Linux uniq-kommandoen brukes til å fjerne alle de gjentatte linjene fra en fil. Den kan også brukes til å vise et antall ord, bare gjentatte linjer, ignorere tegn og sammenligne spesifikke felt. Det er en av de mest brukte kommandoene i Linux system. Det brukes ofte sammen med sorteringskommando fordi den sammenligner tilstøtende tegn. Den forkaster alle de identiske linjene og skriver utdataene.
Syntaks:
uniq [OPTION]... [INPUT [OUTPUT]]
Alternativer:
Noen nyttige kommandolinjealternativer for uniq-kommandoen er som følger:
-c, --count: det prefikser linjene med antall forekomster.
-d, --gjentatt: den brukes til å skrive ut dupliserte linjer, en for hver gruppe.
-D: Den brukes til å skrive ut alle dupliserte linjene.
--all-gjentatt[=METHOD]: Det er ganske likt '-D'-alternativet, forskjellen mellom begge alternativene er at det tillater separasjon av grupper med en tom linje.
-f, --hopp over-felt=N: Den brukes for å unngå sammenligning av de første N-feltene.
--gruppe[=METODE]: Den brukes til å vise alle elementer og skiller gruppene med en tom linje.
-i, --ignore-case: Den brukes til å ignorere forskjellene mens du sammenligner.
-s, --skip-chars=N: Den brukes for å unngå sammenligning av de første N tegnene.
-u, --unik: den brukes til å skrive ut unike linjer.
-z, --null-terminert: Den brukes for linjeavgrenseren er NUL og ikke nylinjemodus.
-w, --check-chars=N: Den brukes til å sammenligne ikke mer enn N tegn i linjer.
--hjelp: Den brukes til å vise hjelpedokumentasjon.
--versjon: Den brukes til å vise versjonsinformasjonen.
Eksempler på uniq Command
La oss se følgende eksempler på uniq-kommandoen:
- Fjern gjentatte linjer
- telle antall forekomster av et ord
- Vis de gjentatte linjene
- Vis de unike linjene
- Ignorer tegn i sammenligning
- Ignorer felt i sammenligning
Fjern gjentatte linjer
For å fjerne gjentatte linjer fra en fil, kjør den grunnleggende uniq-kommandoen som følger:
solfylt deol alder
sort dupli.txt | uniq
Kommandoen ovenfor vil fjerne de dupliserte linjene fra filen 'dupli.txt.' Tenk på utgangen nedenfor:
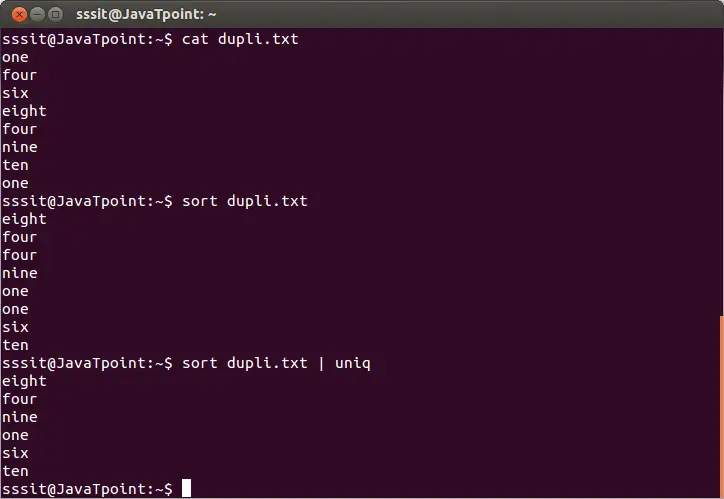
Fra utgangen ovenfor ignoreres de repeterende ordene.
Tell antall forekomster av et ord
Vi kan telle antall forekomster av et ord ved å bruke uniq-kommandoen. Alternativet '-c' brukes til å telle ordet. Utfør det som følger:
sort dupli.txt | uniq -c
Kommandoen ovenfor vil telle ordene som kommer i 'dupli.txt'. Tenk på utgangen nedenfor:

Fra utgangen ovenfor, kommandoen 'sort dupli.txt | uniq -c' teller antall ganger et ord gjentas.
Vis de gjentatte linjene
Alternativet '-d' brukes til å vise bare de gjentatte linjene. Den vil bare vise linjene som vil være mer enn én gang i en fil og skrive utdataene til standardutdata. Tenk på kommandoen nedenfor:
sort dupli.txt | uniq -d
Kommandoen ovenfor viser bare de gjentatte linjene. Tenk på utgangen nedenfor:

Vis de unike linjene
Alternativet '-u' brukes til å vise bare de unike linjene (som ikke gjentas). Den vil bare vise linjene som bare forekommer én gang og skrive resultatet til standardutdata. Tenk på kommandoen nedenfor:
sort dupli.txt | uniq -u
Kommandoen ovenfor viser bare de unike linjene fra filen 'dupli.txt'. Tenk på utgangen nedenfor:

Ignorer tegn i sammenligning
Alternativet '-s' brukes til å ignorere tegnene i sammenligning. Den vil ignorere det angitte antallet tegn og vise resultatet til standard utdata. Tenk på kommandoen nedenfor:
sort dupli.txt | uniq -s 2
Kommandoen ovenfor vil ignorere de to første tegnene i sammenligning fra filen 'dupli.txt'. Tenk på utgangen nedenfor:

Ignorer felt i sammenligning
Alternativet '-f' brukes til å ignorere feltene. Tenk på kommandoen nedenfor:
uniq -f 2 dupli2.txt
Kommandoen ovenfor vil ikke sammenligne de to første feltene fra filen 'dupli2.txt'. Tenk på utgangen nedenfor:

Fra utdataene ovenfor hoppes de to første feltene over, og resten av alle feltene sammenlignes fra filen 'dupli2.txt'.