Kvantilkvantil (q-q plot) plot er en grafisk metode for å bestemme om et datasett følger en viss sannsynlighetsfordeling eller om to utvalg av data kom fra samme befolkning eller ikke. Q-Q plott er spesielt nyttige for å vurdere om et datasett er normalt fordelt eller hvis den følger en annen kjent distribusjon. De brukes ofte i statistikk, dataanalyse og kvalitetskontroll for å sjekke forutsetninger og identifisere avvik fra forventede distribusjoner.
Kvantiler og prosentiler
Kvantiler er punkter i et datasett som deler dataene inn i intervaller som inneholder like sannsynligheter eller proporsjoner av den totale fordelingen. De brukes ofte til å beskrive spredningen eller distribusjonen av et datasett. De vanligste kvantilene er:
- Median (50. persentil) : Medianen er den midterste verdien av et datasett når det er sortert fra minste til største. Den deler datasettet i to like halvdeler.
- Kvartiler (25., 50. og 75. persentil) : Kvartiler deler datasettet i fire like deler. Den første kvartilen (Q1) er verdien som 25 % av dataene faller under, den andre kvartilen (Q2) er medianen, og den tredje kvartilen (Q3) er verdien som 75 % av dataene faller under.
- Persentiler : Persentiler ligner kvartiler, men deler datasettet i 100 like deler. For eksempel er 90. persentilen verdien som 90 % av dataene faller under.
Merk:
- Et q-q-plott er et plott av kvantilene til det første datasettet mot kvantilene til det andre datasettet.
- For referanseformål er det også plottet en 45 % linje; Til hvis prøvene er fra samme populasjon, er punktene langs denne linjen.
Normal distribusjon:
Normalfordelingen (også kalt Gaussisk distribusjon Bell-kurve) er en kontinuerlig sannsynlighetsfordeling som representerer distribusjon oppnådd fra de tilfeldig genererte reelle verdiene.
. 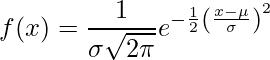

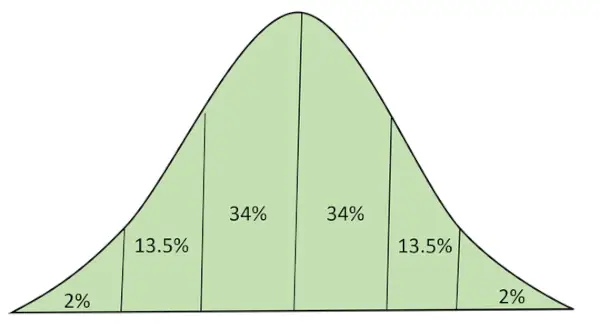
Normalfordeling med areal under kurve
Hvordan tegne Q-Q plot?
For å tegne et Quantile-Quantile (Q-Q) plot, kan du følge disse trinnene:
- Samle inn dataene : Samle datasettet du vil lage Q-Q-plotten for. Sørg for at dataene er numeriske og representerer et tilfeldig utvalg fra populasjonen av interesse.
- Sorter dataene : Ordne dataene i enten stigende eller synkende rekkefølge. Dette trinnet er avgjørende for å beregne kvantiler nøyaktig.
- Velg en teoretisk fordeling : Bestem den teoretiske fordelingen du vil sammenligne datasettet ditt mot. Vanlige valg inkluderer normalfordeling, eksponentiell distribusjon eller annen distribusjon som passer dataene dine godt.
- Beregn teoretiske kvantiler : Regn ut kvantilene for den valgte teoretiske fordelingen. For eksempel, hvis du sammenligner med en normalfordeling, vil du bruke den inverse kumulative distribusjonsfunksjonen (CDF) til normalfordelingen for å finne de forventede kvantilene.
- Plotte :
- Plott de sorterte datasettverdiene på x-aksen.
- Plott de tilsvarende teoretiske kvantilene på y-aksen.
- Hvert datapunkt (x, y) representerer et par observerte og forventede verdier.
- Koble sammen datapunktene for å visuelt inspisere forholdet mellom datasettet og den teoretiske distribusjonen.
Tolkning av Q-Q plot
- Hvis punktene på plottet faller omtrent langs en rett linje, antyder det at datasettet ditt følger den antatte fordelingen.
- Avvik fra rett linje indikerer avvik fra antatt fordeling, som krever nærmere undersøkelse.
