Maskinlæring er grenen av Kunstig intelligens som fokuserer på å utvikle modeller og algoritmer som lar datamaskiner lære av data og forbedre seg fra tidligere erfaringer uten å være eksplisitt programmert for hver oppgave. Med enkle ord lærer ML systemene å tenke og forstå som mennesker ved å lære av dataene.
I denne artikkelen skal vi utforske de ulike typer av maskinlæringsalgoritmer som er viktige for fremtidige krav. Maskinlæring er generelt et treningssystem for å lære av tidligere erfaringer og forbedre ytelsen over tid. Maskinlæring hjelper til med å forutsi enorme mengder data. Det hjelper å levere raske og nøyaktige resultater for å få lønnsomme muligheter.
Typer maskinlæring
Det finnes flere typer maskinlæring, hver med spesielle egenskaper og applikasjoner. Noen av hovedtypene for maskinlæringsalgoritmer er som følger:
- Veiledet maskinlæring
- Maskinlæring uten tilsyn
- Semi-overvåket maskinlæring
- Forsterkende læring
Typer maskinlæring
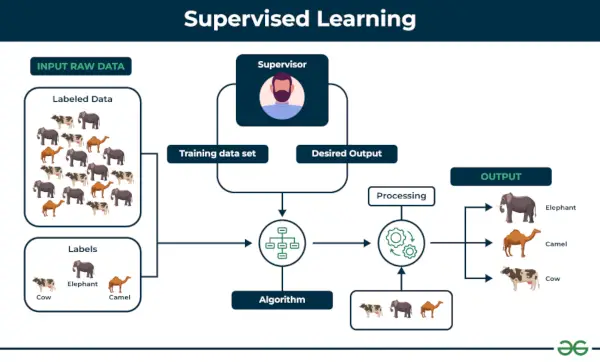
1. Overvåket maskinlæring
Veiledet læring er definert som når en modell blir trent på en Merket datasett . Merkede datasett har både inngangs- og utdataparametere. I Veiledet læring Algoritmer lærer å kartlegge punkter mellom innganger og riktige utganger. Den har både opplærings- og valideringsdatasett merket.
Veiledet læring
La oss forstå det ved hjelp av et eksempel.
Eksempel: Tenk på et scenario der du må bygge en bildeklassifiserer for å skille mellom katter og hunder. Hvis du mater datasettene av hunder og katter merkede bilder til algoritmen, vil maskinen lære å klassifisere mellom en hund eller en katt fra disse merkede bildene. Når vi legger inn nye hunde- eller kattebilder som den aldri har sett før, vil den bruke de innlærte algoritmene og forutsi om det er en hund eller en katt. Dette er hvordan veiledet læring fungerer, og dette er spesielt en bildeklassifisering.
Det er to hovedkategorier av veiledet læring som er nevnt nedenfor:
- Klassifisering
- Regresjon
Klassifisering
Klassifisering handler om å forutsi kategorisk målvariabler, som representerer diskrete klasser eller etiketter. For eksempel å klassifisere e-poster som spam eller ikke spam, eller forutsi om en pasient har høy risiko for hjertesykdom. Klassifiseringsalgoritmer lærer å kartlegge inngangsfunksjonene til en av de forhåndsdefinerte klassene.
Her er noen klassifiseringsalgoritmer:
- Logistisk regresjon
- Støtte Vector Machine
- Tilfeldig skog
- Beslutningstre
- K-Nærmeste Naboer (KNN)
- Naiv Bayes
Regresjon
Regresjon , derimot, omhandler å forutsi kontinuerlige målvariabler, som representerer numeriske verdier. For eksempel å forutsi prisen på et hus basert på størrelse, beliggenhet og fasiliteter, eller forutsi salget av et produkt. Regresjonsalgoritmer lærer å kartlegge inndatafunksjonene til en kontinuerlig numerisk verdi.
Her er noen regresjonsalgoritmer:
- Lineær regresjon
- Polynomregresjon
- Ridge regresjon
- Lasso-regresjon
- Beslutningstre
- Tilfeldig skog
Fordeler med overvåket maskinlæring
- Veiledet læring modeller kan ha høy nøyaktighet ettersom de er trent på merkede data .
- Beslutningsprosessen i veiledede læringsmodeller er ofte tolkbar.
- Den kan ofte brukes i ferdigtrente modeller som sparer tid og ressurser ved utvikling av nye modeller fra bunnen av.
Ulemper med overvåket maskinlæring
- Den har begrensninger i å kjenne mønstre og kan slite med usynlige eller uventede mønstre som ikke er tilstede i treningsdataene.
