgaver som krever generering av naturlige språksekvenser. |
| Oppgavetyper og brukstilfeller
| Vanligvis brukt i oppgaver som tekstklassifisering, navngitt enhetsgjenkjenning, sentimentanalyse og spørsmålssvar. | Brukes på oppgaver som tekstgenerering, dialogsystemer, oppsummering og kreativ skriving. |
| Finjustering vs få-skuddslæring | BERT finjusteres ofte på spesifikke nedstrømsoppgaver med merkede data for å tilpasse sine forhåndstrente representasjoner til den aktuelle oppgaven. | GPT er designet for å utføre få-skuddslæring, der det kan generaliseres til nye oppgaver med minimalt med oppgavespesifikke treningsdata. |
Sjekk også:
- Sentimentklassifisering ved bruk av BERT
- Hvordan generere Word Embedding ved hjelp av BERT?
- BART-modell for autofullføring av tekst i NLP
- Giftig kommentarklassifisering ved bruk av BERT
- Prediksjon av neste setning ved bruk av BERT
Ofte stilte spørsmål (FAQs)
Sp. Hva brukes BERT til?
BERT brukes til å utføre NLP-oppgaver som tekstrepresentasjon, navngitt enhetsgjenkjenning, tekstklassifisering, Q&A-systemer, maskinoversettelse, tekstoppsummering og mer.
Sp. Hva er fordelene med BERT-modellen?
BERT-språkmodellen skiller seg ut på grunn av sin omfattende foropplæring i flere språk, og tilbyr en bred språklig dekning sammenlignet med andre modeller. Dette gjør BERT spesielt fordelaktig for ikke-engelskbaserte prosjekter, siden det gir robuste kontekstuelle representasjoner og semantisk forståelse på tvers av et mangfold av språk, noe som øker allsidigheten i flerspråklige applikasjoner.
Q. Hvordan fungerer BERT for sentimentanalyse?
BERT utmerker seg i sentimentanalyse ved å utnytte sin toveis representasjonslæring for å fange kontekstuelle nyanser, semantiske betydninger og syntaktiske strukturer i en gitt tekst. Dette gjør det mulig for BERT å forstå sentimentet uttrykt i en setning ved å vurdere forholdet mellom ord, noe som resulterer i svært effektive sentimentanalyseresultater.
rekke strenger i c-programmering
Sp. Er Google basert på BERT?
BERT og RankBrain er komponenter av Googles søkealgoritme for å behandle søk og nettsideinnhold for å få bedre forståelse for å forbedre søkeresultatene.