Regresjons- og klassifiseringsalgoritmer er overvåket læringsalgoritmer. Begge algoritmene brukes til prediksjon i maskinlæring og arbeider med de merkede datasettene. Men forskjellen mellom begge er hvordan de brukes til forskjellige maskinlæringsproblemer.
Hovedforskjellen mellom regresjons- og klassifikasjonsalgoritmer som regresjonsalgoritmer er vant til forutsi det kontinuerlige verdier som pris, lønn, alder osv. og Klassifikasjonsalgoritmer brukes til forutsi/klassifiser de diskrete verdiene for eksempel mann eller kvinne, sant eller usant, spam eller ikke spam, etc.
Tenk på diagrammet nedenfor:
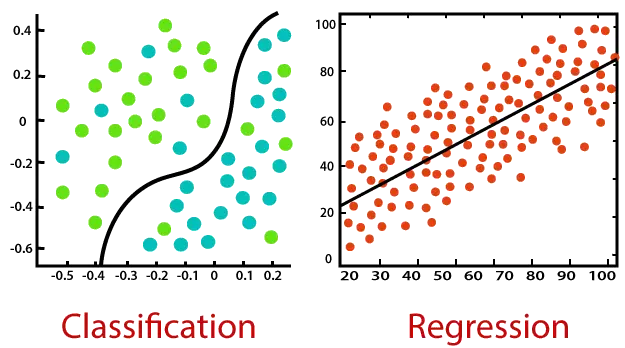
Klassifisering:
Klassifisering er en prosess for å finne en funksjon som hjelper til med å dele opp datasettet i klasser basert på forskjellige parametere. I Klassifisering trenes et dataprogram på opplæringsdatasettet, og basert på den opplæringen kategoriserer det dataene i forskjellige klasser.
Klassifiseringsalgoritmens oppgave er å finne kartleggingsfunksjonen for å kartlegge inngangen(x) til den diskrete utgangen(y).
Eksempel: Det beste eksemplet for å forstå klassifiseringsproblemet er e-postoppdagelse av søppelpost. Modellen er trent på grunnlag av millioner av e-poster på ulike parametere, og hver gang den mottar en ny e-post, identifiserer den om e-posten er spam eller ikke. Hvis e-posten er spam, flyttes den til Spam-mappen.
Typer ML-klassifiseringsalgoritmer:
Klassifiseringsalgoritmer kan videre deles inn i følgende typer:
eksempel på delstreng i java
- Logistisk regresjon
- K-Nærmeste Naboer
- Støtte vektormaskiner
- Kjerne SVM
- Nave Bayes
- Klassifisering av beslutningstre
- Tilfeldig skogklassifisering
Regresjon:
Regresjon er en prosess for å finne sammenhengen mellom avhengige og uavhengige variabler. Det hjelper med å forutsi de kontinuerlige variablene som prediksjon av Markedstrender , prediksjon av boligpriser, etc.
Oppgaven til regresjonsalgoritmen er å finne kartleggingsfunksjonen for å kartlegge inngangsvariabelen(x) til den kontinuerlige utdatavariabelen(y).
Eksempel: Anta at vi ønsker å gjøre værvarsling, så for dette vil vi bruke regresjonsalgoritmen. I værprediksjon trenes modellen på tidligere data, og når treningen er fullført, kan den enkelt forutsi været for fremtidige dager.
Typer regresjonsalgoritme:
- Enkel lineær regresjon
- Multippel lineær regresjon
- Polynomregresjon
- Støtt vektorregresjon
- Regresjon av beslutningstre
- Tilfeldig skogregresjon
Forskjellen mellom regresjon og klassifisering
| Regresjonsalgoritme | Klassifiseringsalgoritme |
|---|---|
| I regresjon må utdatavariabelen være av kontinuerlig natur eller reell verdi. | I klassifisering må utgangsvariabelen være en diskret verdi. |
| Oppgaven til regresjonsalgoritmen er å kartlegge inngangsverdien (x) med den kontinuerlige utdatavariabelen (y). | Klassifiseringsalgoritmens oppgave er å kartlegge inngangsverdien(x) med den diskrete utdatavariabelen(y). |
| Regresjonsalgoritmer brukes med kontinuerlige data. | Klassifiseringsalgoritmer brukes med diskrete data. |
| I regresjon prøver vi å finne den beste tilpasningslinjen, som kan forutsi utgangen mer nøyaktig. | I Klassifikasjon prøver vi å finne beslutningsgrensen, som kan dele opp datasettet i ulike klasser. |
| Regresjonsalgoritmer kan brukes til å løse regresjonsproblemene som værprediksjon, boligprisprediksjon, etc. | Klassifiseringsalgoritmer kan brukes til å løse klassifiseringsproblemer som identifisering av spam-e-poster, talegjenkjenning, identifisering av kreftceller, etc. |
| Regresjonsalgoritmen kan videre deles inn i lineær og ikke-lineær regresjon. | Klassifikasjonsalgoritmene kan deles inn i binær klassifisering og multiklasseklassifisering. |