- Det kan være tidkrevende og kostbart som det er avhengig av merket kun data.
- Det kan føre til dårlige generaliseringer basert på nye data.
Anvendelser av veiledet læring
Veiledet læring brukes i en lang rekke applikasjoner, inkludert:
- Bildeklassifisering : Identifiser objekter, ansikter og andre funksjoner i bilder.
- Naturlig språkbehandling: Trekk ut informasjon fra tekst, for eksempel følelser, enheter og relasjoner.
- Talegjenkjenning : Konverter talespråk til tekst.
- Anbefalingssystemer : Lag personlige anbefalinger til brukere.
- Prediktiv analyse : Forutsi utfall, som salg, kundeavgang og aksjekurser.
- Medisinsk diagnose : Oppdag sykdommer og andre medisinske tilstander.
- Oppdagelse av svindel : Identifiser uredelige transaksjoner.
- Autonome kjøretøy : Gjenkjenne og reagere på objekter i miljøet.
- Deteksjon av spam via e-post : Klassifiser e-poster som spam eller ikke spam.
- Kvalitetskontroll i produksjon : Inspiser produktene for defekter.
- Kredittscoring : Vurder risikoen for at en låntaker misligholder et lån.
- Gaming : Gjenkjenne karakterer, analyser spilleratferd og lag NPC-er.
- Kundeservice : Automatiser kundestøtteoppgaver.
- Værmelding : Gjør spådommer for temperatur, nedbør og andre meteorologiske parametere.
- Sportsanalyse : Analyser spillerens ytelse, lag spillspådommer og optimaliser strategier.
2. Maskinlæring uten tilsyn
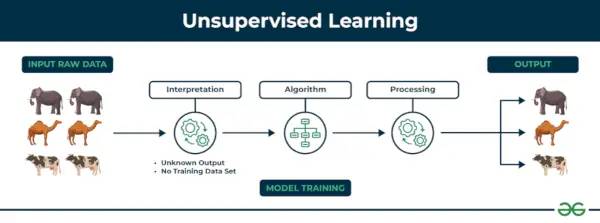
Uovervåket læring Uovervåket læring er en type maskinlæringsteknikk der en algoritme oppdager mønstre og relasjoner ved å bruke umerkede data. I motsetning til overvåket læring, innebærer ikke uovervåket læring å gi algoritmen merkede målutganger. Det primære målet med uovervåket læring er ofte å oppdage skjulte mønstre, likheter eller klynger i dataene, som deretter kan brukes til ulike formål, for eksempel datautforskning, visualisering, dimensjonalitetsreduksjon og mer.
Uovervåket læring
La oss forstå det ved hjelp av et eksempel.
Eksempel: Tenk på at du har et datasett som inneholder informasjon om kjøpene du har gjort fra butikken. Gjennom clustering kan algoritmen gruppere den samme kjøpsatferden blant deg og andre kunder, noe som avslører potensielle kunder uten forhåndsdefinerte etiketter. Denne typen informasjon kan hjelpe bedrifter med å få målkunder samt identifisere avvikere.
Det er to hovedkategorier av uovervåket læring som er nevnt nedenfor:
- Gruppering
- assosiasjon
Gruppering
Gruppering er prosessen med å gruppere datapunkter i klynger basert på deres likhet. Denne teknikken er nyttig for å identifisere mønstre og relasjoner i data uten behov for merkede eksempler.
Her er noen klyngealgoritmer:
- K-Means Clustering-algoritme
- Mean-shift algoritme
- DBSCAN-algoritme
- Hovedkomponentanalyse
- Uavhengig komponentanalyse
assosiasjon
Association regel lære ing er en teknikk for å oppdage relasjoner mellom elementer i et datasett. Den identifiserer regler som indikerer tilstedeværelsen av ett element, innebærer tilstedeværelsen av et annet element med en spesifikk sannsynlighet.
Her er noen assosiasjonsregellæringsalgoritmer:
- Apriori-algoritme
- Gløde
- FP-vekstalgoritme
Fordeler med uovervåket maskinlæring
- Det hjelper å oppdage skjulte mønstre og ulike relasjoner mellom dataene.
- Brukes til oppgaver som f.eks kundesegmentering, oppdagelse av avvik, og datautforskning .
- Det krever ikke merkede data og reduserer innsatsen med datamerking.
Ulemper ved uovervåket maskinlæring
- Uten å bruke etiketter kan det være vanskelig å forutsi kvaliteten på modellens produksjon.
- Klyngetolkbarhet er kanskje ikke tydelig og har kanskje ikke meningsfulle tolkninger.
