Hash-kart er indekserte datastrukturer. Et hash-kart bruker en hash-funksjon å beregne en indeks med en nøkkel i en rekke bøtter eller spor. Verdien tilordnes til bøtten med den tilsvarende indeksen. Nøkkelen er unik og uforanderlig. Tenk på et hash-kart som et skap med skuffer med etiketter for tingene som er lagret i dem. For eksempel, lagring av brukerinformasjon – betrakt e-post som nøkkelen, og vi kan tilordne verdier som tilsvarer den brukeren som fornavn, etternavn osv. til en bøtte.
java samling
Hash-funksjon er kjernen i å implementere et hash-kart. Den tar inn nøkkelen og oversetter den til indeksen til en bøtte i bøttelisten. Ideell hashing bør produsere en annen indeks for hver nøkkel. Imidlertid kan kollisjoner forekomme. Når hashing gir en eksisterende indeks, kan vi ganske enkelt bruke en bøtte for flere verdier ved å legge til en liste eller ved å rehashing.
I Python er ordbøker eksempler på hash-kart. Vi vil se implementeringen av hash-kart fra bunnen av for å lære hvordan du bygger og tilpasser slike datastrukturer for å optimalisere søk.
Hash-kartdesignet vil inkludere følgende funksjoner:
- set_val(nøkkel, verdi): Setter inn et nøkkelverdi-par i hash-kartet. Hvis verdien allerede finnes i hash-kartet, oppdaterer du verdien.
- get_val(nøkkel): Returnerer verdien som den angitte nøkkelen er tilordnet til, eller Ingen post funnet hvis dette kartet ikke inneholder noen tilordning for nøkkelen.
- delete_val(nøkkel): Fjerner tilordningen for den spesifikke nøkkelen hvis hash-kartet inneholder tilordningen for nøkkelen.
Nedenfor er gjennomføringen.
Python3
tegn til int java
class> HashTable:> ># Create empty bucket list of given size> >def> __init__(>self>, size):> >self>.size>=> size> >self>.hash_table>=> self>.create_buckets()> >def> create_buckets(>self>):> >return> [[]>for> _>in> range>(>self>.size)]> ># Insert values into hash map> >def> set_val(>self>, key, val):> > ># Get the index from the key> ># using hash function> >hashed_key>=> hash>(key)>%> self>.size> > ># Get the bucket corresponding to index> >bucket>=> self>.hash_table[hashed_key]> >found_key>=> False> >for> index, record>in> enumerate>(bucket):> >record_key, record_val>=> record> > ># check if the bucket has same key as> ># the key to be inserted> >if> record_key>=>=> key:> >found_key>=> True> >break> ># If the bucket has same key as the key to be inserted,> ># Update the key value> ># Otherwise append the new key-value pair to the bucket> >if> found_key:> >bucket[index]>=> (key, val)> >else>:> >bucket.append((key, val))> ># Return searched value with specific key> >def> get_val(>self>, key):> > ># Get the index from the key using> ># hash function> >hashed_key>=> hash>(key)>%> self>.size> > ># Get the bucket corresponding to index> >bucket>=> self>.hash_table[hashed_key]> >found_key>=> False> >for> index, record>in> enumerate>(bucket):> >record_key, record_val>=> record> > ># check if the bucket has same key as> ># the key being searched> >if> record_key>=>=> key:> >found_key>=> True> >break> ># If the bucket has same key as the key being searched,> ># Return the value found> ># Otherwise indicate there was no record found> >if> found_key:> >return> record_val> >else>:> >return> 'No record found'> ># Remove a value with specific key> >def> delete_val(>self>, key):> > ># Get the index from the key using> ># hash function> >hashed_key>=> hash>(key)>%> self>.size> > ># Get the bucket corresponding to index> >bucket>=> self>.hash_table[hashed_key]> >found_key>=> False> >for> index, record>in> enumerate>(bucket):> >record_key, record_val>=> record> > ># check if the bucket has same key as> ># the key to be deleted> >if> record_key>=>=> key:> >found_key>=> True> >break> >if> found_key:> >bucket.pop(index)> >return> ># To print the items of hash map> >def> __str__(>self>):> >return> ''.join(>str>(item)>for> item>in> self>.hash_table)> hash_table>=> HashTable(>50>)> # insert some values> hash_table.set_val(>'[email protected]'>,>'some value'>)> print>(hash_table)> print>()> hash_table.set_val(>'[email protected]'>,>'some other value'>)> print>(hash_table)> print>()> # search/access a record with key> print>(hash_table.get_val(>'[email protected]'>))> print>()> # delete or remove a value> hash_table.delete_val(>'[email protected]'>)> print>(hash_table)> |
>
>
Produksjon:
ctc full form
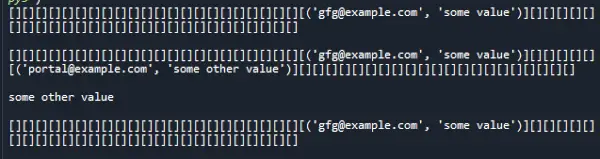
Tidskompleksitet:
round robin-planlegging
Tilgang til minneindeks tar konstant tid og hashing tar konstant tid. Derfor er søkekompleksiteten til et hash-kart også konstant tid, det vil si O(1).
Fordeler med HashMaps
● Rask tilfeldig minnetilgang gjennom hash-funksjoner
● Kan bruke negative og ikke-integrale verdier for å få tilgang til verdiene.
● Nøkler kan lagres i sortert rekkefølge og kan derfor enkelt iterere over kartene.
Ulemper med HashMaps
rad og kolonne
● Kollisjoner kan forårsake store straffer og kan sprenge tidskompleksiteten til lineær.
● Når antallet nøkler er stort, forårsaker en enkelt hash-funksjon ofte kollisjoner.
Applikasjoner av HashMaps
● Disse har applikasjoner i implementeringer av Cache der minneplasseringer er tilordnet til små sett.
● De brukes til å indeksere tupler i databasestyringssystemer.
● De brukes også i algoritmer som Rabin Karp-mønstertilpasning