Logistisk regresjon i R-programmering er en klassifiseringsalgoritme som brukes til å finne sannsynligheten for suksess og hendelsesfeil. Logistisk regresjon brukes når den avhengige variabelen er binær (0/1, True/False, Yes/No) i naturen. Logit-funksjonen brukes som en lenkefunksjon i en binomialfordeling.
En binær utfallsvariabels sannsynlighet kan forutsies ved å bruke den statistiske modelleringsteknikken kjent som logistisk regresjon. Det er mye ansatt i mange forskjellige bransjer, inkludert markedsføring, finans, samfunnsvitenskap og medisinsk forskning.
Den logistiske funksjonen, ofte referert til som sigmoid-funksjonen, er den grunnleggende ideen som ligger til grunn for logistisk regresjon. Denne sigmoidfunksjonen brukes i logistisk regresjon for å beskrive korrelasjonen mellom prediktorvariablene og sannsynligheten for det binære utfallet.

Logistisk regresjon i R-programmering
Logistisk regresjon er også kjent som Binomial logistikkregresjon . Den er basert på sigmoid-funksjonen der utgang er sannsynlighet og input kan være fra -uendelig til +uendelig.
Teori
Logistikkregresjon er også kjent som en generalisert lineær modell. Siden den brukes som en klassifiseringsteknikk for å forutsi en kvalitativ respons, varierer verdien av y fra 0 til 1 og kan representeres av følgende ligning:
Logistisk regresjon i R-programmering
s er sannsynligheten for karakteristikk av interesse. Oddsforholdet er definert som sannsynligheten for suksess sammenlignet med sannsynligheten for fiasko. Det er en nøkkelrepresentasjon av logistiske regresjonskoeffisienter og kan ta verdier mellom 0 og uendelig. Oddsforholdet 1 er når sannsynligheten for suksess er lik sannsynligheten for å mislykkes. Oddsforholdet 2 er når sannsynligheten for suksess er dobbelt så stor som sannsynligheten for å mislykkes. Oddsforholdet på 0,5 er når sannsynligheten for å mislykkes er to ganger sannsynligheten for suksess.
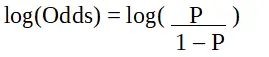
Logistisk regresjon i R-programmering
Siden vi jobber med en binomialfordeling (avhengig variabel), må vi velge en lenkefunksjon som er best egnet for denne fordelingen.
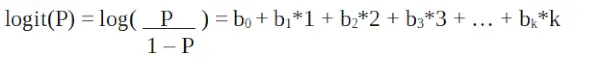
Logistisk regresjon i R-programmering
Det er en logit funksjon . I ligningen ovenfor er parentesen valgt for å maksimere sannsynligheten for å observere prøveverdiene i stedet for å minimere summen av kvadrerte feil (som vanlig regresjon). Logitten er også kjent som en logg over odds. Logit-funksjonen må være lineært relatert til de uavhengige variablene. Dette er fra ligning A, der venstre side er en lineær kombinasjon av x. Dette ligner på OLS-antakelsen om at y er lineært relatert til x. Variablene b0, b1, b2 … osv. er ukjente og må estimeres på tilgjengelig treningsdata. I en logistisk regresjonsmodell, multipliserer b1 med én enhet, endres logiten med b0. P-endringene på grunn av en endring på én enhet vil avhenge av verdien multiplisert. Hvis b1 er positiv, vil P øke og hvis b1 er negativ, vil P avta.
Datasettet
mtcars (motortrend bilveitest) omfatter drivstofforbruk, ytelse og 10 aspekter ved bildesign for 32 biler. Den leveres forhåndsinstallert med dplyr pakke i R.
R
# Installing the package> install.packages>(>'dplyr'>)> # Loading package> library>(dplyr)> # Summary of dataset in package> summary>(mtcars)> |
>
>
Utføre logistisk regresjon på et datasett
Logistisk regresjon implementeres i R vha glm() ved å trene modellen ved å bruke funksjoner eller variabler i datasettet.