Utforsker distribusjonslikhet med Q-Q-plotter
Å utforske distribusjonslikhet ved å bruke Q-Q-plott er en grunnleggende oppgave i statistikk. Å sammenligne to datasett for å finne ut om de stammer fra samme distribusjon er avgjørende for ulike analytiske formål. Når antakelsen om en felles fordeling holder, kan sammenslåing av datasett forbedre parameterestimeringsnøyaktigheten, for eksempel for plassering og skala. Q-Q plott, forkortelse for quantile-quantile plots, tilbyr en visuell metode for å vurdere distribusjonslikhet. I disse plottene plottes kvantiler fra ett datasett mot kvantiler fra et annet. Hvis punktene er tett på linje langs en diagonal linje, antyder det likhet mellom fordelingene. Avvik fra denne diagonale linjen indikerer forskjeller i fordelingsegenskaper.
Mens tester som chi-kvadrat og Kolmogorov-Smirnov tester kan evaluere generelle distribusjonsforskjeller, Q-Q plott gir et nyansert perspektiv ved direkte å sammenligne kvantiler. Dette gjør det mulig for analytikere å skjelne spesifikke forskjeller, for eksempel endringer i plassering eller endringer i skala, som kanskje ikke er tydelig fra formelle statistiske tester alene.
Python-implementering av Q-Q-plott
Python3
import> numpy as np> import> matplotlib.pyplot as plt> import> scipy.stats as stats> # Generate example data> np.random.seed(>0>)> data>=> np.random.normal(loc>=>0>, scale>=>1>, size>=>1000>)> # Create Q-Q plot> stats.probplot(data, dist>=>'norm'>, plot>=>plt)> plt.title(>'Normal Q-Q plot'>)> plt.xlabel(>'Theoretical quantiles'>)> plt.ylabel(>'Ordered Values'>)> plt.grid(>True>)> plt.show()> |
>
>
Produksjon:
Q-Q plot
Her, ettersom datapunktene omtrent følger en rett linje i Q-Q plottet, tyder det på at datasettet stemmer overens med den antatte teoretiske fordelingen, som vi i dette tilfellet antok å være normalfordelingen.
Fordeler med Q-Q plot
- Fleksibel sammenligning : Q-Q plott kan sammenligne datasett av forskjellige størrelser uten krever like utvalgsstørrelser.
- Dimensjonsløs analyse : De er dimensjonsløse, noe som gjør dem egnet til å sammenligne datasett med forskjellige enheter eller skalaer.
- Visuell tolkning : Gir en klar visuell representasjon av datadistribusjon sammenlignet med en teoretisk distribusjon.
- Følsom for avvik : Oppdager enkelt avvik fra antatte distribusjoner, og hjelper til med å identifisere dataavvik.
- Diagnoseverktøy : Hjelper med å vurdere fordelingsantakelser, identifisere uteliggere og forstå datamønstre.
Anvendelser av kvantil-kvantile plot
Kvantilkvantil-plottet brukes til følgende formål:
- Vurdere distribusjonsforutsetninger : Q-Q plott brukes ofte til å visuelt inspisere om et datasett følger en spesifikk sannsynlighetsfordeling, for eksempel normalfordelingen. Ved å sammenligne kvantilene til de observerte dataene med kvantilene til den antatte fordelingen, kan avvik fra den antatte fordelingen oppdages. Dette er avgjørende i mange statistiske analyser, der gyldigheten av fordelingsantakelser påvirker nøyaktigheten av statistiske slutninger.
- Oppdage uteliggere : Outliers er datapunkter som avviker betydelig fra resten av datasettet. Q-Q-plott kan hjelpe med å identifisere uteliggere ved å avsløre datapunkter som faller langt fra det forventede mønsteret for distribusjonen. Outliers kan vises som punkter som avviker fra forventet rette linje i plottet.
- Sammenligning av distribusjoner : Q-Q plott kan brukes til å sammenligne to datasett for å se om de kommer fra samme distribusjon. Dette oppnås ved å plotte kvantilene til ett datasett mot kvantilene til et annet datasett. Hvis punktene faller omtrent langs en rett linje, antyder det at de to datasettene er trukket fra samme fordeling.
- Vurdere normalitet : Q-Q plott er spesielt nyttige for å vurdere normaliteten til et datasett. Hvis datapunktene i plottet følger en rett linje tett, indikerer det at datasettet er tilnærmet normalfordelt. Avvik fra linjen tyder på avvik fra normaliteten, noe som kan kreve ytterligere undersøkelser eller ikke-parametriske statistiske teknikker.