- Den har teknikker som f.eks autoenkodere og dimensjonalitetsreduksjon som kan brukes til å trekke ut meningsfulle funksjoner fra rådata.
Anvendelser av uovervåket læring
Her er noen vanlige bruksområder for uovervåket læring:
- Gruppering : Grupper lignende datapunkter i klynger.
- Anomalideteksjon : Identifiser uteliggere eller anomalier i data.
- Dimensjonsreduksjon : Reduser dimensjonaliteten til data mens du beholder den essensielle informasjonen.
- Anbefalingssystemer : Foreslå produkter, filmer eller innhold til brukere basert på deres historiske oppførsel eller preferanser.
- Temamodellering : Oppdag latente emner i en samling dokumenter.
- Tetthetsestimering : Estimer sannsynlighetstetthetsfunksjonen til data.
- Bilde- og videokomprimering : Reduser mengden lagring som kreves for multimedieinnhold.
- Dataforbehandling : Hjelp med dataforbehandlingsoppgaver som datarensing, imputering av manglende verdier og dataskalering.
- Markedskurvanalyse : Oppdag assosiasjoner mellom produkter.
- Genomisk dataanalyse : Identifiser mønstre eller grupper gener med lignende ekspresjonsprofiler.
- Bildesegmentering : Segmenter bilder til meningsfulle områder.
- Fellesskapsdeteksjon i sosiale nettverk : Identifiser fellesskap eller grupper av individer med lignende interesser eller forbindelser.
- Kundeatferdsanalyse : Avdekke mønstre og innsikt for bedre markedsføring og produktanbefalinger.
- Innholdsanbefaling : Klassifiser og merk innhold for å gjøre det enklere å anbefale lignende varer til brukere.
- Utforskende dataanalyse (EDA) : Utforsk data og få innsikt før du definerer spesifikke oppgaver.
3. Semi-veiledet læring
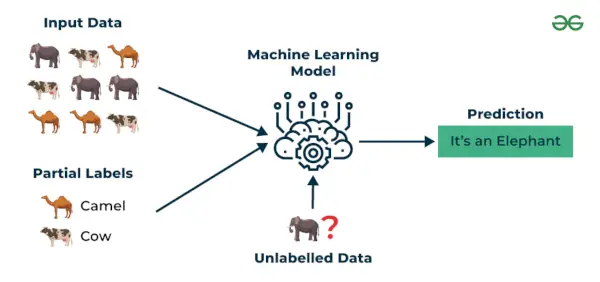
Semi-veiledet læring er en maskinlæringsalgoritme som fungerer mellom overvåket og uten tilsyn læring så den bruker begge deler merket og umerket data. Det er spesielt nyttig når innhenting av merkede data er kostbart, tidkrevende eller ressurskrevende. Denne tilnærmingen er nyttig når datasettet er dyrt og tidkrevende. Semi-veiledet læring velges når merkede data krever ferdigheter og relevante ressurser for å trene eller lære av dem.
Vi bruker disse teknikkene når vi har å gjøre med data som er litt merket og resten store deler av det er umerket. Vi kan bruke teknikkene uten tilsyn til å forutsi etiketter og deretter mate disse etikettene til overvåkede teknikker. Denne teknikken er mest anvendelig i tilfelle av bildedatasett der vanligvis ikke alle bilder er merket.
Semi-veiledet læring
La oss forstå det ved hjelp av et eksempel.
Eksempel : Tenk på at vi bygger en språkoversettelsesmodell, det kan være ressurskrevende å ha merkede oversettelser for hvert setningspar. Det lar modellene lære av merkede og umerkede setningspar, noe som gjør dem mer nøyaktige. Denne teknikken har ført til betydelige forbedringer i kvaliteten på maskinoversettelsestjenester.
Typer semi-veiledede læringsmetoder
Det finnes en rekke ulike semi-veiledede læringsmetoder hver med sine egne egenskaper. Noen av de vanligste inkluderer:
- Grafbasert semi-veiledet læring: Denne tilnærmingen bruker en graf for å representere relasjonene mellom datapunktene. Grafen brukes deretter til å spre etiketter fra de merkede datapunktene til de umerkede datapunktene.
- Utbredelse av etiketter: Denne tilnærmingen forplanter etiketter iterativt fra de merkede datapunktene til de umerkede datapunktene, basert på likhetene mellom datapunktene.
- Samtrening: Denne tilnærmingen trener to forskjellige maskinlæringsmodeller på forskjellige delsett av de umerkede dataene. De to modellene brukes deretter til å merke hverandres spådommer.
- Egentrening: Denne tilnærmingen trener en maskinlæringsmodell på de merkede dataene og bruker deretter modellen til å forutsi etiketter for de umerkede dataene. Modellen blir deretter omskolert på de merkede dataene og de predikerte merkene for de umerkede dataene.