R
# Installing the package> # For Logistic regression> install.packages>(>'caTools'>)> # For ROC curve to evaluate model> install.packages>(>'ROCR'>)> > # Loading package> library>(caTools)> library>(ROCR)> |
>
>
Splitting av data
R
# Splitting dataset> split <->sample.split>(mtcars, SplitRatio = 0.8)> split> train_reg <->subset>(mtcars, split ==>'TRUE'>)> test_reg <->subset>(mtcars, split ==>'FALSE'>)> # Training model> logistic_model <->glm>(vs ~ wt + disp,> >data = train_reg,> >family =>'binomial'>)> logistic_model> # Summary> summary>(logistic_model)> |
>
>
Produksjon:
Call: glm(formula = vs ~ wt + disp, family = 'binomial', data = train_reg) Deviance Residuals: Min 1Q Median 3Q Max -1.6552 -0.4051 0.4446 0.6180 1.9191 Coefficients: Estimate Std. Error z value Pr(>|z|) (avskjæring) 1,58781 2,60087 0,610 0,5415 vekt 1,36958 1,60524 0,853 0,3936 disp -0,02969 0,01577 -1,882 0,0577 -1,898 0. --- Signif. koder: 0 '***' 0,001 '**' 0,01 '*' 0,05 '.' 0,1 ' ' 1 (Spredningsparameter for binomial familie tatt til å være 1) Nullavvik: 34,617 på 24 frihetsgrader Restavvik: 20,212 på 22 frihetsgrader AIC: 26.212 Antall Fisher Scoring-iterasjoner: 6>
- Anrop: Funksjonskallet som brukes for å passe til den logistiske regresjonsmodellen vises, sammen med informasjon om familien, formelen og dataene. Avviksrester: Dette er avviksrestene, som måler modellens grad av god passform. De står for avvik mellom faktiske svar og sannsynlighet forutsagt av den logistiske regresjonsmodellen. Koeffisienter: Disse koeffisientene i logistisk regresjon representerer responsvariabelens loggodds eller logit. Standardfeilene knyttet til de estimerte koeffisientene er vist i Std. Feilkolonne. Signifikanskoder: Signifikansnivået til hver prediktorvariabel indikeres av signifikanskodene. Dispersjonsparameter: I logistisk regresjon fungerer dispersjonsparameteren som skaleringsparameter for binomialfordelingen. Den er satt til 1 i dette tilfellet, noe som indikerer at den antatte spredningen er 1. Nullavvik: Nullavviket beregner modellens avvik når bare avskjæringen tas i betraktning. Det symboliserer avviket som ville følge av en modell uten prediktorer. Restavvik: Residualavviket beregner modellens avvik etter at prediktorene er tilpasset. Det står for gjenværende avvik etter å ha tatt hensyn til prediktorene. AIC: Akaike Information Criterion (AIC), som står for antall prediktorer, er et mål på en modells god passform. Det straffer mer intrikate modeller for å forhindre overmontering. Bedre tilpassede modeller er indikert med lavere AIC-verdier. Antall iterasjoner av Fisher-scoring: Antall iterasjoner som kreves av Fisher-scoringsprosedyren for å estimere modellparametrene, indikeres av antall iterasjoner.
Forutsi testdata basert på modell
R
predict_reg <->predict>(logistic_model,> >test_reg, type =>'response'>)> predict_reg> |
>
>
Produksjon:
Hornet Sportabout Merc 280C Merc 450SE Chrysler Imperial 0.01226166 0.78972164 0.26380531 0.01544309 AMC Javelin Camaro Z28 Ford Pantera L 0.06104267 0.02807992 0.01107943>
R
# Changing probabilities> predict_reg <->ifelse>(predict_reg>0,5, 1, 0)> # Evaluating model accuracy> # using confusion matrix> table>(test_reg$vs, predict_reg)> missing_classerr <->mean>(predict_reg != test_reg$vs)> print>(>paste>(>'Accuracy ='>, 1 - missing_classerr))> # ROC-AUC Curve> ROCPred <->prediction>(predict_reg, test_reg$vs)> ROCPer <->performance>(ROCPred, measure =>'tpr'>,> >x.measure =>'fpr'>)> auc <->performance>(ROCPred, measure =>'auc'>)> auc <- [email protected][[1]]> auc> # Plotting curve> plot>(ROCPer)> plot>(ROCPer, colorize =>TRUE>,> >print.cutoffs.at =>seq>(0.1, by = 0.1),> >main =>'ROC CURVE'>)> abline>(a = 0, b = 1)> auc <->round>(auc, 4)> legend>(.6, .4, auc, title =>'AUC'>, cex = 1)> |
>
>
Produksjon:
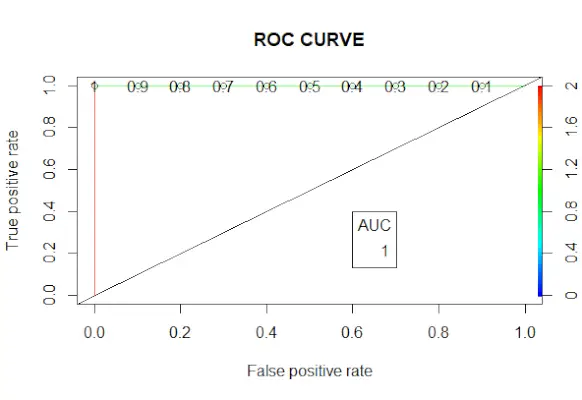
ROC-kurve
Eksempel 2:
Vi kan utføre en logistisk regresjonsmodell Titanic Datasett i R.