- Modellvalidering : I felt som økonometri og maskinlæring brukes Q-Q-plott for å validere prediktive modeller. Ved å sammenligne kvantilene av observerte responser med kvantilene predikert av en modell, kan man vurdere hvor godt modellen passer til dataene. Avvik fra forventet mønster kan indikere områder hvor modellen trenger forbedring.
- Kvalitetskontroll : Q-Q-plott brukes i kvalitetskontrollprosesser for å overvåke fordelingen av målte eller observerte verdier over tid eller på tvers av forskjellige batcher. Avvik fra forventede mønstre i plottet kan signalisere endringer i de underliggende prosessene, noe som gir anledning til ytterligere undersøkelser.
Typer Q-Q plott
Det er flere typer Q-Q-plott som vanligvis brukes i statistikk og dataanalyse, hver egnet for forskjellige scenarier eller formål:
- Normal distribusjon : En symmetrisk fordeling der Q-Q plottet vil vise punkter omtrent langs en diagonal linje hvis dataene holder seg til en normalfordeling.
- Høyreskjev fordeling : En fordeling der Q-Q plottet vil vise et mønster der de observerte kvantilene avviker fra den rette linjen mot den øvre enden, noe som indikerer en lengre hale på høyre side.
- Venstreskjev fordeling : En fordeling der Q-Q plottet vil vise et mønster der de observerte kvantilene avviker fra den rette linjen mot den nedre enden, noe som indikerer en lengre hale på venstre side.
- Underspredt distribusjon : En fordeling der Q-Q plottet ville vise observerte kvantiler gruppert tettere rundt diagonallinjen sammenlignet med de teoretiske kvantilene, noe som tyder på lavere varians.
- Overspredt distribusjon : En fordeling der Q-Q-plotten vil vise observerte kvantiler mer spredt eller avvikende fra den diagonale linjen, noe som indikerer høyere varians eller spredning sammenlignet med den teoretiske fordelingen.
Python3
import> numpy as np> import> matplotlib.pyplot as plt> import> scipy.stats as stats> # Generate a random sample from a normal distribution> normal_data>=> np.random.normal(loc>=>0>, scale>=>1>, size>=>1000>)> # Generate a random sample from a right-skewed distribution (exponential distribution)> right_skewed_data>=> np.random.exponential(scale>=>1>, size>=>1000>)> # Generate a random sample from a left-skewed distribution (negative exponential distribution)> left_skewed_data>=> ->np.random.exponential(scale>=>1>, size>=>1000>)> # Generate a random sample from an under-dispersed distribution (truncated normal distribution)> under_dispersed_data>=> np.random.normal(loc>=>0>, scale>=>0.5>, size>=>1000>)> under_dispersed_data>=> under_dispersed_data[(under_dispersed_data>>->1>) & (under_dispersed_data <>1>)]># Truncate> # Generate a random sample from an over-dispersed distribution (mixture of normals)> over_dispersed_data>=> np.concatenate((np.random.normal(loc>=>->2>, scale>=>1>, size>=>500>),> >np.random.normal(loc>=>2>, scale>=>1>, size>=>500>)))> # Create Q-Q plots> plt.figure(figsize>=>(>15>,>10>))> plt.subplot(>2>,>3>,>1>)> stats.probplot(normal_data, dist>=>'norm'>, plot>=>plt)> plt.title(>'Q-Q Plot - Normal Distribution'>)> plt.subplot(>2>,>3>,>2>)> stats.probplot(right_skewed_data, dist>=>'expon'>, plot>=>plt)> plt.title(>'Q-Q Plot - Right-skewed Distribution'>)> plt.subplot(>2>,>3>,>3>)> stats.probplot(left_skewed_data, dist>=>'expon'>, plot>=>plt)> plt.title(>'Q-Q Plot - Left-skewed Distribution'>)> plt.subplot(>2>,>3>,>4>)> stats.probplot(under_dispersed_data, dist>=>'norm'>, plot>=>plt)> plt.title(>'Q-Q Plot - Under-dispersed Distribution'>)> plt.subplot(>2>,>3>,>5>)> stats.probplot(over_dispersed_data, dist>=>'norm'>, plot>=>plt)> plt.title(>'Q-Q Plot - Over-dispersed Distribution'>)> plt.tight_layout()> plt.show()> |
>
>
Produksjon:
Q-Q plot for ulike distribusjoner
chown kommando