- Generative kontradiktoriske nettverk (GAN) : GAN-er er en type dyplæringsalgoritme som kan brukes til å generere syntetiske data. GAN-er kan brukes til å generere umerkede data for semi-overvåket læring ved å trene to nevrale nettverk, en generator og en diskriminator.
Fordeler med semi-overvåket maskinlæring
- Det fører til bedre generalisering sammenlignet med veiledet læring, da det tar både merket og umerket data.
- Kan brukes på et bredt spekter av data.
Ulemper med semi-overvåket maskinlæring
- Semi-overvåket Metoder kan være mer komplekse å implementere sammenlignet med andre tilnærminger.
- Det krever fortsatt en del merkede data som kanskje ikke alltid er tilgjengelig eller lett å få tak i.
- De umerkede dataene kan påvirke modellens ytelse tilsvarende.
Anvendelser av semi-overvåket læring
Her er noen vanlige bruksområder for semi-veiledet læring:
- Bildeklassifisering og objektgjenkjenning : Forbedre nøyaktigheten til modellene ved å kombinere et lite sett med merkede bilder med et større sett med umerkede bilder.
- Natural Language Processing (NLP) : Forbedre ytelsen til språkmodeller og klassifiserere ved å kombinere et lite sett med merket tekstdata med en enorm mengde umerket tekst.
- Talegjenkjenning: Forbedre nøyaktigheten til talegjenkjenning ved å utnytte en begrenset mengde transkriberte taledata og et mer omfattende sett med umerket lyd.
- Anbefalingssystemer : Forbedre nøyaktigheten til personlig tilpassede anbefalinger ved å supplere et sparsomt sett med interaksjoner mellom brukerelementer (merkede data) med et vell av umerkede brukeratferdsdata.
- Helsetjenester og medisinsk bildediagnostikk : Forbedre medisinsk bildeanalyse ved å bruke et lite sett med merkede medisinske bilder sammen med et større sett med umerkede bilder.
4. Maskinlæring for forsterkning
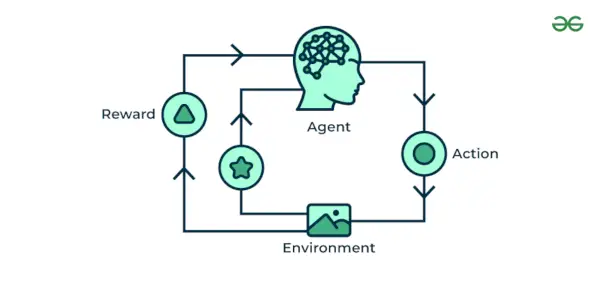
Forsterkende maskinlæring Algoritme er en læringsmetode som samhandler med omgivelsene ved å produsere handlinger og oppdage feil. Prøving, feiling og forsinkelse er de mest relevante egenskapene ved forsterkende læring. I denne teknikken fortsetter modellen å øke ytelsen ved å bruke Reward Feedback for å lære oppførselen eller mønsteret. Disse algoritmene er spesifikke for et bestemt problem, f.eks. Google Self Driving car, AlphaGo hvor en bot konkurrerer med mennesker og til og med seg selv for å få bedre og bedre prestasjoner i Go Game. Hver gang vi mater inn data, lærer de og legger dataene til sin kunnskap, som er treningsdata. Så jo mer den lærer, jo bedre blir den trent og dermed erfaren.
Her er noen av de vanligste forsterkningslæringsalgoritmene:
- Q-læring: Q-learning er en modellfri RL-algoritme som lærer en Q-funksjon, som kartlegger tilstander til handlinger. Q-funksjonen estimerer den forventede belønningen for å utføre en bestemt handling i en gitt tilstand.
- SARSA (State-Action-Reward-State-Action): SARSA er en annen modellfri RL-algoritme som lærer en Q-funksjon. Men i motsetning til Q-learning oppdaterer SARSA Q-funksjonen for handlingen som faktisk ble utført, i stedet for den optimale handlingen.
- Dyp Q-læring : Deep Q-learning er en kombinasjon av Q-learning og deep learning. Deep Q-learning bruker et nevralt nettverk for å representere Q-funksjonen, som lar den lære komplekse forhold mellom tilstander og handlinger.
Maskinlæring for forsterkning
La oss forstå det ved hjelp av eksempler.
Eksempel: Tenk på at du trener en AI agent for å spille et spill som sjakk. Agenten utforsker forskjellige bevegelser og mottar positiv eller negativ tilbakemelding basert på resultatet. Reinforcement Learning finner også applikasjoner der de lærer å utføre oppgaver ved å samhandle med omgivelsene.