R
js global variabel
# Load the dataset> data>(Titanic)> # Convert the table to a data frame> data <->as.data.frame>(Titanic)> # Fit the logistic regression model> model <->glm>(Survived ~ Class + Sex + Age, family = binomial, data = data)> # View the summary of the model> summary>(model)> |
>
>
Produksjon:
Call: glm(formula = Survived ~ Class + Sex + Age, family = binomial, data = data) Deviance Residuals: Min 1Q Median 3Q Max -1.177 -1.177 0.000 1.177 1.177 Coefficients: Estimate Std. Error z value Pr(>|z|) (avskjæring) 4.022e-16 8.660e-01 0 1 Class2nd -9.762e-16 1.000e+00 0 1 Class3rd -4.699e-16 1.000e+00 0 1 ClassCrew -5.651e. 00 0 1 Kjønn Kvinne -3.140e-16 7.071e-01 0 1 AlderVoksen 5.103e-16 7.071e-01 0 1 (Spredningsparameter for binomial familie tatt til å være 1) Nullavvik: 44.361 på 31 frihetsgrader Res. på 26 frihetsgrader AIC: 56.361 Antall Fisher Scoring-iterasjoner: 2>
Plott ROC-kurven for Titanic-datasettet
R
# Install and load the required packages> install.packages>(>'ROCR'>)> library>(ROCR)> # Fit the logistic regression model> model <->glm>(Survived ~ Class + Sex + Age, family = binomial, data = data)> # Make predictions on the dataset> predictions <->predict>(model, type =>'response'>)> # Create a prediction object for ROCR> prediction_objects <->prediction>(predictions, titanic_df$Survived)> # Create an ROC curve object> roc_object <->performance>(prediction_obj, measure =>'tpr'>, x.measure =>'fpr'>)> # Plot the ROC curve> plot>(roc_object, main =>'ROC Curve'>, col =>'blue'>, lwd = 2)> # Add labels and a legend to the plot> legend>(>'bottomright'>, legend => >paste>(>'AUC ='>,>round>(>performance>(prediction_objects, measure =>'auc'>)> >@y.values[[1]], 2)), col =>'blue'>, lwd = 2)> |
>
>
Produksjon:
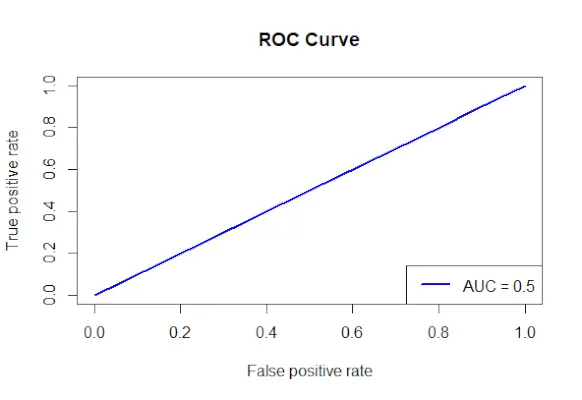
ROC-kurve
- Faktorene som brukes til å forutsi Overlevd er spesifisert, og formelen Overlevd Klasse + Kjønn + Alder brukes til å lage en logistisk regresjonsmodell.
- Ved å bruke predict()-funksjonen lages prediksjoner på datasettet ved å bruke den tilpassede modellen.
- De projiserte sannsynlighetene kombineres med de faktiske utfallsverdiene for å bygge et prediksjonsobjekt ved å bruke prediksjon()-metoden fra ROCR-pakken.
- Målingen av den sanne positive hastigheten (tpr) og x-aksen for den falske positive hastigheten (fpr) er spesifisert, og et ROC-kurveobjekt opprettes ved å bruke funksjonen ytelse() fra ROCR-pakken.
- ROC-kurveobjektet (roc_obj), som spesifiserer hovedtittelen, fargen og linjebredden, plottes ved hjelp av plot()-funksjonen.
- Den bruker funksjonen ytelse() med måle = auc for å bestemme AUC-verdien (området under kurven) og legger til etiketter og en forklaring til plottet.