Typer forsterkning maskinlæring
Det er to hovedtyper for forsterkende læring:
Positiv forsterkning
- Belønner agenten for å utføre en ønsket handling.
- Oppfordrer agenten til å gjenta oppførselen.
- Eksempler: Å gi en godbit til en hund for å sitte, gi et poeng i et spill for et riktig svar.
Negativ forsterkning
java stack
- Fjerner en uønsket stimulans for å oppmuntre til ønsket atferd.
- Fraråder agenten fra å gjenta oppførselen.
- Eksempler: Slå av en høy summer når en spak trykkes, unngå straff ved å fullføre en oppgave.
Fordeler med maskinlæring for forsterkning
- Den har autonom beslutningstaking som er godt egnet for oppgaver og som kan lære å ta en rekke beslutninger, som robotikk og spilling.
- Denne teknikken foretrekkes for å oppnå langsiktige resultater som er svært vanskelige å oppnå.
- Det brukes til å løse komplekse problemer som ikke kan løses med konvensjonelle teknikker.
Ulemper med forsterkning maskinlæring
- Treningsforsterkning Læringsmidler kan være beregningsmessig kostbare og tidkrevende.
- Forsterkende læring er ikke å foretrekke fremfor å løse enkle problemer.
- Den trenger mye data og mye beregning, noe som gjør den upraktisk og kostbar.
Anvendelser av forsterkningsmaskinlæring
Her er noen bruksområder for forsterkende læring:
- Spilling : RL kan lære agenter å spille spill, også komplekse.
- Robotikk : RL kan lære roboter å utføre oppgaver autonomt.
- Autonome kjøretøy : RL kan hjelpe selvkjørende biler med å navigere og ta avgjørelser.
- Anbefalingssystemer : RL kan forbedre anbefalingsalgoritmer ved å lære brukerpreferanser.
- Helsevesen : RL kan brukes til å optimalisere behandlingsplaner og legemiddeloppdagelse.
- Natural Language Processing (NLP) : RL kan brukes i dialogsystemer og chatbots.
- Finans og handel : RL kan brukes til algoritmisk handel.
- Forsyningskjede og lagerstyring : RL kan brukes til å optimalisere forsyningskjeden.
- Energiledelse : RL kan brukes til å optimalisere energiforbruket.
- AI-spill : RL kan brukes til å lage mer intelligente og adaptive NPC-er i videospill.
- Adaptive personlige assistenter : RL kan brukes til å forbedre personlige assistenter.
- Virtual Reality (VR) og Augmented Reality (AR): RL kan brukes til å skape oppslukende og interaktive opplevelser.
- Industriell kontroll : RL kan brukes til å optimalisere industrielle prosesser.
- utdanning : RL kan brukes til å lage adaptive læringssystemer.
- Jordbruk : RL kan brukes til å optimalisere landbruksdriften.
Må sjekke, vår detaljerte artikkel om : Maskinlæringsalgoritmer
Konklusjon
Som konklusjon tjener hver type maskinlæring sitt eget formål og bidrar til den overordnede rollen i utviklingen av forbedrede dataprediksjonsevner, og den har potensial til å endre ulike bransjer som Datavitenskap . Det hjelper med å håndtere massiv dataproduksjon og administrasjon av datasettene.
Typer maskinlæring – vanlige spørsmål
1. Hva er utfordringene i veiledet læring?
Noen av utfordringene i veiledet læring inkluderer hovedsakelig å håndtere klasseubalanser, merkede data av høy kvalitet og unngå overfitting der modeller gir dårlige resultater på sanntidsdata.
2. Hvor kan vi anvende veiledet læring?
Overvåket læring brukes ofte til oppgaver som å analysere spam-e-poster, bildegjenkjenning og sentimentanalyse.
3. Hvordan ser fremtiden for maskinlæring ut?
Maskinlæring som fremtidsutsikter kan fungere på områder som vær- eller klimaanalyse, helsesystemer og autonom modellering.
4. Hva er de forskjellige typene maskinlæring?
Det er tre hovedtyper av maskinlæring:
- Veiledet læring
- Uovervåket læring
- Forsterkende læring
5. Hva er de vanligste maskinlæringsalgoritmene?
Noen av de vanligste maskinlæringsalgoritmene inkluderer:
- Lineær regresjon
- Logistisk regresjon
- Støtte vektormaskiner (SVM)
- K-nærmeste naboer (KNN)
- Beslutningstrær
- Tilfeldige skoger
- Kunstige nevrale nettverk